You might also like
- Modern Economic Problems Economics Volume IIFrom EverandModern Economic Problems Economics Volume IIRating: 5 out of 5 stars5/5 (1)
- CBSE XII Economics NotesDocument165 pagesCBSE XII Economics NoteschehalNo ratings yet
- Question Bank: Short Answer QuestionsDocument29 pagesQuestion Bank: Short Answer QuestionsPayal GoswamiNo ratings yet
- Inclusive GrowthDocument45 pagesInclusive GrowthPRUDHVINo ratings yet
- Human Capital FormationDocument14 pagesHuman Capital FormationKaustubh Chintalapudi100% (1)
- EconomicsDocument90 pagesEconomicsapi-514969128No ratings yet
- (James M. Henderson and Richard E. Quandt) Microec PDFDocument304 pages(James M. Henderson and Richard E. Quandt) Microec PDFMohammad Baqir100% (1)
- Ch.4 - Measurement of National Income ( (Macro Economics - 12th Class) ) Green BookDocument120 pagesCh.4 - Measurement of National Income ( (Macro Economics - 12th Class) ) Green BookMayank Mall0% (1)
- Balance of PaymentDocument26 pagesBalance of Paymentnitan4zaara100% (3)
- 11 Business Studies Term - 1 MCQsDocument102 pages11 Business Studies Term - 1 MCQsVaSuDeVaNNo ratings yet
- Economics Class 12 Notes, Ebook - Solved Questions For Board Exams - Free PDF DownloadDocument100 pagesEconomics Class 12 Notes, Ebook - Solved Questions For Board Exams - Free PDF DownloadRobo Buddy100% (1)
- Class-12, Economics, CH-2 Indian Economy 1950-1990 (Ied)Document5 pagesClass-12, Economics, CH-2 Indian Economy 1950-1990 (Ied)Aastha SagarNo ratings yet
- Detailed Syllabus ST Xaviers Kolkata Eco HonsDocument20 pagesDetailed Syllabus ST Xaviers Kolkata Eco HonsSarbartho MukherjeeNo ratings yet
- 1 Acc Papers Class 12 and SolutionDocument18 pages1 Acc Papers Class 12 and SolutionImp DocsNo ratings yet
- Economics Project Sem2Document41 pagesEconomics Project Sem2madhuri50% (2)
- Changes in CBSE Economics Paper by Priti ManglaDocument9 pagesChanges in CBSE Economics Paper by Priti ManglaBook Spaces100% (4)
- Economics Project XiiDocument11 pagesEconomics Project XiiKriti SinghNo ratings yet
- Economic Question Bank With Solutions PDFDocument172 pagesEconomic Question Bank With Solutions PDFlimuNo ratings yet
- 11 ECO 08 Introduction To Index NumberDocument4 pages11 ECO 08 Introduction To Index NumberFebin Kurian FrancisNo ratings yet
- 11 Economics Statistics For Economics Introduction Notes and VideoDocument5 pages11 Economics Statistics For Economics Introduction Notes and VideoOs DaNo ratings yet
- Economics Project 2021-22 - Tarun Robins Xii C 3Document37 pagesEconomics Project 2021-22 - Tarun Robins Xii C 3SkottayyNo ratings yet
- Xii EconomicsDocument21 pagesXii EconomicsHarsh Sethia100% (1)
- Class 12th Economic Macro NotesDocument134 pagesClass 12th Economic Macro NotesKhusi Agrawal100% (1)
- Ugc Net EconomicsDocument499 pagesUgc Net EconomicsRavi DubeyNo ratings yet
- Subhash Dey's IED Textbook 2024-25 Sample PDFDocument46 pagesSubhash Dey's IED Textbook 2024-25 Sample PDFravinderd2003No ratings yet
- Cbse Sample Papers For Class 12 Economics With Solution PDFDocument19 pagesCbse Sample Papers For Class 12 Economics With Solution PDFniharikaNo ratings yet
- Accountancy Project Book - 47thDocument14 pagesAccountancy Project Book - 47thHimanshu Dadhich0% (1)
- Full Syllabus ECONOMICS XII CBSEDocument231 pagesFull Syllabus ECONOMICS XII CBSEShubdhi94100% (1)
- Dey'S - Sample PDF - BST-XII Exam Handbook Term-I - 2021-22Document62 pagesDey'S - Sample PDF - BST-XII Exam Handbook Term-I - 2021-22Bhagya aggarwalNo ratings yet
- CLASS 12 ECO PROJECT On Self Help GroupDocument34 pagesCLASS 12 ECO PROJECT On Self Help GroupHarshNo ratings yet
- XII - Project Work in EconomicsDocument15 pagesXII - Project Work in EconomicsDaksh SharmaNo ratings yet
- Format - Summer Training Project Report Format.Document8 pagesFormat - Summer Training Project Report Format.vershaNo ratings yet
- CBSE Class 9 Economics Chapter 2 Notes - People As ResourceDocument5 pagesCBSE Class 9 Economics Chapter 2 Notes - People As ResourceDeepak GuptaNo ratings yet
- B.A. Hons Economics Readings 2012 13Document13 pagesB.A. Hons Economics Readings 2012 13Puja KumariNo ratings yet
- Ugc Net Gradeup Playlist ListDocument3 pagesUgc Net Gradeup Playlist ListDaffodilNo ratings yet
- Xii Economics Excellence Series, Ziet BBSRDocument296 pagesXii Economics Excellence Series, Ziet BBSRnagartanishq2No ratings yet
- Shri. K.M. Savjani & Smt. K.K. Savjani B.B.A./B.C.A College, VeravalDocument26 pagesShri. K.M. Savjani & Smt. K.K. Savjani B.B.A./B.C.A College, VeravalKaran DalkiNo ratings yet
- Nature and Scope of Agricultural EconomicsDocument6 pagesNature and Scope of Agricultural EconomicsDorisNo ratings yet
- Domestic Territory and Normal ResidentDocument10 pagesDomestic Territory and Normal Residentnaveen kumarNo ratings yet
- T.R. Jain and V.K. Ohri Solutions For Economics CBSE Class 11 Commerce, Chapter 7 Frequency Diagrams, Histograms, Polygon and Ogive - TopperLearningDocument22 pagesT.R. Jain and V.K. Ohri Solutions For Economics CBSE Class 11 Commerce, Chapter 7 Frequency Diagrams, Histograms, Polygon and Ogive - TopperLearningAshok Kumar67% (3)
- 12 Economics Notes Macro Ch04 Government Budget and The EconomyDocument7 pages12 Economics Notes Macro Ch04 Government Budget and The EconomyvatsadbgNo ratings yet
- Chapter 1 - Introduction Microeconomics Notes: - Economy - EconomicsDocument5 pagesChapter 1 - Introduction Microeconomics Notes: - Economy - EconomicsShivam KumarNo ratings yet
- CH 1 - Circular Flow of IncomeDocument14 pagesCH 1 - Circular Flow of Incomediscordnitroop123No ratings yet
- Eco Mains Strategy Riju BafnaDocument4 pagesEco Mains Strategy Riju BafnaJigisha SinghNo ratings yet
- CBSE Supporting Material Economics Class 12 2013Document152 pagesCBSE Supporting Material Economics Class 12 2013ChandraMENo ratings yet
- UGC NET Economics Paper 2 Notes - Last Minute Revision Series - Libgen - Li PDFDocument111 pagesUGC NET Economics Paper 2 Notes - Last Minute Revision Series - Libgen - Li PDFFinmonkey. InNo ratings yet
- 200 Questions of Economics With Answers Including 8 Chapters..Document43 pages200 Questions of Economics With Answers Including 8 Chapters..Abhijit KonwarNo ratings yet
- 10 Joint Sector in IndiaDocument17 pages10 Joint Sector in IndiaAkash JainNo ratings yet
- Exam Handbook: EconomicsDocument50 pagesExam Handbook: EconomicsThe Unknown vlogger100% (1)
- B.ST - STUDY MATERIAL KVS 2021-22 Term 1Document168 pagesB.ST - STUDY MATERIAL KVS 2021-22 Term 1Kalpesh WaghmareNo ratings yet
- CA Foundation MTP 2020 Paper 4 QuesDocument15 pagesCA Foundation MTP 2020 Paper 4 QuesKanchan AggarwalNo ratings yet
- Xii BST Support MaterialDocument154 pagesXii BST Support MaterialSamreen Kaur100% (1)
- 11 Accountancy English 2020 21Document376 pages11 Accountancy English 2020 21Tanishq Bindal100% (1)
- Chapter 6 Introduction To Micro and Macro EconomicsDocument13 pagesChapter 6 Introduction To Micro and Macro EconomicsVinay ShettyNo ratings yet
- Subhash Dey's IED XII 2024-25 (Sample PDFDocument38 pagesSubhash Dey's IED XII 2024-25 (Sample PDFAnjana Arun ANo ratings yet
- Economics Quick Revision MatrialDocument33 pagesEconomics Quick Revision MatrialSiddhi AgarwalNo ratings yet
- MBA-Project Guideline PDFDocument7 pagesMBA-Project Guideline PDFAbhi Singh100% (1)
- Tabulation of DataDocument5 pagesTabulation of DataSalman AnsariNo ratings yet
- B.Ed 1.5 Year 1 & 2 Assignment Spring 2019Document11 pagesB.Ed 1.5 Year 1 & 2 Assignment Spring 2019HamaYoun BabAr100% (1)
- 804 Math Answer SheetDocument12 pages804 Math Answer Sheetmaham khanNo ratings yet
- Applied ElectronicsDocument40 pagesApplied ElectronicsGuruKPO75% (4)
- Computer Graphics & Image ProcessingDocument117 pagesComputer Graphics & Image ProcessingGuruKPONo ratings yet
- OptimizationDocument96 pagesOptimizationGuruKPO67% (3)
- Abstract AlgebraDocument111 pagesAbstract AlgebraGuruKPO100% (5)
- Applied ElectronicsDocument37 pagesApplied ElectronicsGuruKPO100% (2)
- Algorithms and Application ProgrammingDocument114 pagesAlgorithms and Application ProgrammingGuruKPONo ratings yet
- Biyani's Think Tank: Concept Based NotesDocument49 pagesBiyani's Think Tank: Concept Based NotesGuruKPO71% (7)
- Think Tank - Advertising & Sales PromotionDocument75 pagesThink Tank - Advertising & Sales PromotionGuruKPO67% (3)
- Algorithms and Application ProgrammingDocument114 pagesAlgorithms and Application ProgrammingGuruKPONo ratings yet
- Production and Material ManagementDocument50 pagesProduction and Material ManagementGuruKPONo ratings yet
- Product and Brand ManagementDocument129 pagesProduct and Brand ManagementGuruKPONo ratings yet
- Business LawDocument112 pagesBusiness LawDewanFoysalHaqueNo ratings yet
- Data Communication & NetworkingDocument138 pagesData Communication & NetworkingGuruKPO80% (5)
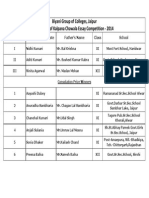
- Biyani Group of Colleges, Jaipur Merit List of Kalpana Chawala Essay Competition - 2014Document1 pageBiyani Group of Colleges, Jaipur Merit List of Kalpana Chawala Essay Competition - 2014GuruKPONo ratings yet
- Community Health Nursing Jan 2013Document1 pageCommunity Health Nursing Jan 2013GuruKPONo ratings yet
- Paediatric Nursing Sep 2013 PDFDocument1 pagePaediatric Nursing Sep 2013 PDFGuruKPONo ratings yet
- Phychology & Sociology Jan 2013Document1 pagePhychology & Sociology Jan 2013GuruKPONo ratings yet
- Phychology & Sociology Jan 2013Document1 pagePhychology & Sociology Jan 2013GuruKPONo ratings yet
- Legal and Constitutional History of IndiaDocument34 pagesLegal and Constitutional History of IndiaGuruKPO86% (29)
- Software Project ManagementDocument41 pagesSoftware Project ManagementGuruKPO100% (1)
- Business Ethics and EthosDocument36 pagesBusiness Ethics and EthosGuruKPO100% (3)
- Data Communication & NetworkingDocument138 pagesData Communication & NetworkingGuruKPO80% (5)
- Medical Surgical Nursing - IIDocument56 pagesMedical Surgical Nursing - IIGuruKPO33% (6)
- Computer Graphics & Image ProcessingDocument117 pagesComputer Graphics & Image ProcessingGuruKPONo ratings yet
- Medical Surgical Nursing - IDocument97 pagesMedical Surgical Nursing - IGuruKPO80% (10)
- Mental Health of GNMDocument133 pagesMental Health of GNMGuruKPO100% (9)
- Strategic ManagementDocument61 pagesStrategic ManagementGuruKPONo ratings yet
- Biyani's Think Tank: Concept Based NotesDocument49 pagesBiyani's Think Tank: Concept Based NotesGuruKPO71% (7)
- Fundamentals of NursingDocument50 pagesFundamentals of NursingGuruKPO67% (3)
- First AidDocument58 pagesFirst AidGuruKPO75% (4)
- Using and Interpreting Statistics 3Rd Edition Corty Test Bank Full Chapter PDFDocument32 pagesUsing and Interpreting Statistics 3Rd Edition Corty Test Bank Full Chapter PDFCharlesBlackbswk100% (6)
- Meta AnalysisDocument33 pagesMeta AnalysissiawNo ratings yet
- Vasicek Adjustment To Beta EstimatesDocument21 pagesVasicek Adjustment To Beta EstimatesVíctor Hugo Ulloa VillarroelNo ratings yet
- Probability and Statistic Chapter7 - Linear - Regression - ModelsDocument116 pagesProbability and Statistic Chapter7 - Linear - Regression - ModelsPHƯƠNG ĐẶNG YẾNNo ratings yet
- Sampling Distributions: Section 7.1Document21 pagesSampling Distributions: Section 7.1DrMohamed MansourNo ratings yet
- Ateneo de Davao University: Welcome To Statistics and Probability Subject!Document13 pagesAteneo de Davao University: Welcome To Statistics and Probability Subject!Kyle BARRIOSNo ratings yet
- Tune Gaussian Mixture Models - MATLAB & Simulink - MathWorks IndiaDocument6 pagesTune Gaussian Mixture Models - MATLAB & Simulink - MathWorks Indiasunshinesun49No ratings yet
- Effects of Financial Innovations On FinaDocument12 pagesEffects of Financial Innovations On FinaKevin OdhiamboNo ratings yet
- Choice of Functional FormDocument4 pagesChoice of Functional Formsabir17No ratings yet
- Performance Task 14.0 - Nery, TheaDocument2 pagesPerformance Task 14.0 - Nery, Theaeloise eaNo ratings yet
- 2020 - BES 220 - Semester Test 3 - MemoDocument10 pages2020 - BES 220 - Semester Test 3 - MemoknineNo ratings yet
- Measures of Dispersion (Part 2)Document13 pagesMeasures of Dispersion (Part 2)BS Accoutancy St. SimonNo ratings yet
- التطبيقات الالكترونية و دورها في تحقيق جودة الخدمة - دراسة حالة مؤسسة بريد الجزائر بالجلفةDocument15 pagesالتطبيقات الالكترونية و دورها في تحقيق جودة الخدمة - دراسة حالة مؤسسة بريد الجزائر بالجلفةhamid bouklilaNo ratings yet
- Version 3 Documentation AddendumDocument11 pagesVersion 3 Documentation AddendumTmazvelNo ratings yet
- CorrelationDocument26 pagesCorrelationChristine Mae Lumawag100% (1)
- Time Series Analysis AssignmentDocument2 pagesTime Series Analysis AssignmentMusa KhanNo ratings yet
- Mean Vector and Correlation Matrix in R - Jupyter NotebookDocument7 pagesMean Vector and Correlation Matrix in R - Jupyter NotebookAnuvidyaKarthiNo ratings yet
- 統計ch14 solutionDocument69 pages統計ch14 solutionH54094015張柏駿No ratings yet
- Confirmatory Factor Analysis Using AMOSDocument14 pagesConfirmatory Factor Analysis Using AMOSMadhu MauryaNo ratings yet
- University of Toronto Scarborough STAB22 Midterm ExaminationDocument13 pagesUniversity of Toronto Scarborough STAB22 Midterm ExaminationAbdullahiNo ratings yet
- AMOS-nov1 1Document83 pagesAMOS-nov1 1zainidaNo ratings yet
- 2021-3-Mel-Kte Tun Fatimah-ADocument5 pages2021-3-Mel-Kte Tun Fatimah-Am-4306022No ratings yet
- SS 02 Quiz 1 - Answers PDFDocument64 pagesSS 02 Quiz 1 - Answers PDFdumboooodogNo ratings yet
- Beyond The Shades of Vote:voter's Educational Awareness Among Grade 12 Students in LNHSDocument58 pagesBeyond The Shades of Vote:voter's Educational Awareness Among Grade 12 Students in LNHSfelynjoyhopilosNo ratings yet
- Evaluating Allowable Properties For Grades of Structural LumberDocument13 pagesEvaluating Allowable Properties For Grades of Structural LumberAnonymous 4GNAkbVRTNo ratings yet
- Scikit-Learn Cheat Sheet Python For Data Science: Preprocessing The Data Evaluate Your Model's PerformanceDocument1 pageScikit-Learn Cheat Sheet Python For Data Science: Preprocessing The Data Evaluate Your Model's PerformanceLourdes Victoria Urrutia100% (1)
- Estimation of Nonstationary Heterogeneous PanelsDocument13 pagesEstimation of Nonstationary Heterogeneous PanelsQoumal HashmiNo ratings yet
- Genstat Release 12.1 (Pc/Windows Vista) 27 February 2017 16:01:27Document11 pagesGenstat Release 12.1 (Pc/Windows Vista) 27 February 2017 16:01:27Saurav ShresthaNo ratings yet
- Forecasting The Sugarcane Production in Bangladesh PDFDocument7 pagesForecasting The Sugarcane Production in Bangladesh PDFLuiz EduardoNo ratings yet
- Business Mathematics & StatisticsDocument31 pagesBusiness Mathematics & StatisticszainaliNo ratings yet