You might also like
- Assessment Formal AssessmentDocument7 pagesAssessment Formal Assessmentashish33% (3)
- Data MininginhealthcareDocument13 pagesData Mininginhealthcaremonkeydluffy161280No ratings yet
- IJCRT2205103Document10 pagesIJCRT2205103Ananya DhuriaNo ratings yet
- A Survey On Machine Learning Assisted Big Data Analysis For Health Care DomainDocument5 pagesA Survey On Machine Learning Assisted Big Data Analysis For Health Care DomainTonyNo ratings yet
- Heart PredictionDocument15 pagesHeart PredictionKinshuk JoshiNo ratings yet
- Feature Selection For Classification in Medical Data Mining: Volume 2, Issue 2, March - April 2013Document6 pagesFeature Selection For Classification in Medical Data Mining: Volume 2, Issue 2, March - April 2013International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- 2017 Data Mining ToolsDocument4 pages2017 Data Mining ToolsPathivadaSantoshNaiduNo ratings yet
- 2017DataMiningTools PDFDocument4 pages2017DataMiningTools PDFPathivadaSantoshNaiduNo ratings yet
- 2017 Data Mining ToolsDocument4 pages2017 Data Mining ToolsHendra Nusa PutraNo ratings yet
- Mining Techniques in Health Care: A Survey of ImmunizationDocument6 pagesMining Techniques in Health Care: A Survey of ImmunizationseventhsensegroupNo ratings yet
- Prognosis of Cardiac Disease Using Data Mining Techniques A Comprehensive SurveyDocument5 pagesPrognosis of Cardiac Disease Using Data Mining Techniques A Comprehensive SurveyEditor IJTSRDNo ratings yet
- A Comparative Study of Classification Algorithms For Diseases Prediction in Medical DomainDocument5 pagesA Comparative Study of Classification Algorithms For Diseases Prediction in Medical DomainMohammed HusseinNo ratings yet
- (IJCST-V10I5P44) :mrs J Sarada, Yeddula PavaniDocument5 pages(IJCST-V10I5P44) :mrs J Sarada, Yeddula PavaniEighthSenseGroupNo ratings yet
- Data Mining Classification Algorithms For Kidney Disease PredictionDocument13 pagesData Mining Classification Algorithms For Kidney Disease PredictionJames MorenoNo ratings yet
- CKD PDFDocument13 pagesCKD PDFsanjayNo ratings yet
- Heart Disease Prediction Using Classification Techniques in Machine LearningDocument4 pagesHeart Disease Prediction Using Classification Techniques in Machine LearningRony sahaNo ratings yet
- Prediction of Stroke Using Deep Learning Model: October 2017Document10 pagesPrediction of Stroke Using Deep Learning Model: October 2017darNo ratings yet
- 20080849Document8 pages20080849Fikhri AbduhanNo ratings yet
- Hybrid Model For Clinical Diagnosis and Treatment Using Data Mining TechniquesDocument4 pagesHybrid Model For Clinical Diagnosis and Treatment Using Data Mining TechniquestheijesNo ratings yet
- Survey On Predictive Medical Data Analysis Using Pattern Recognition AlgorithmDocument7 pagesSurvey On Predictive Medical Data Analysis Using Pattern Recognition AlgorithmAdarsh SureshNo ratings yet
- Key Terms of EHRs and Examples in Various Types of Care SettingsDocument10 pagesKey Terms of EHRs and Examples in Various Types of Care SettingsDariaZhuravlevaNo ratings yet
- A Survey On Data Mining Approaches For HealthcareDocument26 pagesA Survey On Data Mining Approaches For HealthcareHandsome RobNo ratings yet
- Mining of Sensor DataDocument46 pagesMining of Sensor Datasarafnexus4No ratings yet
- The Role of Big Data Analytics in Hospital Management SystemDocument6 pagesThe Role of Big Data Analytics in Hospital Management SystemAsora Yasmin snehaNo ratings yet
- 10 11648 J Ajcst 20220503 11Document10 pages10 11648 J Ajcst 20220503 11rahul suryawanshiNo ratings yet
- Breast Cancer Diagnosis and Prognosis Using Data Mining TechniquesDocument8 pagesBreast Cancer Diagnosis and Prognosis Using Data Mining TechniquesSasa TrifkovicNo ratings yet
- Classification of Diabetes Disease Using Support Vector MachineDocument6 pagesClassification of Diabetes Disease Using Support Vector MachineTracker DeathNo ratings yet
- What Is Data Mining?: 1. Classification AnalysisDocument5 pagesWhat Is Data Mining?: 1. Classification AnalysisJunaid AhnafNo ratings yet
- Bda Cac1Document3 pagesBda Cac1vaishnav.srivastavaNo ratings yet
- Intelligent Heart Disease Prediction Using Data Mining TechniquesDocument7 pagesIntelligent Heart Disease Prediction Using Data Mining TechniquesVMSMULLAINATHANNo ratings yet
- Machine Learning Prediction of Coronary Heart DiseaseDocument6 pagesMachine Learning Prediction of Coronary Heart DiseaseNowreen HaqueNo ratings yet
- Data Mining in MedicineDocument42 pagesData Mining in MedicineAna-Maria RaileanuNo ratings yet
- Design and Implementing Heart Disease Prediction Using Naives Bayesian Dept. of CseDocument16 pagesDesign and Implementing Heart Disease Prediction Using Naives Bayesian Dept. of CseDakamma DakaNo ratings yet
- K-Means and MAP REDUCE AlgorithmDocument9 pagesK-Means and MAP REDUCE AlgorithmjefferyleclercNo ratings yet
- Heart Disease Prediction Using Machine Learning Techniques: Devansh Shah Samir Patel Santosh Kumar BhartiDocument6 pagesHeart Disease Prediction Using Machine Learning Techniques: Devansh Shah Samir Patel Santosh Kumar Bhartifuck MeNo ratings yet
- 1 s2.0 S2214785321052202 MainDocument4 pages1 s2.0 S2214785321052202 MainTusher Kumar SahaNo ratings yet
- Implementing Clinical Decision Support System Using Naïve Bayesian ClassifierDocument6 pagesImplementing Clinical Decision Support System Using Naïve Bayesian ClassifierEditor IJRITCCNo ratings yet
- Privacy Preserving Classification of Clinical Data Using Homomorphic Encryption IJERTCONV3IS12027Document6 pagesPrivacy Preserving Classification of Clinical Data Using Homomorphic Encryption IJERTCONV3IS12027chandravathiNo ratings yet
- Heart Disease Prediction Using Data MiningDocument3 pagesHeart Disease Prediction Using Data MiningAnonymous CUPykm6DZNo ratings yet
- A Fuzzy Based Association Mining Approach For Medical Disease PredictionDocument3 pagesA Fuzzy Based Association Mining Approach For Medical Disease PredictionIJERDNo ratings yet
- Text Recognition Past, Present and FutureDocument7 pagesText Recognition Past, Present and FutureEditor IJRITCCNo ratings yet
- Data Science in HealthcareDocument5 pagesData Science in HealthcareEditor IJTSRDNo ratings yet
- Chapter - 1: Dept of CSE, AITAM, Tekkali (Autonomous) Pg. 1Document29 pagesChapter - 1: Dept of CSE, AITAM, Tekkali (Autonomous) Pg. 1laxmanaNo ratings yet
- Data Mining and Knowledge Discovery: Applications, Techniques, Challenges and Process Models in HealthcareDocument7 pagesData Mining and Knowledge Discovery: Applications, Techniques, Challenges and Process Models in Healthcareraj1o1oNo ratings yet
- Health Big Data Analytics: A Technology SurveyDocument18 pagesHealth Big Data Analytics: A Technology SurveyRitesh SharmaNo ratings yet
- Ijcet: International Journal of Computer Engineering & Technology (Ijcet)Document11 pagesIjcet: International Journal of Computer Engineering & Technology (Ijcet)IAEME PublicationNo ratings yet
- Importance of Data Mining in Healthcare A SurveyDocument6 pagesImportance of Data Mining in Healthcare A SurveybenNo ratings yet
- An Optimized Approach For Prediction of Heart Diseases Using Gradient Boosting ClassifierDocument7 pagesAn Optimized Approach For Prediction of Heart Diseases Using Gradient Boosting ClassifierInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- An Optimized Approach For Prediction of Heart Diseases Using Gradient Boosting ClassifierDocument7 pagesAn Optimized Approach For Prediction of Heart Diseases Using Gradient Boosting ClassifierInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- A Survey On Clustering Techniques in Medical DiagnosisDocument6 pagesA Survey On Clustering Techniques in Medical DiagnosisEighthSenseGroupNo ratings yet
- Disease Prediction System Using Machine LearningDocument4 pagesDisease Prediction System Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Computer Aided DiagnosisDocument21 pagesComputer Aided DiagnosisChief PriestNo ratings yet
- Prediction of Diabetes Using Machine LearningDocument6 pagesPrediction of Diabetes Using Machine LearningGoutham NNo ratings yet
- Analysis of Research in Healthcare Data Analytics - SathyabamaDocument43 pagesAnalysis of Research in Healthcare Data Analytics - SathyabamaDäzzlîñg HärîshNo ratings yet
- Rohit Manna SEM3 CA2 MSD303 MSC (DA)Document4 pagesRohit Manna SEM3 CA2 MSD303 MSC (DA)Corvas UniqueNo ratings yet
- 2016 Springer HandbookDocument38 pages2016 Springer HandbookssgantayatNo ratings yet
- Heart Disease PredictionUsingDocument6 pagesHeart Disease PredictionUsingNationalinstituteDsnrNo ratings yet
- Three Dimensional Model For Diagnostic Prediction: A Data Mining ApproachDocument5 pagesThree Dimensional Model For Diagnostic Prediction: A Data Mining ApproachInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Edited Version of Cardiovascular Diseases Risk Prediction Dataset ReportDocument25 pagesEdited Version of Cardiovascular Diseases Risk Prediction Dataset ReportInderpaal SinghNo ratings yet
- Clustering Algorithms For Analysing Electronic Medical Record: A Mapping StudyDocument9 pagesClustering Algorithms For Analysing Electronic Medical Record: A Mapping StudyIAES IJAINo ratings yet
- Clinical Decision Support System: Fundamentals and ApplicationsFrom EverandClinical Decision Support System: Fundamentals and ApplicationsNo ratings yet
- (IJCST-V12I1P7) :tejinder Kaur, Jimmy SinglaDocument26 pages(IJCST-V12I1P7) :tejinder Kaur, Jimmy SinglaEighthSenseGroupNo ratings yet
- (IJCST-V12I1P4) :M. Sharmila, Dr. M. NatarajanDocument9 pages(IJCST-V12I1P4) :M. Sharmila, Dr. M. NatarajanEighthSenseGroupNo ratings yet
- (IJCST-V11I4P15) :M. I. Elalami, A. E. Amin, S. A. ElsaghierDocument8 pages(IJCST-V11I4P15) :M. I. Elalami, A. E. Amin, S. A. ElsaghierEighthSenseGroupNo ratings yet
- (IJCST-V11I4P5) :P Jayachandran, P.M Kavitha, Aravind R, S Hari, PR NithishwaranDocument4 pages(IJCST-V11I4P5) :P Jayachandran, P.M Kavitha, Aravind R, S Hari, PR NithishwaranEighthSenseGroupNo ratings yet
- (IJCST-V11I6P8) :subhadip KumarDocument7 pages(IJCST-V11I6P8) :subhadip KumarEighthSenseGroupNo ratings yet
- (IJCST-V11I3P25) :pooja Patil, Swati J. PatelDocument5 pages(IJCST-V11I3P25) :pooja Patil, Swati J. PatelEighthSenseGroupNo ratings yet
- (IJCST-V11I6P5) :A.E.E. El-Alfi, M. E. A. Awad, F. A. A. KhalilDocument9 pages(IJCST-V11I6P5) :A.E.E. El-Alfi, M. E. A. Awad, F. A. A. KhalilEighthSenseGroupNo ratings yet
- (IJCST-V12I1P2) :DR .Elham Hamed HASSAN, Eng - Rahaf Mohamad WANNOUSDocument11 pages(IJCST-V12I1P2) :DR .Elham Hamed HASSAN, Eng - Rahaf Mohamad WANNOUSEighthSenseGroupNo ratings yet
- (IJCST-V11I6P8) :subhadip KumarDocument7 pages(IJCST-V11I6P8) :subhadip KumarEighthSenseGroupNo ratings yet
- (IJCST-V11I5P4) :abhirenjini K A, Candiz Rozario, Kripa Treasa, Juvariya Yoosuf, Vidya HariDocument7 pages(IJCST-V11I5P4) :abhirenjini K A, Candiz Rozario, Kripa Treasa, Juvariya Yoosuf, Vidya HariEighthSenseGroupNo ratings yet
- (IJCST-V11I4P9) :KiranbenV - Patel, Megha R. Dave, Dr. Harshadkumar P. PatelDocument18 pages(IJCST-V11I4P9) :KiranbenV - Patel, Megha R. Dave, Dr. Harshadkumar P. PatelEighthSenseGroupNo ratings yet
- (IJCST-V11I4P12) :N. Kalyani, G. Pradeep Reddy, K. SandhyaDocument16 pages(IJCST-V11I4P12) :N. Kalyani, G. Pradeep Reddy, K. SandhyaEighthSenseGroupNo ratings yet
- (Ijcst-V11i4p1) :fidaa Zayna, Waddah HatemDocument8 pages(Ijcst-V11i4p1) :fidaa Zayna, Waddah HatemEighthSenseGroupNo ratings yet
- (IJCST-V11I4P3) :tankou Tsomo Maurice Eddy, Bell Bitjoka Georges, Ngohe Ekam Paul SalomonDocument9 pages(IJCST-V11I4P3) :tankou Tsomo Maurice Eddy, Bell Bitjoka Georges, Ngohe Ekam Paul SalomonEighthSenseGroupNo ratings yet
- (IJCST-V11I3P20) :helmi Mulyadi, Fajar MasyaDocument8 pages(IJCST-V11I3P20) :helmi Mulyadi, Fajar MasyaEighthSenseGroupNo ratings yet
- (IJCST-V11I3P21) :ms. Deepali Bhimrao Chavan, Prof. Suraj Shivaji RedekarDocument4 pages(IJCST-V11I3P21) :ms. Deepali Bhimrao Chavan, Prof. Suraj Shivaji RedekarEighthSenseGroupNo ratings yet
- (IJCST-V11I3P17) :yash Vishwakarma, Akhilesh A. WaooDocument8 pages(IJCST-V11I3P17) :yash Vishwakarma, Akhilesh A. WaooEighthSenseGroupNo ratings yet
- (IJCST-V11I3P24) :R.Senthilkumar, Dr. R. SankarasubramanianDocument7 pages(IJCST-V11I3P24) :R.Senthilkumar, Dr. R. SankarasubramanianEighthSenseGroupNo ratings yet
- (IJCST-V11I3P13) : Binele Abana Alphonse, Abou Loume Gautier, Djimeli Dtiabou Berline, Bavoua Kenfack Patrick Dany, Tonye EmmanuelDocument31 pages(IJCST-V11I3P13) : Binele Abana Alphonse, Abou Loume Gautier, Djimeli Dtiabou Berline, Bavoua Kenfack Patrick Dany, Tonye EmmanuelEighthSenseGroupNo ratings yet
- (IJCST-V11I3P12) :prabhjot Kaur, Rupinder Singh, Rachhpal SinghDocument6 pages(IJCST-V11I3P12) :prabhjot Kaur, Rupinder Singh, Rachhpal SinghEighthSenseGroupNo ratings yet
- (IJCST-V11I3P7) :nikhil K. Pawanikar, R. SrivaramangaiDocument15 pages(IJCST-V11I3P7) :nikhil K. Pawanikar, R. SrivaramangaiEighthSenseGroupNo ratings yet
- (IJCST-V11I3P11) :Kalaiselvi.P, Vasanth.G, Aravinth.P, Elamugilan.A, Prasanth.SDocument4 pages(IJCST-V11I3P11) :Kalaiselvi.P, Vasanth.G, Aravinth.P, Elamugilan.A, Prasanth.SEighthSenseGroupNo ratings yet
- (IJCST-V11I3P2) :K.Vivek, P.Kashi Naga Jyothi, G.Venkatakiran, SK - ShaheedDocument4 pages(IJCST-V11I3P2) :K.Vivek, P.Kashi Naga Jyothi, G.Venkatakiran, SK - ShaheedEighthSenseGroupNo ratings yet
- (IJCST-V11I3P9) :raghu Ram Chowdary VelevelaDocument6 pages(IJCST-V11I3P9) :raghu Ram Chowdary VelevelaEighthSenseGroupNo ratings yet
- (IJCST-V11I3P5) :P Adhi Lakshmi, M Tharak Ram, CH Sai Teja, M Vamsi Krishna, S Pavan MalyadriDocument4 pages(IJCST-V11I3P5) :P Adhi Lakshmi, M Tharak Ram, CH Sai Teja, M Vamsi Krishna, S Pavan MalyadriEighthSenseGroupNo ratings yet
- (IJCST-V11I2P18) :hanadi Yahya DarwishoDocument32 pages(IJCST-V11I2P18) :hanadi Yahya DarwishoEighthSenseGroupNo ratings yet
- (IJCST-V11I3P8) :pooja Patil, Swati J. PatelDocument5 pages(IJCST-V11I3P8) :pooja Patil, Swati J. PatelEighthSenseGroupNo ratings yet
- (IJCST-V11I3P4) :V Ramya, A Sai Deepika, K Rupa, M Leela Krishna, I Satya GirishDocument4 pages(IJCST-V11I3P4) :V Ramya, A Sai Deepika, K Rupa, M Leela Krishna, I Satya GirishEighthSenseGroupNo ratings yet
- (IJCST-V11I3P1) :Dr.P.Bhaskar Naidu, P.Mary Harika, J.Pavani, B.Divyadhatri, J.ChandanaDocument4 pages(IJCST-V11I3P1) :Dr.P.Bhaskar Naidu, P.Mary Harika, J.Pavani, B.Divyadhatri, J.ChandanaEighthSenseGroupNo ratings yet
- (IJCST-V11I2P19) :nikhil K. Pawanika, R. SrivaramangaiDocument15 pages(IJCST-V11I2P19) :nikhil K. Pawanika, R. SrivaramangaiEighthSenseGroupNo ratings yet
- TDS Versimax HD4 15W40Document1 pageTDS Versimax HD4 15W40Amaraa DNo ratings yet
- Q1 Tle 4 (Ict)Document34 pagesQ1 Tle 4 (Ict)Jake Role GusiNo ratings yet
- Tumors of The Central Nervous System - VOL 12Document412 pagesTumors of The Central Nervous System - VOL 12vitoNo ratings yet
- Proper restraint techniques for dogs and catsDocument153 pagesProper restraint techniques for dogs and catsjademattican75% (4)
- Diagnostic and Statistical Manual of Mental Disorders: Distinction From ICD Pre-DSM-1 (1840-1949)Document25 pagesDiagnostic and Statistical Manual of Mental Disorders: Distinction From ICD Pre-DSM-1 (1840-1949)Unggul YudhaNo ratings yet
- Quality ImprovementDocument3 pagesQuality ImprovementViky SinghNo ratings yet
- OilDocument8 pagesOilwuacbekirNo ratings yet
- Vaginal Examinations in Labour GuidelineDocument2 pagesVaginal Examinations in Labour GuidelinePooneethawathi Santran100% (1)
- Catherineresume 2Document3 pagesCatherineresume 2api-302133133No ratings yet
- December - Cost of Goods Sold (Journal)Document14 pagesDecember - Cost of Goods Sold (Journal)kuro hanabusaNo ratings yet
- Impact of Energy Consumption On The EnvironmentDocument9 pagesImpact of Energy Consumption On The Environmentadawiyah sofiNo ratings yet
- FileDocument284 pagesFileJesse GarciaNo ratings yet
- Insects, Stings and BitesDocument5 pagesInsects, Stings and BitesHans Alfonso ThioritzNo ratings yet
- of Types of Nuclear ReactorDocument33 pagesof Types of Nuclear Reactormandhir67% (3)
- AZ ATTR Concept Test Clean SCREENERDocument9 pagesAZ ATTR Concept Test Clean SCREENEREdwin BennyNo ratings yet
- G10 Bio CellsDocument6 pagesG10 Bio CellsswacaneNo ratings yet
- Parasitology Lecture Hosts, Symbiosis & TransmissionDocument10 pagesParasitology Lecture Hosts, Symbiosis & TransmissionPatricia Ann JoseNo ratings yet
- How To Practice Self Care - WikiHowDocument7 pagesHow To Practice Self Care - WikiHowВасе АнѓелескиNo ratings yet
- AYUSHMAN BHARAT Operationalizing Health and Wellness CentresDocument34 pagesAYUSHMAN BHARAT Operationalizing Health and Wellness CentresDr. Sachendra Raj100% (1)
- Merit of RatingDocument1 pageMerit of RatingRaidasNo ratings yet
- ASR1201D ASR1201D-D: Slim Water-Proof RFID ReaderDocument1 pageASR1201D ASR1201D-D: Slim Water-Proof RFID ReaderCatalin BailescuNo ratings yet
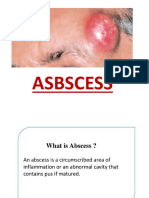
- ABSCESSDocument35 pagesABSCESSlax prajapatiNo ratings yet
- English III Module 2 Simple Present Job and Job VerbsDocument4 pagesEnglish III Module 2 Simple Present Job and Job VerbsAdrian CortesNo ratings yet
- Cfm56-3 Engine Regulation by CFMDocument43 pagesCfm56-3 Engine Regulation by CFMnono92100% (5)
- C. Drug Action 1Document28 pagesC. Drug Action 1Jay Eamon Reyes MendrosNo ratings yet
- IMCI Chart 2014 EditionDocument80 pagesIMCI Chart 2014 EditionHarold DiasanaNo ratings yet
- OC - PlumberDocument6 pagesOC - Plumbertakuva03No ratings yet
- 05 AcknowledgementDocument2 pages05 AcknowledgementNishant KushwahaNo ratings yet
- DVAIO R3 PRO HD Sound Quality In-Ear Wired Earphone Amazon - in ElectronicsDocument1 pageDVAIO R3 PRO HD Sound Quality In-Ear Wired Earphone Amazon - in Electronicsdinple sharmaNo ratings yet