You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- DirtyMobs' Ultimate Matchup GuideDocument5 pagesDirtyMobs' Ultimate Matchup GuideTempest JannaNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Teaching and Learning StrategiesDocument24 pagesTeaching and Learning Strategiesal alami azzeddine100% (7)
- CH 9 AnswersDocument31 pagesCH 9 AnswersIbrahim A Said100% (2)
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Andy Landers - Freeze Zone OffenseDocument6 pagesAndy Landers - Freeze Zone OffenseWinston Brown100% (1)
- Medical - History - Questionnaire .Document1 pageMedical - History - Questionnaire .Hind Abu GhazlehNo ratings yet
- Unit 3 - Projectile MotionDocument2 pagesUnit 3 - Projectile MotionHind Abu GhazlehNo ratings yet
- Methanol All DataDocument401 pagesMethanol All DataHind Abu GhazlehNo ratings yet
- Unit 3 - Projectile MotionDocument2 pagesUnit 3 - Projectile MotionHind Abu GhazlehNo ratings yet
- Ug PDFDocument265 pagesUg PDFHyakansahsNo ratings yet
- Lesson Plan HindDocument2 pagesLesson Plan HindHind Abu GhazlehNo ratings yet
- Physics SampleDocument9 pagesPhysics SamplevipulmuraliNo ratings yet
- Position Applied For: Direct CV: Candidate BriefDocument1 pagePosition Applied For: Direct CV: Candidate BriefPARVAIZ AHMAD KOKANo ratings yet
- Student Progress Sheet Projectile Motion ModelDocument2 pagesStudent Progress Sheet Projectile Motion ModelHind Abu GhazlehNo ratings yet
- Chap 5 Lesson 1Document28 pagesChap 5 Lesson 1Hind Abu GhazlehNo ratings yet
- Lesson Plan HindDocument2 pagesLesson Plan HindHind Abu GhazlehNo ratings yet
- Water Methanol MixDocument23 pagesWater Methanol MixHind Abu GhazlehNo ratings yet
- CH 10 Answers PDFDocument21 pagesCH 10 Answers PDFHind Abu GhazlehNo ratings yet
- CH 4 Answers PDFDocument26 pagesCH 4 Answers PDFHind Abu GhazlehNo ratings yet
- F 90Document33 pagesF 90Hind Abu GhazlehNo ratings yet
- Fortran 1Document44 pagesFortran 1Hind Abu GhazlehNo ratings yet
- A Helping Hand: Author: Payal Dhar Illustrator: Vartika SharmaDocument25 pagesA Helping Hand: Author: Payal Dhar Illustrator: Vartika SharmajedydyNo ratings yet
- I Sing ModelDocument25 pagesI Sing ModelHind Abu GhazlehNo ratings yet
- 1Document10 pages1Hind Abu GhazlehNo ratings yet
- Jackson 5 13 Homework SolutionDocument3 pagesJackson 5 13 Homework SolutionHind Abu GhazlehNo ratings yet
- c3cp52444b 2Document7 pagesc3cp52444b 2Hind Abu GhazlehNo ratings yet
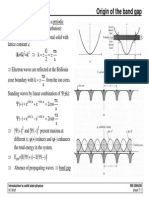
- Origin of the band gap: a x i a x i π − π π − πDocument2 pagesOrigin of the band gap: a x i a x i π − π π − πHind Abu GhazlehNo ratings yet
- Jackson 4 13 Homework SolutionDocument3 pagesJackson 4 13 Homework SolutionHind Abu GhazlehNo ratings yet
- Jackson 5 16 Homework SolutionDocument4 pagesJackson 5 16 Homework SolutionHind Abu GhazlehNo ratings yet
- IsingDocument11 pagesIsingHind Abu GhazlehNo ratings yet
- Ising Lenz MCDocument4 pagesIsing Lenz MCHind Abu GhazlehNo ratings yet
- Corporation Law Quiz AnswersDocument3 pagesCorporation Law Quiz AnswerswivadaNo ratings yet
- ADSL Line Driver Design Guide, Part 2Document10 pagesADSL Line Driver Design Guide, Part 2domingohNo ratings yet
- Chapter One - Understanding The Digital WorldDocument8 pagesChapter One - Understanding The Digital Worldlaith alakelNo ratings yet
- A Study On Inventory Management Towards Organizational Performance of Manufacturing Company in MelakaDocument12 pagesA Study On Inventory Management Towards Organizational Performance of Manufacturing Company in MelakaOsama MazharNo ratings yet
- The Role of Christian Education in Socia Group 6Document6 pagesThe Role of Christian Education in Socia Group 6Ṭhanuama BiateNo ratings yet
- Science & Technology: Wireless Sensor Network and Internet of Things (Iot) Solution in AgricultureDocument10 pagesScience & Technology: Wireless Sensor Network and Internet of Things (Iot) Solution in AgricultureSivajith SNo ratings yet
- 6 Strategies For Effective Financial Management Trends in K12 SchoolsDocument16 pages6 Strategies For Effective Financial Management Trends in K12 SchoolsRainiel Victor M. CrisologoNo ratings yet
- Modelling of Induction Motor PDFDocument42 pagesModelling of Induction Motor PDFsureshNo ratings yet
- Blaise PascalDocument8 pagesBlaise PascalBosko GuberinicNo ratings yet
- Causes and Diagnosis of Iron Deficiency and Iron Deficiency Anemia in AdultsDocument88 pagesCauses and Diagnosis of Iron Deficiency and Iron Deficiency Anemia in AdultsGissell LópezNo ratings yet
- Policy Guidelines On Classroom Assessment K12Document88 pagesPolicy Guidelines On Classroom Assessment K12Jardo de la PeñaNo ratings yet
- Atmospheres of Space The Development of Alvar Aalto S Free Flow Section As A Climate DeviceDocument18 pagesAtmospheres of Space The Development of Alvar Aalto S Free Flow Section As A Climate DeviceSebastian BaumannNo ratings yet
- Bible Study RisksDocument6 pagesBible Study RisksVincentNo ratings yet
- AwsDocument8 pagesAwskiranNo ratings yet
- Islamic Finance in the UKDocument27 pagesIslamic Finance in the UKAli Can ERTÜRK (alicanerturk)No ratings yet
- People v. Cresencia ReyesDocument7 pagesPeople v. Cresencia ReyesAnggling DecolongonNo ratings yet
- BSC Part IiDocument76 pagesBSC Part IiAbhi SinghNo ratings yet
- Epithelial and connective tissue types in the human bodyDocument4 pagesEpithelial and connective tissue types in the human bodyrenee belle isturisNo ratings yet
- Sri Dakshinamurthy Stotram - Hindupedia, The Hindu EncyclopediaDocument7 pagesSri Dakshinamurthy Stotram - Hindupedia, The Hindu Encyclopediamachnik1486624No ratings yet
- Acute Care Handbook For Physical Therapists 5Th Edition Full ChapterDocument41 pagesAcute Care Handbook For Physical Therapists 5Th Edition Full Chaptergloria.goodwin463100% (20)
- (Cambridge Series in Statistical and Probabilistic Mathematics) Gerhard Tutz, Ludwig-Maximilians-Universität Munchen - Regression For Categorical Data-Cambridge University Press (2012)Document574 pages(Cambridge Series in Statistical and Probabilistic Mathematics) Gerhard Tutz, Ludwig-Maximilians-Universität Munchen - Regression For Categorical Data-Cambridge University Press (2012)shu100% (2)
- S The Big Five Personality TestDocument4 pagesS The Big Five Personality TestXiaomi MIX 3No ratings yet
- Intermediate Reading Comprehension Test 03Document5 pagesIntermediate Reading Comprehension Test 03MZNo ratings yet
- Assessment Explanation of The Problem Outcomes Interventions Rationale Evaluation Sto: STO: (Goal Met)Document3 pagesAssessment Explanation of The Problem Outcomes Interventions Rationale Evaluation Sto: STO: (Goal Met)Arian May MarcosNo ratings yet
- United States Court of Appeals, Sixth CircuitDocument5 pagesUnited States Court of Appeals, Sixth CircuitScribd Government DocsNo ratings yet
- Christian Storytelling EvaluationDocument3 pagesChristian Storytelling Evaluationerika paduaNo ratings yet
- INTERNSHIP REPORT 3 PagesDocument4 pagesINTERNSHIP REPORT 3 Pagesali333444No ratings yet
- Homework WatergateDocument8 pagesHomework Watergateaapsujtif100% (1)