You might also like
- Dracula PDFDocument542 pagesDracula PDFKarthik SheshadriNo ratings yet
- Alex Wayman Untying The Knots in BuddhismDocument634 pagesAlex Wayman Untying The Knots in BuddhismHan Sang KimNo ratings yet
- Pone D 19 15324 - R2Document163 pagesPone D 19 15324 - R2Karthik SheshadriNo ratings yet
- Prominence PNAS SubmissionDocument10 pagesProminence PNAS SubmissionKarthik SheshadriNo ratings yet
- Pone D 19 15324Document32 pagesPone D 19 15324Karthik SheshadriNo ratings yet
- Morality or Equality Ideological Framing in News CDocument17 pagesMorality or Equality Ideological Framing in News CKarthik SheshadriNo ratings yet
- FramingChanges PLOS One Revision Submit LatestDocument34 pagesFramingChanges PLOS One Revision Submit LatestKarthik SheshadriNo ratings yet
- US Cyberbullying Laws by YearDocument4 pagesUS Cyberbullying Laws by YearKarthik SheshadriNo ratings yet
- Confirmation: 1-888-205-8118 M-F 6:30am PST To 5:30pm PSTDocument1 pageConfirmation: 1-888-205-8118 M-F 6:30am PST To 5:30pm PSTKarthik SheshadriNo ratings yet
- 4-19-2017 - Talking AbDocument19 pages4-19-2017 - Talking AbKarthik SheshadriNo ratings yet
- (Compare New) NewmainDocument29 pages(Compare New) NewmainKarthik SheshadriNo ratings yet
- Framing News: Predicting Legislative ChangesDocument17 pagesFraming News: Predicting Legislative ChangesKarthik SheshadriNo ratings yet
- HW4 Fall 2017 SolutionsDocument7 pagesHW4 Fall 2017 SolutionsKarthik SheshadriNo ratings yet
- Philosophy of Minds Hard Problem in LighDocument27 pagesPhilosophy of Minds Hard Problem in LighKarthik SheshadriNo ratings yet
- PST 2017 Paper 19Document12 pagesPST 2017 Paper 19Karthik SheshadriNo ratings yet
- Fat TriangleDocument10 pagesFat TriangleKarthik SheshadriNo ratings yet
- A Gaussian Approximation of Feature Space For Fast Image SimilarityDocument13 pagesA Gaussian Approximation of Feature Space For Fast Image SimilarityKarthik SheshadriNo ratings yet
- WACV2014Document9 pagesWACV2014Karthik SheshadriNo ratings yet
- 2.19 Agganna S d27 PiyaDocument35 pages2.19 Agganna S d27 PiyaKarthik SheshadriNo ratings yet
- Enev ACSAC12 SensorsiftDocument10 pagesEnev ACSAC12 SensorsiftKarthik SheshadriNo ratings yet
- Motion Capture of Hands in Action Using Discriminative Salient PointsDocument14 pagesMotion Capture of Hands in Action Using Discriminative Salient PointsKarthik SheshadriNo ratings yet
- 10 1 1 112 9258Document8 pages10 1 1 112 9258Karthik SheshadriNo ratings yet
- 9 C 96051658 F 5851 A 88Document3 pages9 C 96051658 F 5851 A 88Karthik SheshadriNo ratings yet
- AISec2016 Paper 26Document12 pagesAISec2016 Paper 26Karthik SheshadriNo ratings yet
- Devolution and Evolution in The Agganna PDFDocument92 pagesDevolution and Evolution in The Agganna PDFKarthik SheshadriNo ratings yet
- Fine-Grained Crowdsourcing for Recognition Using "BubblesDocument8 pagesFine-Grained Crowdsourcing for Recognition Using "BubblesKarthik SheshadriNo ratings yet
- Acebulla BachelorThesisDocument61 pagesAcebulla BachelorThesisKarthik SheshadriNo ratings yet
- Fourier DescriptorDocument27 pagesFourier DescriptorAmir AsaadNo ratings yet
- Choosing Linguistics Over Vision To Describe Images: Ankush Gupta, Yashaswi Verma, C. V. JawaharDocument7 pagesChoosing Linguistics Over Vision To Describe Images: Ankush Gupta, Yashaswi Verma, C. V. JawaharKarthik SheshadriNo ratings yet
- Template Matching Using F NCCDocument8 pagesTemplate Matching Using F NCCKarthik SheshadriNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5784)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Polynomials - Worksheet1Document2 pagesPolynomials - Worksheet1ckankaria749No ratings yet
- Praktis Ekstra Ting 5 Bab 2Document6 pagesPraktis Ekstra Ting 5 Bab 2DIANANo ratings yet
- Gate Aerospace Notes PDFDocument231 pagesGate Aerospace Notes PDFபிரகதீஸ்வரன் தமிழன்100% (2)
- Chemical Reviews Volume 112 issue 1 2012 [doi 10.1021%2Fcr200137a] Szalay, Péter G.; Müller, Thomas; Gidofalvi, Gergely -- Multiconfiguration Self-Consistent Field and Multireference Configuration Interaction Methods andDocument74 pagesChemical Reviews Volume 112 issue 1 2012 [doi 10.1021%2Fcr200137a] Szalay, Péter G.; Müller, Thomas; Gidofalvi, Gergely -- Multiconfiguration Self-Consistent Field and Multireference Configuration Interaction Methods andJosé CortésNo ratings yet
- This File Contains Match The Columns (Collection # 2) : Very Important Guessing QuestionsDocument9 pagesThis File Contains Match The Columns (Collection # 2) : Very Important Guessing QuestionsHNGHNo ratings yet
- Homework Solutions #1: 1.1 1.4 1.7 1.11 1.15 1.26 2.12 2.29 2.54Document10 pagesHomework Solutions #1: 1.1 1.4 1.7 1.11 1.15 1.26 2.12 2.29 2.54Vinay BansalNo ratings yet
- Syllabus For Applied MathematicsDocument8 pagesSyllabus For Applied Mathematicsmichael abe100% (1)
- Multiplication of Real NumbersDocument27 pagesMultiplication of Real NumbersMr. AulisioNo ratings yet
- Introduction To Mathematical Thinking Algebra and Number Systems Will J. Gilbert, Scott A. Vanstone Solutions ManualDocument5 pagesIntroduction To Mathematical Thinking Algebra and Number Systems Will J. Gilbert, Scott A. Vanstone Solutions Manualasu0% (1)
- C Hidegkuti, Powell, 2008 Last Revised: February 25, 2009Document9 pagesC Hidegkuti, Powell, 2008 Last Revised: February 25, 2009znchicago338No ratings yet
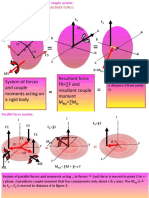
- Simplification of a system of forces and moments acting on a rigid body to a single resultant force and momentDocument71 pagesSimplification of a system of forces and moments acting on a rigid body to a single resultant force and momentvat007No ratings yet
- 8TH GRADE MATH TEST REVIEWDocument10 pages8TH GRADE MATH TEST REVIEWShiela Mae CasNo ratings yet
- AET Math Camp 2018 PDFDocument72 pagesAET Math Camp 2018 PDFLee RickHunterNo ratings yet
- Special Products: By: Nathaniel S. AnteroDocument14 pagesSpecial Products: By: Nathaniel S. AnteroJudea Mae Canuto AnteroNo ratings yet
- 1 Introduction To Linear Transformations - Section 4.1 of DefranzaDocument33 pages1 Introduction To Linear Transformations - Section 4.1 of DefranzaCarlos VargasNo ratings yet
- Solving Quadratic EquationsDocument17 pagesSolving Quadratic EquationsaabhushanNo ratings yet
- Divide-And-Conquer (CLRS 4.2) : Matrix MultiplicationDocument4 pagesDivide-And-Conquer (CLRS 4.2) : Matrix MultiplicationRajeev RanjanNo ratings yet
- Chapter 3 Lines and CirclesDocument10 pagesChapter 3 Lines and CirclesSong KimNo ratings yet
- (Infosys Science Foundation Series) Ramji Lal (Auth.) - Algebra 1 - Groups, Rings, Fields and Arithmetic-Springer Singapore (2017) PDFDocument439 pages(Infosys Science Foundation Series) Ramji Lal (Auth.) - Algebra 1 - Groups, Rings, Fields and Arithmetic-Springer Singapore (2017) PDFFernandoDiaz100% (1)
- ME 408 Finite Element Approximation Homework# 4 MATLAB Jacobi MethodDocument6 pagesME 408 Finite Element Approximation Homework# 4 MATLAB Jacobi Methodduv509No ratings yet
- FEM NDTruong (Eng)Document59 pagesFEM NDTruong (Eng)Ngọc VănNo ratings yet
- Ath em Ati CS: L.K .SH Arm ADocument10 pagesAth em Ati CS: L.K .SH Arm APremNo ratings yet
- 6th Maths FractionsDocument24 pages6th Maths Fractionsvaibhav singhNo ratings yet
- Metin Arik, Gökhan Ünel Auth., Bruno Gruber, Michael Ramek Eds. Symmetries in Science IXDocument351 pagesMetin Arik, Gökhan Ünel Auth., Bruno Gruber, Michael Ramek Eds. Symmetries in Science IXdeblazeNo ratings yet
- A5405-Digital Control SystemsDocument2 pagesA5405-Digital Control Systemshari0118No ratings yet
- Rules For Making Bode Plots: Term Magnitude PhaseDocument4 pagesRules For Making Bode Plots: Term Magnitude PhaseYgor GonzalezNo ratings yet
- Computer Lab 3Document2 pagesComputer Lab 3german intencipaNo ratings yet
- Evaluating Algebraic ExpressionDocument6 pagesEvaluating Algebraic ExpressionIbtsam YossefNo ratings yet
- ES 11 LE1 SamplexDocument2 pagesES 11 LE1 SamplexAnna Louise WyNo ratings yet
- Resolving Vectors ExperimentallyDocument8 pagesResolving Vectors ExperimentallyMaria Carla Angelica DeladiaNo ratings yet










































































![Chemical Reviews Volume 112 issue 1 2012 [doi 10.1021%2Fcr200137a] Szalay, Péter G.; Müller, Thomas; Gidofalvi, Gergely -- Multiconfiguration Self-Consistent Field and Multireference Configuration Interaction Methods and](https://imgv2-2-f.scribdassets.com/img/document/198958127/149x198/7faae602dc/1389501112?v=1)