You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Beta Anomaly An Ex-Ante Tail RiskDocument104 pagesBeta Anomaly An Ex-Ante Tail RiskDaniel Lee Eisenberg JacobsNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Theophilus Capital Against: Fisk Labor1Document9 pagesTheophilus Capital Against: Fisk Labor1Daniel Lee Eisenberg Jacobs100% (1)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Claudia Jones Nuclear TestingDocument25 pagesClaudia Jones Nuclear TestingDaniel Lee Eisenberg JacobsNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Why The Euro Will Rival The Dollar PDFDocument25 pagesWhy The Euro Will Rival The Dollar PDFDaniel Lee Eisenberg JacobsNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Conference Group For Central European History of The American Historical AssociationDocument9 pagesConference Group For Central European History of The American Historical AssociationDaniel Lee Eisenberg JacobsNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
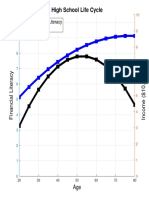
- High School Life Cycle: Financial Literacy IncomeDocument1 pageHigh School Life Cycle: Financial Literacy IncomeDaniel Lee Eisenberg JacobsNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Continuity Change State of Process of Task ofDocument1 pageContinuity Change State of Process of Task ofDaniel Lee Eisenberg JacobsNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Gpebook PDFDocument332 pagesGpebook PDFDaniel Lee Eisenberg JacobsNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Karl Kautsky Republic and Social Democra PDFDocument4 pagesKarl Kautsky Republic and Social Democra PDFDaniel Lee Eisenberg JacobsNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- 1st International: Djacobs November 2020Document5 pages1st International: Djacobs November 2020Daniel Lee Eisenberg JacobsNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Borel Sets PDFDocument181 pagesBorel Sets PDFDaniel Lee Eisenberg Jacobs100% (1)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Individualization of Robo-AdviceDocument8 pagesIndividualization of Robo-AdviceDaniel Lee Eisenberg JacobsNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Cover FERCDocument1 pageCover FERCDaniel Lee Eisenberg JacobsNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Saving Behavior of Public Vocational High School Students of Business and Management Program in Semarang SitiDocument8 pagesThe Saving Behavior of Public Vocational High School Students of Business and Management Program in Semarang SitiDaniel Lee Eisenberg JacobsNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Teach-In: Government of The People, by The People, For The PeopleDocument24 pagesTeach-In: Government of The People, by The People, For The PeopleDaniel Lee Eisenberg JacobsNo ratings yet
- Necessary and Sufficient Conditions For Dynamic OptimizationDocument18 pagesNecessary and Sufficient Conditions For Dynamic OptimizationDaniel Lee Eisenberg JacobsNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Bank Loan Loss ProvisioningDocument17 pagesBank Loan Loss ProvisioningDaniel Lee Eisenberg JacobsNo ratings yet
- Simple BeamerDocument25 pagesSimple BeamerDaniel Lee Eisenberg JacobsNo ratings yet
- Ece120 Notes PDFDocument150 pagesEce120 Notes PDFMarcus HoangNo ratings yet
- Program Enrollment Test Quiz - WorldQuant University MSC FINANCEDocument26 pagesProgram Enrollment Test Quiz - WorldQuant University MSC FINANCEprakashkumarsenNo ratings yet
- Mass Lumping SEM PreprintDocument57 pagesMass Lumping SEM PreprintSree SasthaNo ratings yet
- Maths Important QuestionsDocument3 pagesMaths Important QuestionsSteve ackinsNo ratings yet
- End of Course Algebra I: Form M0117, CORE 1Document36 pagesEnd of Course Algebra I: Form M0117, CORE 1faithinhim7515No ratings yet
- Paulo Franca C++ - No Experience Required PDFDocument503 pagesPaulo Franca C++ - No Experience Required PDFJohn CareyNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Introduction To Magma: Lecture and Hands On Session at UNCG 2016Document51 pagesIntroduction To Magma: Lecture and Hands On Session at UNCG 2016Darwin Gregorio Villar SalinasNo ratings yet
- fp1 NotesDocument82 pagesfp1 NotesclstefNo ratings yet
- SMDocument176 pagesSMjcurol4No ratings yet
- SOC330 Chapter 3Document6 pagesSOC330 Chapter 3Accounstoppables CuteNo ratings yet
- 3 - Siemens Open Library - Example Object Configuration V1.4Document24 pages3 - Siemens Open Library - Example Object Configuration V1.4RafaelNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- A Sudoku Problem Formulated As An LP - PuLP v1.4.6 DocumentationDocument3 pagesA Sudoku Problem Formulated As An LP - PuLP v1.4.6 DocumentationRamez SafwatNo ratings yet
- Saint Vincent de Paul Diocesan College: Teaching GuideDocument32 pagesSaint Vincent de Paul Diocesan College: Teaching GuideJessa Edulan100% (1)
- Activity No. 2 Integrals Yielding Inverse Trigonometric FunctionsDocument3 pagesActivity No. 2 Integrals Yielding Inverse Trigonometric FunctionsrymacNo ratings yet
- Lingo Users ManualDocument662 pagesLingo Users ManualMiziphi PpmNo ratings yet
- Mat 139 Review CommentsDocument8 pagesMat 139 Review CommentsAnonymous 24Gh7afdXrNo ratings yet
- Lecture 1, Part 3: Training A Classifier: Roger GrosseDocument11 pagesLecture 1, Part 3: Training A Classifier: Roger GrosseShamil shihab pkNo ratings yet
- 4.01 Random Variables & Probability DistributionsDocument2 pages4.01 Random Variables & Probability DistributionsKavya GopakumarNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Learning Module in General Mathematics 11: Quarter 1 - Week 2Document10 pagesLearning Module in General Mathematics 11: Quarter 1 - Week 2Rostelito CatalonNo ratings yet
- SUMMATIVE TEST NO.1 Math 10 Second Quarter 2022-2023Document2 pagesSUMMATIVE TEST NO.1 Math 10 Second Quarter 2022-2023Justiniano SalicioNo ratings yet
- Soft CircuitsDocument407 pagesSoft CircuitsHonorino García FernándezNo ratings yet
- Grade 11 - Math DLL Week 3Document5 pagesGrade 11 - Math DLL Week 3Nikko PatunganNo ratings yet
- Finding The Domain and Range CDocument2 pagesFinding The Domain and Range CTarush GautamNo ratings yet
- Pseudo Code 1Document6 pagesPseudo Code 1Michelin FernandezNo ratings yet
- BTechSyllabus EC PDFDocument140 pagesBTechSyllabus EC PDFHHNo ratings yet
- Languages and Machines (Thomas A. Sudkamp)Document574 pagesLanguages and Machines (Thomas A. Sudkamp)Amy100% (3)
- CV Module 1Document166 pagesCV Module 1Yogesh GargNo ratings yet
- FBD EditorDocument14 pagesFBD EditorTuấn Lê QuangNo ratings yet
- Section 2.4 - Transformations of GraphsDocument23 pagesSection 2.4 - Transformations of GraphsmohamedNo ratings yet
- Year 10 Accelerated Program 2023Document14 pagesYear 10 Accelerated Program 2023Ralph Rezin MooreNo ratings yet