You might also like
- Momi Documentation: Release 2.0.1Document29 pagesMomi Documentation: Release 2.0.1TezadeLicentaNo ratings yet
- Investigations CriminalDocument88 pagesInvestigations CriminalTezadeLicentaNo ratings yet
- PoliticaDocument14 pagesPoliticaTezadeLicentaNo ratings yet
- Bittersweet Cookies. Some Security and Privacy ConsiderationsDocument16 pagesBittersweet Cookies. Some Security and Privacy ConsiderationsStefano BendandiNo ratings yet
- WEF Human Capital Report 2015 PDFDocument319 pagesWEF Human Capital Report 2015 PDFTezadeLicentaNo ratings yet
- ManaDocument14 pagesManaTezadeLicentaNo ratings yet
- SnailDocument25 pagesSnailBolarinwaNo ratings yet
- Uha Bcde GHJ: Air Assisted Lances Single Orifice NozzlesDocument2 pagesUha Bcde GHJ: Air Assisted Lances Single Orifice NozzlesraamonikNo ratings yet
- UtruDocument67 pagesUtruTezadeLicentaNo ratings yet
- LolarDocument6 pagesLolarTezadeLicentaNo ratings yet
- Koker ThermostatDocument18 pagesKoker ThermostatTezadeLicentaNo ratings yet
- KuklaDocument15 pagesKuklaTezadeLicentaNo ratings yet
- HororDocument11 pagesHororTezadeLicentaNo ratings yet
- High-speed electronic eyelet buttonholer with 2,500 spmDocument6 pagesHigh-speed electronic eyelet buttonholer with 2,500 spmTezadeLicentaNo ratings yet
- Eadweard MuybridgeDocument9 pagesEadweard MuybridgeTezadeLicentaNo ratings yet
- DM StatDocument7 pagesDM StatlxangelusxlNo ratings yet
- GugDocument56 pagesGugTezadeLicentaNo ratings yet
- Bernhard Jucker: Head of Power Products Division Member of The Group Executive Committee of ABB LTD, SwitzerlandDocument1 pageBernhard Jucker: Head of Power Products Division Member of The Group Executive Committee of ABB LTD, SwitzerlandTezadeLicentaNo ratings yet
- LolaDocument12 pagesLolaTezadeLicentaNo ratings yet
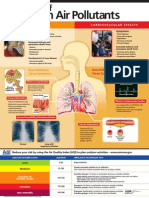
- Effects Of: Common Air PollutantsDocument1 pageEffects Of: Common Air PollutantsTezadeLicentaNo ratings yet
- PopaDocument292 pagesPopaTezadeLicentaNo ratings yet
- ! Sustainable Energy Synopsis10Document10 pages! Sustainable Energy Synopsis10quikjipNo ratings yet
- FuturesDocument16 pagesFuturesTezadeLicentaNo ratings yet
- Self-I-Dentity Through Ho'oponoponoDocument5 pagesSelf-I-Dentity Through Ho'oponoponoTanya McCracken100% (1)
- How Science WorksDocument39 pagesHow Science Worksdhani_isNo ratings yet
- SchemaDocument6 pagesSchemaTezadeLicentaNo ratings yet
- FasDocument6 pagesFasTezadeLicentaNo ratings yet
- Karlos CastanDocument3 pagesKarlos CastanTezadeLicentaNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- HFRPADocument227 pagesHFRPAMitzu Mariuss100% (2)
- RAB & Spek LiftDocument2 pagesRAB & Spek Liftfatwa1985No ratings yet
- B - E / B - T E C H (Full-Time) D E G R E E Examinations, April/May 2012Document2 pagesB - E / B - T E C H (Full-Time) D E G R E E Examinations, April/May 2012krithikgokul selvamNo ratings yet
- Paper Test Critical ThinkingDocument10 pagesPaper Test Critical Thinkingandrea217No ratings yet
- Introduction and operating system structure syllabusDocument29 pagesIntroduction and operating system structure syllabusRadhika BadbadeNo ratings yet
- EE4534 Modern Distribution Systems With Renewable Resources - OBTLDocument7 pagesEE4534 Modern Distribution Systems With Renewable Resources - OBTLAaron TanNo ratings yet
- Quantitative Corpus BasedDocument6 pagesQuantitative Corpus Basedahmn67No ratings yet
- An Introduction To Computer Simulation Methods: Harvey Gould, Jan Tobochnik, and Wolfgang Christian July 31, 2005Document8 pagesAn Introduction To Computer Simulation Methods: Harvey Gould, Jan Tobochnik, and Wolfgang Christian July 31, 2005Maria Juliana Ruiz MantillaNo ratings yet
- CV Pak WonoDocument2 pagesCV Pak WonoKharismaNo ratings yet
- Azenabor - Oruka's Philosophic SagacityDocument18 pagesAzenabor - Oruka's Philosophic SagacityestifanostzNo ratings yet
- Linear Algebra and its Applications: Functions of a matrix and Krylov matrices聻Document16 pagesLinear Algebra and its Applications: Functions of a matrix and Krylov matrices聻krrrNo ratings yet
- Pelatihan Kader: Lampiran Uji StatistikDocument2 pagesPelatihan Kader: Lampiran Uji StatistikSiti Hidayatul FitriNo ratings yet
- Master'S Thesis: Simulation of An Underground Haulage System, Renström Mine, Boliden MineralDocument76 pagesMaster'S Thesis: Simulation of An Underground Haulage System, Renström Mine, Boliden MineralJosé Carlos Bustamante MoralesNo ratings yet
- SBC Code 301Document350 pagesSBC Code 301Marwan Mokhadder100% (6)
- Grammar BasicsDocument24 pagesGrammar Basicspreetie1027No ratings yet
- H 1000 5104 05 B - SP25M - UgDocument145 pagesH 1000 5104 05 B - SP25M - UgBruno MauNo ratings yet
- MECHANICAL DESIGN ENGINEERING - Geometrical Dimensioning and Tolerancing - What Is The CYLINDRICITY Tolerance?Document7 pagesMECHANICAL DESIGN ENGINEERING - Geometrical Dimensioning and Tolerancing - What Is The CYLINDRICITY Tolerance?Sathya DharanNo ratings yet
- Instructions For Using WinplotDocument38 pagesInstructions For Using WinplotClaudia MuñozNo ratings yet
- 4.0L Cec System: 1988 Jeep CherokeeDocument17 pages4.0L Cec System: 1988 Jeep CherokeefredericdiNo ratings yet
- Introduction To C Programming: S.V.Jansi RaniDocument14 pagesIntroduction To C Programming: S.V.Jansi RanisudhanNo ratings yet
- Kubota Front Loader La 211Document29 pagesKubota Front Loader La 211Mark Dubravec40% (5)
- 5957-Pan Flute Tone RangesDocument1 page5957-Pan Flute Tone Rangesdaniel_gheoldus5867No ratings yet
- IUPAC Naming by Aravind AroraDocument30 pagesIUPAC Naming by Aravind Aroratanish gehlotNo ratings yet
- Murakami - Analysis of Stress Intensity Factors of Modes I, II and III For Inclined Surface Cracks of Arbitrary ShapeDocument14 pagesMurakami - Analysis of Stress Intensity Factors of Modes I, II and III For Inclined Surface Cracks of Arbitrary ShapeDavid C HouserNo ratings yet
- Question Bank AAIDocument4 pagesQuestion Bank AAIANANYA VNo ratings yet
- RNC2600 DatasheetDocument2 pagesRNC2600 DatasheetShaikh Tariq100% (1)
- Types of ImplicatureDocument4 pagesTypes of ImplicatureSaman Khan100% (3)
- Physical behavior of gases explained by kinetic theory and gas lawsDocument12 pagesPhysical behavior of gases explained by kinetic theory and gas lawsPAUL KOLERENo ratings yet
- 01 AutoPIPE Vessel Fundamentals Introduction PPTDocument10 pages01 AutoPIPE Vessel Fundamentals Introduction PPTInamullah KhanNo ratings yet
- 10.-EPRI-NMAC - HVAC Testing, Adjunsting and Balancing Guideline PDFDocument224 pages10.-EPRI-NMAC - HVAC Testing, Adjunsting and Balancing Guideline PDFaldeanucuNo ratings yet