You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Response Week 7Document1 pageResponse Week 7Pandurang ThatkarNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Stress and GPA: Analysis of The Initial Administration of A New Instrument For Measuring Stress and Its Relationship To College GPADocument25 pagesStress and GPA: Analysis of The Initial Administration of A New Instrument For Measuring Stress and Its Relationship To College GPAPandurang ThatkarNo ratings yet
- ResponsesDocument1 pageResponsesPandurang ThatkarNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- X X X X N X N: 1. Discuss/define Three Measures of Central TendencyDocument7 pagesX X X X N X N: 1. Discuss/define Three Measures of Central TendencyPandurang ThatkarNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- OThompson Wk5AssgnOThompsonDocument11 pagesOThompson Wk5AssgnOThompsonPandurang ThatkarNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Questions For BiostatisticsDocument5 pagesQuestions For BiostatisticsPandurang Thatkar100% (1)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- OThompson Wk5AssgnOThompsonDocument11 pagesOThompson Wk5AssgnOThompsonPandurang ThatkarNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- RegressionDocument4 pagesRegressionNazia QayumNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Responses Week2Document2 pagesResponses Week2Pandurang ThatkarNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- OThompson Wk5AssgnOThompson CorrectedDocument12 pagesOThompson Wk5AssgnOThompson CorrectedPandurang ThatkarNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- OThompson Wk5AssgnOThompsonDocument11 pagesOThompson Wk5AssgnOThompsonPandurang ThatkarNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Internet UsageDocument2 pagesInternet UsagePandurang ThatkarNo ratings yet
- Response Week 7Document1 pageResponse Week 7Pandurang ThatkarNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Field-Scale Monitoring of The Long-Term Impact and Sustainability of Drainage Water Reuse On The West Side of California's San Joaquin ValleyDocument12 pagesField-Scale Monitoring of The Long-Term Impact and Sustainability of Drainage Water Reuse On The West Side of California's San Joaquin ValleyPandurang ThatkarNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
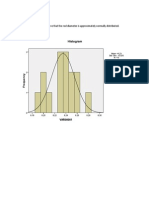
- Q.1 From The Histogram, We Observe That The Rod Diameter Is Approximately Normally DistributedDocument5 pagesQ.1 From The Histogram, We Observe That The Rod Diameter Is Approximately Normally DistributedPandurang ThatkarNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Patel Manuscript 28 AugustDocument11 pagesPatel Manuscript 28 AugustPandurang ThatkarNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Problems Need Help On 2Document9 pagesProblems Need Help On 2Pandurang Thatkar100% (1)
- OThompson - WK4AssgnOThompson - Zero For This Assignment - Please Redo. ThanksDocument4 pagesOThompson - WK4AssgnOThompson - Zero For This Assignment - Please Redo. ThanksPandurang ThatkarNo ratings yet
- MGT203Document26 pagesMGT203Pandurang Thatkar100% (1)
- New Data Internet UsageDocument6 pagesNew Data Internet UsagePandurang ThatkarNo ratings yet
- Omar Thompson Week2 Discussion1Document2 pagesOmar Thompson Week2 Discussion1Pandurang ThatkarNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Question: Is The Graduation Rate Higher at Hbcus or Non-Hbcus For Women Compared To Men?Document5 pagesQuestion: Is The Graduation Rate Higher at Hbcus or Non-Hbcus For Women Compared To Men?Pandurang ThatkarNo ratings yet
- New Data Internet UsageDocument6 pagesNew Data Internet UsagePandurang ThatkarNo ratings yet
- MGT203Document26 pagesMGT203Pandurang Thatkar100% (1)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- MarkDocument2 pagesMarkPandurang ThatkarNo ratings yet
- Moh SolutionDocument11 pagesMoh SolutionPandurang ThatkarNo ratings yet
- Generating A Binomial Distribution With Parameters N 10 and P 0.63Document4 pagesGenerating A Binomial Distribution With Parameters N 10 and P 0.63Pandurang ThatkarNo ratings yet
- Discussion Week2:: For Texture Classification," 3rd International Workshop On Texture Analysis and SynthesisDocument1 pageDiscussion Week2:: For Texture Classification," 3rd International Workshop On Texture Analysis and SynthesisPandurang ThatkarNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Homework 2Document4 pagesHomework 2Pandurang ThatkarNo ratings yet
- Basic Statistics Mcqs For Pcs ExamsDocument4 pagesBasic Statistics Mcqs For Pcs ExamsSirajRahmdil100% (1)
- Genetic DriftDocument4 pagesGenetic DriftjscribdscribdNo ratings yet
- 1 Normality PDFDocument5 pages1 Normality PDFDavid WongNo ratings yet
- Mca4020 SLM Unit 11Document23 pagesMca4020 SLM Unit 11AppTest PINo ratings yet
- 05-History of Census in IndiaDocument10 pages05-History of Census in IndiaRajan DubeyNo ratings yet
- En Demographic Research 2016 2Document209 pagesEn Demographic Research 2016 2Mohammed Al DaqsNo ratings yet
- Statistics Khan AcademyDocument4 pagesStatistics Khan AcademyKumardeep MukhopadhyayNo ratings yet
- LigaoDocument3 pagesLigaoErold TarvinaNo ratings yet
- Birth Rates PDFDocument2 pagesBirth Rates PDFAndreas SichoneNo ratings yet
- Chi Square TestDocument7 pagesChi Square TestSkandhaprakash MuraliNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- DH ST ArunachalDocument5 pagesDH ST Arunachal'Aamar NidoNo ratings yet
- ABC News/Ipsos Poll Feb 7Document4 pagesABC News/Ipsos Poll Feb 7ABC News Politics67% (3)
- An Official Census 2011 Detail of MeerutDocument9 pagesAn Official Census 2011 Detail of MeerutVishal AnandNo ratings yet
- NSCB Resolution No. 9 Series of 2003Document3 pagesNSCB Resolution No. 9 Series of 2003theengineer3100% (4)
- Pews Final 2012 Political PollDocument51 pagesPews Final 2012 Political PollChuck NessNo ratings yet
- MTH 157 Fall 2015 Homework FiveDocument4 pagesMTH 157 Fall 2015 Homework FivecaryNo ratings yet
- 2006 Sample Matching Representative Sampling From Internet PanelsDocument9 pages2006 Sample Matching Representative Sampling From Internet PanelsShu AmyNo ratings yet
- Population Growth in IndiaDocument13 pagesPopulation Growth in IndiaAbhishek JaniNo ratings yet
- Binomial Amity II SemesterDocument2 pagesBinomial Amity II SemesterAniket SinghNo ratings yet
- 01.a.demographic Projections - Aslam MahmoodDocument51 pages01.a.demographic Projections - Aslam MahmoodMaulikJoshiNo ratings yet
- BGY3701 Biostatistics Eda Practical: Group MembersDocument13 pagesBGY3701 Biostatistics Eda Practical: Group MembersKong PatrickNo ratings yet
- Pa-4 1649Document4 pagesPa-4 1649Soham GuptaNo ratings yet
- Homework 4: STAT 110 B, Probability & Statistics For Engineers II UCLA Statistics, Spring 2003Document2 pagesHomework 4: STAT 110 B, Probability & Statistics For Engineers II UCLA Statistics, Spring 2003rohitrgt4uNo ratings yet
- 2017 Census of Pakistan - WikipediaDocument5 pages2017 Census of Pakistan - WikipediaAzeemChaudharyNo ratings yet
- 16-Sampling Designs and ProceduresDocument27 pages16-Sampling Designs and ProceduresAbdalelah FrarjehNo ratings yet
- Estimation Sample Statistics Are Used To Estimate Population ParametersDocument2 pagesEstimation Sample Statistics Are Used To Estimate Population ParametersAnthea ClarkeNo ratings yet
- Point EstimationDocument13 pagesPoint EstimationTarun Goyal100% (1)
- Watertown Housing StudyDocument176 pagesWatertown Housing StudyWatertown Daily TimesNo ratings yet
- Open IntroDocument80 pagesOpen IntroMANOJ KUMARNo ratings yet
- MPAA Theatrical Market Statistics 2011Document21 pagesMPAA Theatrical Market Statistics 2011ArthawkNo ratings yet
- The One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsFrom EverandThe One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsRating: 4.5 out of 5 stars4.5/5 (709)
- Summary of Atomic Habits: An Easy and Proven Way to Build Good Habits and Break Bad Ones by James ClearFrom EverandSummary of Atomic Habits: An Easy and Proven Way to Build Good Habits and Break Bad Ones by James ClearRating: 4.5 out of 5 stars4.5/5 (559)
- Eat That Frog!: 21 Great Ways to Stop Procrastinating and Get More Done in Less TimeFrom EverandEat That Frog!: 21 Great Ways to Stop Procrastinating and Get More Done in Less TimeRating: 4.5 out of 5 stars4.5/5 (3226)
- No Bad Parts: Healing Trauma and Restoring Wholeness with the Internal Family Systems ModelFrom EverandNo Bad Parts: Healing Trauma and Restoring Wholeness with the Internal Family Systems ModelRating: 5 out of 5 stars5/5 (4)
- Indistractable: How to Control Your Attention and Choose Your LifeFrom EverandIndistractable: How to Control Your Attention and Choose Your LifeRating: 3 out of 5 stars3/5 (5)
- Summary of The 48 Laws of Power by Robert GreeneFrom EverandSummary of The 48 Laws of Power by Robert GreeneRating: 4.5 out of 5 stars4.5/5 (36)
- The 5 Second Rule: Transform your Life, Work, and Confidence with Everyday CourageFrom EverandThe 5 Second Rule: Transform your Life, Work, and Confidence with Everyday CourageRating: 5 out of 5 stars5/5 (9)
- Think This, Not That: 12 Mindshifts to Breakthrough Limiting Beliefs and Become Who You Were Born to BeFrom EverandThink This, Not That: 12 Mindshifts to Breakthrough Limiting Beliefs and Become Who You Were Born to BeRating: 2 out of 5 stars2/5 (1)