You might also like
- Fabrication of High Speed Indication and Automatic Pneumatic Braking SystemDocument7 pagesFabrication of High Speed Indication and Automatic Pneumatic Braking Systemseventhsensegroup0% (1)
- Implementation of Single Stage Three Level Power Factor Correction AC-DC Converter With Phase Shift ModulationDocument6 pagesImplementation of Single Stage Three Level Power Factor Correction AC-DC Converter With Phase Shift ModulationseventhsensegroupNo ratings yet
- Design, Development and Performance Evaluation of Solar Dryer With Mirror Booster For Red Chilli (Capsicum Annum)Document7 pagesDesign, Development and Performance Evaluation of Solar Dryer With Mirror Booster For Red Chilli (Capsicum Annum)seventhsensegroupNo ratings yet
- Ijett V5N1P103Document4 pagesIjett V5N1P103Yosy NanaNo ratings yet
- FPGA Based Design and Implementation of Image Edge Detection Using Xilinx System GeneratorDocument4 pagesFPGA Based Design and Implementation of Image Edge Detection Using Xilinx System GeneratorseventhsensegroupNo ratings yet
- An Efficient and Empirical Model of Distributed ClusteringDocument5 pagesAn Efficient and Empirical Model of Distributed ClusteringseventhsensegroupNo ratings yet
- Non-Linear Static Analysis of Multi-Storied BuildingDocument5 pagesNon-Linear Static Analysis of Multi-Storied Buildingseventhsensegroup100% (1)
- Design and Implementation of Multiple Output Switch Mode Power SupplyDocument6 pagesDesign and Implementation of Multiple Output Switch Mode Power SupplyseventhsensegroupNo ratings yet
- Experimental Analysis of Tobacco Seed Oil Blends With Diesel in Single Cylinder Ci-EngineDocument5 pagesExperimental Analysis of Tobacco Seed Oil Blends With Diesel in Single Cylinder Ci-EngineseventhsensegroupNo ratings yet
- Ijett V4i10p158Document6 pagesIjett V4i10p158pradeepjoshi007No ratings yet
- Analysis of The Fixed Window Functions in The Fractional Fourier DomainDocument7 pagesAnalysis of The Fixed Window Functions in The Fractional Fourier DomainseventhsensegroupNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Kina23744ens 002-Seisracks1Document147 pagesKina23744ens 002-Seisracks1Adrian_Condrea_4281No ratings yet
- Vertical Axis Wind Turbine ProjDocument2 pagesVertical Axis Wind Turbine Projmacsan sanchezNo ratings yet
- Cubic FunctionsDocument9 pagesCubic FunctionsShrey JainNo ratings yet
- Meeting Wise Agenda TemplateDocument1 pageMeeting Wise Agenda Templateapi-416923934No ratings yet
- Limitations of The Study - Docx EMDocument1 pageLimitations of The Study - Docx EMthreeNo ratings yet
- Kelompok 5Document16 pagesKelompok 5bintangNo ratings yet
- Cambridge IGCSE ™: Co-Ordinated Sciences 0654/61 October/November 2022Document9 pagesCambridge IGCSE ™: Co-Ordinated Sciences 0654/61 October/November 2022wangfeifei620No ratings yet
- PERFORM Toolkit 3 1 Release Notes 1.0 OnlinePDFDocument18 pagesPERFORM Toolkit 3 1 Release Notes 1.0 OnlinePDFJose HugoNo ratings yet
- Marvel Science StoriesDocument4 pagesMarvel Science StoriesPersonal trainerNo ratings yet
- Property PalleteDocument5 pagesProperty PalletePranay PatelNo ratings yet
- KRAWIEC, Representations of Monastic Clothing in Late AntiquityDocument27 pagesKRAWIEC, Representations of Monastic Clothing in Late AntiquityDejan MitreaNo ratings yet
- 01CDT00330 - Lakeshore - 330 - ManualDocument104 pages01CDT00330 - Lakeshore - 330 - ManualSPMS_MELECNo ratings yet
- Assignment 2: Question 1: Predator-Prey ModelDocument2 pagesAssignment 2: Question 1: Predator-Prey ModelKhan Mohd SaalimNo ratings yet
- Kaizen Idea - Sheet: Suitable Chairs To Write Their Notes Faster & Easy Method While TrainingDocument1 pageKaizen Idea - Sheet: Suitable Chairs To Write Their Notes Faster & Easy Method While TrainingWahid AkramNo ratings yet
- A Science Lesson Plan Analysis Instrument For Formative and Summative Program Evaluation of A Teacher Education ProgramDocument31 pagesA Science Lesson Plan Analysis Instrument For Formative and Summative Program Evaluation of A Teacher Education ProgramTiara Kurnia KhoerunnisaNo ratings yet
- Gd&t-Multi MetricsDocument356 pagesGd&t-Multi MetricsdramiltNo ratings yet
- 2pages 6Document3 pages2pages 6Rachana G Y Rachana G YNo ratings yet
- EnglishFile4e Intermediate Plus TG PCM Vocab 1BDocument1 pageEnglishFile4e Intermediate Plus TG PCM Vocab 1Bayşe adaliNo ratings yet
- Research QuestionDocument6 pagesResearch QuestionAlfian Ardhiyana PutraNo ratings yet
- Tcps 2 Final WebDocument218 pagesTcps 2 Final WebBornaGhannadiNo ratings yet
- JurnalDocument24 pagesJurnaltsania rahmaNo ratings yet
- A Modified Newton's Method For Solving Nonlinear Programing ProblemsDocument15 pagesA Modified Newton's Method For Solving Nonlinear Programing Problemsjhon jairo portillaNo ratings yet
- Physics For EngineersDocument5 pagesPhysics For EngineersKonstantinos FilippakosNo ratings yet
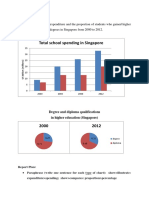
- Total School Spending in Singapore: Task 1 020219Document6 pagesTotal School Spending in Singapore: Task 1 020219viper_4554No ratings yet
- InheretanceDocument8 pagesInheretancefarhan.mukhtiarNo ratings yet
- Collaborative Planning Template W CaptionDocument5 pagesCollaborative Planning Template W Captionapi-297728751No ratings yet
- Business Cognate SBADocument20 pagesBusiness Cognate SBAUncle TravisNo ratings yet
- Internship Report On Service IndustryDocument50 pagesInternship Report On Service Industrybbaahmad89No ratings yet
- Gerin Bagaslino - 52417512Document13 pagesGerin Bagaslino - 52417512Gerin BagaslinoNo ratings yet
- JAIM InstructionsDocument11 pagesJAIM InstructionsAlphaRaj Mekapogu100% (1)