You might also like
- Algorithms in PythonDocument218 pagesAlgorithms in Pythonsarvesh_mishra100% (8)
- Salesforce - Platform App Builder.v2020!11!22.q105Document27 pagesSalesforce - Platform App Builder.v2020!11!22.q105Vamsi EedeNo ratings yet
- Chapter 5 - Analog - TransmissionDocument6 pagesChapter 5 - Analog - TransmissionMd Saidur Rahman Kohinoor92% (86)
- Singular Value Decomposition - Lecture NotesDocument87 pagesSingular Value Decomposition - Lecture NotesRoyi100% (1)
- Jackson Electrodynamics, Notes 1Document5 pagesJackson Electrodynamics, Notes 1Tianyi ZhangNo ratings yet
- Linear Algebra Cheat SheetDocument2 pagesLinear Algebra Cheat SheettraponegroNo ratings yet
- Jeffrey M Wooldridge Solutions Manual and Supplementary Materials For Econometric Analysis of Cross Section and Panel Data 2003Document135 pagesJeffrey M Wooldridge Solutions Manual and Supplementary Materials For Econometric Analysis of Cross Section and Panel Data 2003vanyta020194% (17)
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsFrom EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsNo ratings yet
- Jackson 9.10, 9.16Document13 pagesJackson 9.10, 9.16razarizvi1No ratings yet
- Cs421 Cheat SheetDocument2 pagesCs421 Cheat SheetJoe McGuckinNo ratings yet
- The Micro-Inverter: Francine V. NotteDocument49 pagesThe Micro-Inverter: Francine V. Nottemanish_chaturvedi_6No ratings yet
- Application of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsFrom EverandApplication of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsRating: 5 out of 5 stars5/5 (1)
- Captiva Control MotorDocument52 pagesCaptiva Control Motorsertex_jo71% (7)
- Applications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankFrom EverandApplications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankNo ratings yet
- Least Square Equation SolvingDocument22 pagesLeast Square Equation Solvingnguyen_anh_126No ratings yet
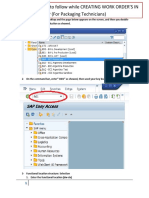
- Warehouse Order Creation Process and Its BenefitsDocument4 pagesWarehouse Order Creation Process and Its Benefitskishore0% (1)
- Oracle HCM Cloud OverviewDocument35 pagesOracle HCM Cloud OverviewAngelVillalobosNo ratings yet
- Physics 21 SolutionsDocument92 pagesPhysics 21 SolutionsOğuzhan Odbay100% (1)
- 1 Congruence and Modular ArithmeticsDocument9 pages1 Congruence and Modular ArithmeticsEduardo CastilloNo ratings yet
- Chapter 4Document14 pagesChapter 4Hamed NikbakhtNo ratings yet
- Lecture 9 Linear Least Squares SVDDocument20 pagesLecture 9 Linear Least Squares SVDminhthangbkNo ratings yet
- PART I: Approximation of Static SystemsDocument123 pagesPART I: Approximation of Static Systemsyiğit_ÖksüzNo ratings yet
- AR Z-Transform PDFDocument48 pagesAR Z-Transform PDFshereenkhan1200% (1)
- Nonlinear Optimization (18799 B, PP) : Ist-Cmu PHD Course, Spring 2011Document11 pagesNonlinear Optimization (18799 B, PP) : Ist-Cmu PHD Course, Spring 2011Daniel SilvestreNo ratings yet
- Lecture 22Document4 pagesLecture 22Eric ParkerNo ratings yet
- What NPCDocument5 pagesWhat NPCmaurice.gaucheNo ratings yet
- Intro SVDDocument16 pagesIntro SVDTri KasihnoNo ratings yet
- HW 1Document6 pagesHW 1Morokot AngelaNo ratings yet
- Least-Squares Rigid Motion Using SVDDocument5 pagesLeast-Squares Rigid Motion Using SVDargho1213No ratings yet
- Divyanshu Prakash: Mewar University, ChittorgarhDocument27 pagesDivyanshu Prakash: Mewar University, ChittorgarhsitakantasamantarayNo ratings yet
- Curvve Fitting - Least Square MethodDocument45 pagesCurvve Fitting - Least Square Methodarnel cabesasNo ratings yet
- 4 QR Factorization: 4.1 Reduced vs. Full QRDocument12 pages4 QR Factorization: 4.1 Reduced vs. Full QRMohammad Umar RehmanNo ratings yet
- Gls PDFDocument12 pagesGls PDFJuan CamiloNo ratings yet
- Lecture 13: Survey of Adaptive Filtering Methods: - Basic ProblemsDocument21 pagesLecture 13: Survey of Adaptive Filtering Methods: - Basic ProblemsprakashroutNo ratings yet
- Bentbib A.H. Kanber A.Document14 pagesBentbib A.H. Kanber A.LucianamxsNo ratings yet
- Theorist's Toolkit Lecture 6: Eigenvalues and ExpandersDocument9 pagesTheorist's Toolkit Lecture 6: Eigenvalues and ExpandersJeremyKunNo ratings yet
- LMS FilteringDocument81 pagesLMS Filteringtaoyrind3075No ratings yet
- Math 32A Final Review (Fall 2012) : 1 Geometry of RDocument18 pagesMath 32A Final Review (Fall 2012) : 1 Geometry of RJoe SmithNo ratings yet
- Determinants (CTD) : Cramer's Rule (Section 2.3)Document9 pagesDeterminants (CTD) : Cramer's Rule (Section 2.3)asahNo ratings yet
- Lecture-7: Electric Potential, Laplace and Poisson's EquationsDocument38 pagesLecture-7: Electric Potential, Laplace and Poisson's Equationsvivek patelNo ratings yet
- HW 2Document2 pagesHW 2Lencie Dela CruzNo ratings yet
- hw8 Solns PDFDocument7 pageshw8 Solns PDFDon QuixoteNo ratings yet
- The Q-Numerical Range of A Certain: 3 × 3 MatrixDocument10 pagesThe Q-Numerical Range of A Certain: 3 × 3 Matrixjulianli0220No ratings yet
- Singular Value Decomposition (SVD) : - DefinitionDocument5 pagesSingular Value Decomposition (SVD) : - DefinitionMervin RodrigoNo ratings yet
- The Non Linear Advection Equation (Inviscid Burgers Equation)Document6 pagesThe Non Linear Advection Equation (Inviscid Burgers Equation)linoNo ratings yet
- Roychowdhury 2010 MSCDocument16 pagesRoychowdhury 2010 MSCJohnNo ratings yet
- Section 7.4 Notes (The SVD)Document9 pagesSection 7.4 Notes (The SVD)tech166No ratings yet
- Arc TanDocument3 pagesArc TanlennyrodolfoNo ratings yet
- Algebra Qual F05Document6 pagesAlgebra Qual F05uppsNo ratings yet
- Differential Calculus-I: Note: 1. If K ( 0) Is The Curvature of A Curve at P, Then The RadiusDocument28 pagesDifferential Calculus-I: Note: 1. If K ( 0) Is The Curvature of A Curve at P, Then The RadiustechzonesNo ratings yet
- Solving Systems of Linear EquationsDocument9 pagesSolving Systems of Linear EquationsGebrekirstos TsegayNo ratings yet
- The Jacobi Method (II) : Some Implementation DetailsDocument42 pagesThe Jacobi Method (II) : Some Implementation DetailsSamuel DefilippoNo ratings yet
- Quicksort: Quicksort (A, P, R) : Ifn 1:return Q Partition (A, P, R) Quicksort (A, P, q-1) Quicksort (A, q+1, R)Document6 pagesQuicksort: Quicksort (A, P, R) : Ifn 1:return Q Partition (A, P, R) Quicksort (A, P, q-1) Quicksort (A, q+1, R)Andrew LeeNo ratings yet
- Groups SlidesDocument146 pagesGroups Slidesasiyahsharif1303No ratings yet
- GeorgiaTech CS-6515: Graduate Algorithms: Math Theorems Flashcards by Calvin Hoang - BrainscapeDocument14 pagesGeorgiaTech CS-6515: Graduate Algorithms: Math Theorems Flashcards by Calvin Hoang - BrainscapeJan_SuNo ratings yet
- Math 2418 Exam III - Spring 2013 SolutionsDocument8 pagesMath 2418 Exam III - Spring 2013 SolutionsJohnson PhanNo ratings yet
- MF9 Formula Sheet - List of FormulasDocument9 pagesMF9 Formula Sheet - List of FormulasBrendon Nyabinde75% (4)
- Geostatistics Formula SheetDocument2 pagesGeostatistics Formula SheetAnonymous cMBxGANo ratings yet
- MA412 FinalDocument82 pagesMA412 FinalAhmad Zen FiraNo ratings yet
- A Fast Algorithm For Computing Pseudospectra of Companion MatricesDocument4 pagesA Fast Algorithm For Computing Pseudospectra of Companion MatricesInternational Journal of Science and Engineering InvestigationsNo ratings yet
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Logarithmic Fourier Transformation: G. V. Haines and Alan G. JonesDocument8 pagesLogarithmic Fourier Transformation: G. V. Haines and Alan G. Jonesdautroc13No ratings yet
- DRS 2018 Simeone Et Al. FinalDocument13 pagesDRS 2018 Simeone Et Al. FinalLuca SimeoneNo ratings yet
- Opportunity, Willingness and Geographic Information Systems (Gis) : Reconceptualizing Borders in International RelationsDocument29 pagesOpportunity, Willingness and Geographic Information Systems (Gis) : Reconceptualizing Borders in International RelationsAtom Sunil SinghNo ratings yet
- How To Learn From GATE Applied Course - TOCDocument1 pageHow To Learn From GATE Applied Course - TOCrythgngNo ratings yet
- 63180en 01Document157 pages63180en 01Samuel MarquezNo ratings yet
- 1) Develop An Application That Uses GUI Components, Fonts and ColorsDocument56 pages1) Develop An Application That Uses GUI Components, Fonts and ColorsKirti AroraNo ratings yet
- 3com Switch Configuration GuideDocument90 pages3com Switch Configuration GuideJumaa RashidNo ratings yet
- Week 5:: Contact Center ServicesDocument12 pagesWeek 5:: Contact Center ServicesMichael MangahasNo ratings yet
- Creating WO SOP and Teko in SapDocument10 pagesCreating WO SOP and Teko in SapGeorge AgafinaNo ratings yet
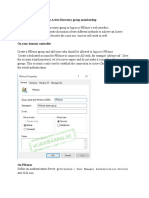
- Log in To PfSense Based On Active Directory Group MembershipDocument8 pagesLog in To PfSense Based On Active Directory Group MembershipGodspower InibuNo ratings yet
- December 18, 2020: Announcement: New Cisco Partner Program - Integrator RoleDocument3 pagesDecember 18, 2020: Announcement: New Cisco Partner Program - Integrator RoleSanjin ZuhricNo ratings yet
- Reading Test 1. Online: Is ScheduledDocument5 pagesReading Test 1. Online: Is ScheduledThanh LêNo ratings yet
- DSP 10 Marks Assignment Compulsory For All PDFDocument2 pagesDSP 10 Marks Assignment Compulsory For All PDFrajNo ratings yet
- Curriculum Mtech IOT 2017 2018Document54 pagesCurriculum Mtech IOT 2017 2018ndpraju123No ratings yet
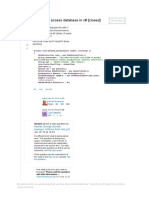
- Net - How To Connect Access Database in C# - Stack OverflowDocument4 pagesNet - How To Connect Access Database in C# - Stack OverflowSebastianNo ratings yet
- Mihai Nicusor: Curriculum Vitae Replace With First Name(s) Surname(s)Document2 pagesMihai Nicusor: Curriculum Vitae Replace With First Name(s) Surname(s)Nicusor MihaiNo ratings yet
- IPA Transcription in UnicodeDocument7 pagesIPA Transcription in UnicodeFerreira AngelloNo ratings yet
- 1 N 52 XXBDocument2 pages1 N 52 XXB81968No ratings yet
- Berhanemeskel Reda PDF Anti Communism Far Left PoliticsDocument1 pageBerhanemeskel Reda PDF Anti Communism Far Left PoliticsAlula AbrahaNo ratings yet
- 403 - 404 - 405 - 406 - 407 - 408 - 409 - Generation (Vermontelectric - Coop)Document9 pages403 - 404 - 405 - 406 - 407 - 408 - 409 - Generation (Vermontelectric - Coop)LEON SOTNASNo ratings yet
- R7410102 Finite Element Methods in Civil EngineeringDocument4 pagesR7410102 Finite Element Methods in Civil EngineeringsivabharathamurthyNo ratings yet
- Licensure Examination For Teachers General Education Drill IiiDocument5 pagesLicensure Examination For Teachers General Education Drill IiiDennis Nabor Muñoz, RN,RMNo ratings yet
- Refu RD500 RR52Document88 pagesRefu RD500 RR52Alfonso Lopez toroNo ratings yet