You might also like
- Install Hadoop Cluster GuideDocument9 pagesInstall Hadoop Cluster GuideS.Hanumanth SastryNo ratings yet
- Tutorial of Crystal Dashboard PDFDocument12 pagesTutorial of Crystal Dashboard PDFS.Hanumanth SastryNo ratings yet
- Optimizing Value in Process ManufacturingDocument13 pagesOptimizing Value in Process ManufacturingS.Hanumanth SastryNo ratings yet
- Building R PackagesDocument52 pagesBuilding R PackagesS.Hanumanth SastryNo ratings yet
- Fosser Leister Moe NewmanDocument13 pagesFosser Leister Moe NewmanElham KeimaneshNo ratings yet
- Big Data Tutorial Part4Document41 pagesBig Data Tutorial Part4476No ratings yet
- DwhschemaDocument10 pagesDwhschemaS.Hanumanth SastryNo ratings yet
- Wict2011 Submission 171Document6 pagesWict2011 Submission 171S.Hanumanth SastryNo ratings yet
- Sample Ieee PaperDocument2 pagesSample Ieee PaperVinay S BelieveurinstinctsNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- JK Cement Market and Price AnalysisDocument99 pagesJK Cement Market and Price Analysisrahulsogani123No ratings yet
- Securities and Exchange Commission Opinion 31 10Document11 pagesSecurities and Exchange Commission Opinion 31 10Cari Mangalindan MacaalayNo ratings yet
- Metallurgical Performance Analysis of Froth Flotation Plant From Material BalaneDocument18 pagesMetallurgical Performance Analysis of Froth Flotation Plant From Material Balanejoseph kafumbilaNo ratings yet
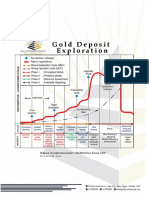
- Stages of An Exploration Project. (Modifted From Eimon 1988.)Document1 pageStages of An Exploration Project. (Modifted From Eimon 1988.)KareemAmenNo ratings yet
- Mining CableDocument68 pagesMining CableEasy Energy SACNo ratings yet
- GN - ART - T.Torries - 1995 - Comparative Costs of Nickel Sulphides and LateritesDocument9 pagesGN - ART - T.Torries - 1995 - Comparative Costs of Nickel Sulphides and LateritesEduardo CandelaNo ratings yet
- Pluton Resources PFS Irvine Island JORC Reserves and Cost Estimates - June 2011Document11 pagesPluton Resources PFS Irvine Island JORC Reserves and Cost Estimates - June 2011Lukas Allen ShermanNo ratings yet
- Invest in Zimbabwe CoalDocument52 pagesInvest in Zimbabwe CoalMahendra RajuNo ratings yet
- Book 2002Document177 pagesBook 2002Dario Vivanco HuaytaraNo ratings yet
- Mr. Jock O’Callaghan Global Mining Leader Contact Details and Mining Company ProfilesDocument21 pagesMr. Jock O’Callaghan Global Mining Leader Contact Details and Mining Company Profilesramesh50% (2)
- Is Panama To Be Latin America's Diamond Smuggling HubDocument5 pagesIs Panama To Be Latin America's Diamond Smuggling HubPanama Tierra RobadaNo ratings yet
- Waybill LimitDocument1,395 pagesWaybill LimitRaju MalhotraNo ratings yet
- VACANCY Technician-1-Ore-Control-2023Document2 pagesVACANCY Technician-1-Ore-Control-2023normanNo ratings yet
- ShaftsDocument9 pagesShaftsSumit JainNo ratings yet
- Extension On Prospecting LicenceDocument2 pagesExtension On Prospecting LicenceSherlock MasileNo ratings yet
- Through Seam Blasting: Project SummaryDocument2 pagesThrough Seam Blasting: Project SummaryRido Rezeki SitumorangNo ratings yet
- Mines Part-Ii PDFDocument466 pagesMines Part-Ii PDFushaNo ratings yet
- Sodium Chloride Production Methods and UsesDocument48 pagesSodium Chloride Production Methods and UsesNoee CassaniNo ratings yet
- Mineral Commodity Summaries 2013 by USGSDocument201 pagesMineral Commodity Summaries 2013 by USGSnationalminingNo ratings yet
- The Gold and Silver Mining Industry in Latin America and Its Global ReachDocument7 pagesThe Gold and Silver Mining Industry in Latin America and Its Global ReachArthur OppitzNo ratings yet
- Memorandum of Agreement DraftDocument3 pagesMemorandum of Agreement DraftJerry EnocNo ratings yet
- Comparative Analysis of Public and Private Sector Steel Companies in IndiaDocument47 pagesComparative Analysis of Public and Private Sector Steel Companies in IndiaGaurav TripathiNo ratings yet
- Organisation Study OS Report at CARBORUNDUM (CUMI)Document69 pagesOrganisation Study OS Report at CARBORUNDUM (CUMI)Ajeesh K Raju100% (2)
- Women in Artisinal and Small Scale Mining Uganda RecommendationsDocument2 pagesWomen in Artisinal and Small Scale Mining Uganda RecommendationsAfrica Centre for Energy and Mineral PolicyNo ratings yet
- 2018 FME TransactionsDocument9 pages2018 FME TransactionsEduardo Leal SalgadoNo ratings yet
- Mineral and Energy ResourcesDocument4 pagesMineral and Energy ResourcesJoseph ZotooNo ratings yet
- Kpi Octubre-2020Document4 pagesKpi Octubre-2020Juan De la cruz EncarnacionNo ratings yet
- Whittle Integrated Strategic Planning: ServicesDocument9 pagesWhittle Integrated Strategic Planning: ServicesEnkhchimeg SarankhuuNo ratings yet
- Data Warehouse & Business IntelligenceDocument25 pagesData Warehouse & Business Intelligenceramki073033No ratings yet
- CRM Guide: Customer Relationship Management EssentialsDocument108 pagesCRM Guide: Customer Relationship Management Essentialscrafne100% (1)