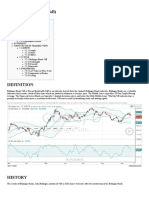
You might also like
- SQL Server Column Level Encryption Example Using Symmetric KeysDocument8 pagesSQL Server Column Level Encryption Example Using Symmetric KeysMian AlmasNo ratings yet
- Forex Hydra StrategyDocument9 pagesForex Hydra Strategyrachid100% (1)
- ELM Optimization Done RightDocument12 pagesELM Optimization Done RightKeith SoongNo ratings yet
- Price Action Scalping 2021Document14 pagesPrice Action Scalping 2021Omar GarcíaNo ratings yet
- Algo Trader DocumentationDocument48 pagesAlgo Trader DocumentationRoberto BarberaNo ratings yet
- PYTHON Interview QuestionDocument3 pagesPYTHON Interview QuestionOjas DhoneNo ratings yet
- Basic Guide To Support and Resistance Trading5Document10 pagesBasic Guide To Support and Resistance Trading5fuzzychanNo ratings yet
- Algorithmic Trading CourseDocument3 pagesAlgorithmic Trading CourseRODRIGO TROCONISNo ratings yet
- Beginners Guide To Automated Trading in ThinkOrSwim TOS IndicatorsDocument21 pagesBeginners Guide To Automated Trading in ThinkOrSwim TOS IndicatorsBenNo ratings yet
- 27 Rules For Forex Trading: A Primer For All InvestorsDocument48 pages27 Rules For Forex Trading: A Primer For All InvestorsEhsan DarwishmoqaddamNo ratings yet
- Preview Java J2ee BookDocument47 pagesPreview Java J2ee Bookdheepa100% (1)
- SQL Cheatsheet Zero To Mastery V1.01 PDFDocument20 pagesSQL Cheatsheet Zero To Mastery V1.01 PDFJoão Victor Machado Da CruzNo ratings yet
- Free Price Action Trading PDF GuideDocument20 pagesFree Price Action Trading PDF GuideRadical NtukNo ratings yet
- Five Good Strategies For TradingDocument15 pagesFive Good Strategies For TradingJeeva JothyNo ratings yet
- Traders CodeDocument7 pagesTraders CodeHarshal Kumar ShahNo ratings yet
- The Ultimate Handbook Forex Trading BasiDocument59 pagesThe Ultimate Handbook Forex Trading Basisandeep shuklaNo ratings yet
- Turn Your Trading Easy With Automated TR PDFDocument1 pageTurn Your Trading Easy With Automated TR PDFtico ortiz aguilarNo ratings yet
- Bollinger Bands %B (%B) - TradingView DocumentationDocument5 pagesBollinger Bands %B (%B) - TradingView DocumentationFinTNo ratings yet
- Step by Step Manual: Preparing Yourself To The Path of Trading MasteryDocument7 pagesStep by Step Manual: Preparing Yourself To The Path of Trading Masteryshares_leoneNo ratings yet
- Create A Managed Trading Strategy With MetaTraderDocument15 pagesCreate A Managed Trading Strategy With MetaTraderDeclan FallonNo ratings yet
- Plan Your Trading: Brought To You byDocument41 pagesPlan Your Trading: Brought To You byAfrim Tonuzi100% (1)
- TradeFoxx Automated Trading Guide SystemDocument12 pagesTradeFoxx Automated Trading Guide SystemtonyNo ratings yet
- 3 Rules To Follow in Intraday TradingDocument2 pages3 Rules To Follow in Intraday TradingSumitava PaulNo ratings yet
- Swing Trading Bootcamp For Traders & Investors (NEW 2021)Document10 pagesSwing Trading Bootcamp For Traders & Investors (NEW 2021)mytemp_01No ratings yet
- Quantitative AnalystDocument12 pagesQuantitative AnalystAnonymous 3fJkf2Vvh0% (1)
- How To Create Your Own Option Buying SystemDocument20 pagesHow To Create Your Own Option Buying SystemSashwat ShresthNo ratings yet
- Decision Point Trading SystemDocument3 pagesDecision Point Trading SystemVinayak MegharajNo ratings yet
- Trading PlanDocument1 pageTrading PlanAngel AngiaNo ratings yet
- Switztrader Trading BookDocument57 pagesSwitztrader Trading BookJoseph ChukwuNo ratings yet
- Trading SystemDocument8 pagesTrading Systemvijay7775303No ratings yet
- Auto Trading BotscriptDocument2 pagesAuto Trading BotscriptSsunnelNo ratings yet
- Options StrategiesDocument26 pagesOptions StrategiesPrasad VeesamshettyNo ratings yet
- Andrew Young Expert Advisor Programming Creating Automated Trading SystemsDocument212 pagesAndrew Young Expert Advisor Programming Creating Automated Trading SystemsPlamen KozhuharovNo ratings yet
- Vol-7 Futures Trading Guide PDFDocument26 pagesVol-7 Futures Trading Guide PDFUtkarshNo ratings yet
- A Risk Management Strategy Used in Limiting or Offsetting Probability of Loss From Fluctuations in The Prices of CommoditiesDocument7 pagesA Risk Management Strategy Used in Limiting or Offsetting Probability of Loss From Fluctuations in The Prices of CommoditiesHarshad PawarNo ratings yet
- StrategyQuant Help PDFDocument130 pagesStrategyQuant Help PDFBe SauNo ratings yet
- Is Day Trading ProfitableDocument3 pagesIs Day Trading ProfitableCesar De JesusNo ratings yet
- Crypto TradingDocument12 pagesCrypto TradingJames WaweruNo ratings yet
- Forex Systems: Types of Forex Trading SystemDocument35 pagesForex Systems: Types of Forex Trading SystemalypatyNo ratings yet
- Trading Bitcoin CandlesDocument12 pagesTrading Bitcoin CandlesSean SmythNo ratings yet
- Bear Put Spread: Bearish Vertical Spread Options StrategyDocument4 pagesBear Put Spread: Bearish Vertical Spread Options StrategyjaiswalsnehaNo ratings yet
- 10 Essentials To Keep You Busy Until You Master The MarketDocument4 pages10 Essentials To Keep You Busy Until You Master The MarketSoh Tiong HumNo ratings yet
- The Forex Executive - Is It Any Good?Document10 pagesThe Forex Executive - Is It Any Good?Ateeque MohdNo ratings yet
- 18 Fibonacci ExtensionDocument4 pages18 Fibonacci ExtensionRui AlmeidaNo ratings yet
- Forex Ghost Scalper StrategyDocument6 pagesForex Ghost Scalper StrategyDon Mell0% (1)
- Candlesticks and PatternsDocument27 pagesCandlesticks and PatternsBenoît VONSA100% (1)
- 15 Minutes TradingDocument26 pages15 Minutes TradingPanji WirayudhaNo ratings yet
- True Money ManagementDocument12 pagesTrue Money Managementeldosrajan100% (2)
- Pro Vsa Ea Guide ENGDocument16 pagesPro Vsa Ea Guide ENGpague por verNo ratings yet
- Algorithmic Trading 2023apDocument4 pagesAlgorithmic Trading 2023apAnouar HarourateNo ratings yet
- My Successful Intraday Setup PDFDocument4 pagesMy Successful Intraday Setup PDFS P DURAISAMY MANINo ratings yet
- Training and DevelopmentDocument58 pagesTraining and DevelopmentTahseen RazaNo ratings yet
- Power BI Training DeckDocument41 pagesPower BI Training DeckNessaty KoubeNo ratings yet
- Daytrade Master Indicator: Entry SetupDocument7 pagesDaytrade Master Indicator: Entry SetupyaxaNo ratings yet
- Intro Algo ExcerptDocument18 pagesIntro Algo ExcerptvirtualrealNo ratings yet
- The Empowered Forex Trader: Strategies to Transform Pains into GainsFrom EverandThe Empowered Forex Trader: Strategies to Transform Pains into GainsNo ratings yet
- The Forex Options Course: A Self-Study Guide to Trading Currency OptionsFrom EverandThe Forex Options Course: A Self-Study Guide to Trading Currency OptionsNo ratings yet
- BPCDocument3 pagesBPCPavel TsarevskyNo ratings yet
- AtaquesDocument6 pagesAtaquesJuan JoseNo ratings yet
- Dynamic Memory Allocation: Prof. Nilesh GambhavaDocument14 pagesDynamic Memory Allocation: Prof. Nilesh GambhavaJeel PatelNo ratings yet
- Jeep TJ 1997-2006 Wrangler - Service Manual - STJ 21 Transmision y Caja de CDocument135 pagesJeep TJ 1997-2006 Wrangler - Service Manual - STJ 21 Transmision y Caja de CGiovanny F. Camacho0% (3)
- 3D TransformationsDocument11 pages3D TransformationsMichelle SmithNo ratings yet
- PROB2006S - Lecture-03-Conditional Probability, Total Probability Theorem, Bayes RuleDocument23 pagesPROB2006S - Lecture-03-Conditional Probability, Total Probability Theorem, Bayes RuleVishal GargNo ratings yet
- Econ3150 v12 Note01 PDFDocument6 pagesEcon3150 v12 Note01 PDFRitaSilabanNo ratings yet
- IOT and GSM Integrated Multi Purpose Security SystemDocument4 pagesIOT and GSM Integrated Multi Purpose Security SystemSowmya SangaNo ratings yet
- Senior Accountant Auditor MBA in Houston TX Resume Rochelle ButlerDocument3 pagesSenior Accountant Auditor MBA in Houston TX Resume Rochelle ButlerRochelleButlerNo ratings yet
- 8051 MicrocontrollerDocument76 pages8051 MicrocontrollerRohan TomarNo ratings yet
- Ln. 3 - Brief Overview of PythonDocument26 pagesLn. 3 - Brief Overview of PythonAbel VarugheseNo ratings yet
- DASGIP E-Flyer Application PH QualityControl Dairy enDocument2 pagesDASGIP E-Flyer Application PH QualityControl Dairy enNikunj GadhiyaNo ratings yet
- Setup and User Guide: Mediaaccess Tg788Vn V2Document159 pagesSetup and User Guide: Mediaaccess Tg788Vn V2Fernando GonzálezNo ratings yet
- DM LabDocument101 pagesDM LabTamilvanan SNo ratings yet
- Jasco Spectra Manager ReferenceDocument1 pageJasco Spectra Manager Referencec3745220No ratings yet
- Sample User Profile QuestionnaireDocument6 pagesSample User Profile QuestionnairemuzammilsiddiquiNo ratings yet
- SDS2 7.1-Assorted Tools PDFDocument94 pagesSDS2 7.1-Assorted Tools PDFwayne6088No ratings yet
- D.lambert ExecutiveSummary SCM-bookDocument24 pagesD.lambert ExecutiveSummary SCM-bookMauricio Portillo G.No ratings yet
- An Exploration On Artificial Intelligence Application: From Security, Privacy and Ethic PerspectiveDocument5 pagesAn Exploration On Artificial Intelligence Application: From Security, Privacy and Ethic PerspectiveDavid SilveraNo ratings yet
- VFC Manual PDFDocument28 pagesVFC Manual PDFFikret DavudovNo ratings yet
- DSE4210 DSE4220 Operators Manual PDFDocument42 pagesDSE4210 DSE4220 Operators Manual PDFLeo BurnsNo ratings yet
- Siu Data ExampleDocument8 pagesSiu Data ExampleLahir Untuk MenangNo ratings yet
- MC Unit-4Document44 pagesMC Unit-4ch MahendraNo ratings yet
- Research Papers On Network Security AttacksDocument6 pagesResearch Papers On Network Security AttackshbkgbsundNo ratings yet
- Signal Analysis: 1.1 Analogy of Signals With VectorsDocument29 pagesSignal Analysis: 1.1 Analogy of Signals With VectorsRamachandra ReddyNo ratings yet
- Dl2003del040xxj0115 PDFDocument1 pageDl2003del040xxj0115 PDFAnuj PratapNo ratings yet
- 20KVA Hipulse D - SIMHADRI POWER LTD.Document36 pages20KVA Hipulse D - SIMHADRI POWER LTD.seil iexNo ratings yet
- DynaDoctor - For - VRF - Operation - Manual v1.3Document67 pagesDynaDoctor - For - VRF - Operation - Manual v1.3Luis Gerardo Almanza LlanosNo ratings yet
- Minas-A5-2 CTLG eDocument156 pagesMinas-A5-2 CTLG eLêQuangĐạoNo ratings yet
- Abinitio Ace: (A I Application Configuration Environment)Document16 pagesAbinitio Ace: (A I Application Configuration Environment)gade kotiNo ratings yet