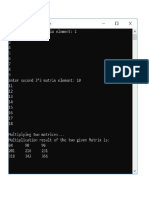
You might also like
- Module2 Ids 240201 162026Document11 pagesModule2 Ids 240201 162026sachinsachitha1321No ratings yet
- DA Exam PaperDocument6 pagesDA Exam PapercubililyNo ratings yet
- Identify Duplicate Questions on QuoraDocument41 pagesIdentify Duplicate Questions on Quoraaggarwal nNo ratings yet
- Course Mangement Class 12 Computer ProjectDocument13 pagesCourse Mangement Class 12 Computer ProjectPaneendra KumarNo ratings yet
- QUIZ MASTER Computer Science Class 12Document15 pagesQUIZ MASTER Computer Science Class 12humchaprihaiNo ratings yet
- Programing For Engineers Mini Project 1Document10 pagesPrograming For Engineers Mini Project 1Tiofelus H. HamutenyaNo ratings yet
- Quid-e-Azam Test Cs MphilDocument6 pagesQuid-e-Azam Test Cs MphilAbdul Rehman Janjua60% (10)
- Cs - Project - New Project On Mahesh HouseDocument24 pagesCs - Project - New Project On Mahesh Housemahi21911687No ratings yet
- CS Project 1Document21 pagesCS Project 1mahi21911687No ratings yet
- Working With Data: V Balachandra 19F41A0471Document17 pagesWorking With Data: V Balachandra 19F41A0471baluNo ratings yet
- Data SciDocument10 pagesData Sciharsat2030No ratings yet
- CS File CSVDocument22 pagesCS File CSVADESH PANWARNo ratings yet
- Shreyash Tiwari Projectclass12-CDocument20 pagesShreyash Tiwari Projectclass12-CShreyash TiwariNo ratings yet
- 3D Object Recognition: Koç UniversityDocument10 pages3D Object Recognition: Koç UniversityAlfan RizaldyNo ratings yet
- Application of Integration TechniquesDocument57 pagesApplication of Integration Techniquesaditya nimbalkarNo ratings yet
- Data Structures and Algorithms CS233Document27 pagesData Structures and Algorithms CS233Vijay BegtaNo ratings yet
- Ip Project Class 12Document21 pagesIp Project Class 12NOEL chackoNo ratings yet
- DNN ALL Practical 28Document34 pagesDNN ALL Practical 284073Himanshu PatleNo ratings yet
- March 2015 To July 2020 FULL PapersDocument110 pagesMarch 2015 To July 2020 FULL PapersWalker GamingNo ratings yet
- UCINET Visualization and Quantitative Analysis TutorialDocument53 pagesUCINET Visualization and Quantitative Analysis TutorialGerardo DamianNo ratings yet
- Hand Pose Recognition Project ReportDocument16 pagesHand Pose Recognition Project ReportVũ Hoàng LongNo ratings yet
- Realized Variance Software Package 0.8Document28 pagesRealized Variance Software Package 0.8elz0rr0No ratings yet
- K Mean++Document8 pagesK Mean++Syed Hamza Ibrar GillaniNo ratings yet
- MATLAB Central - File Exchange Pick of The Week Finding The Best Distribution That Fits The DataDocument2 pagesMATLAB Central - File Exchange Pick of The Week Finding The Best Distribution That Fits The DatawinsaravananNo ratings yet
- DSA Microproject ReportDocument4 pagesDSA Microproject ReportNutan BhorNo ratings yet
- International Open UniversityDocument10 pagesInternational Open UniversityMoh'd Khamis SongoroNo ratings yet
- Submitted To:-Mrs. Ritika Bisht (Pgt. CS) : Kendriya Vidyalaya UttarkashiDocument18 pagesSubmitted To:-Mrs. Ritika Bisht (Pgt. CS) : Kendriya Vidyalaya UttarkashiAjay Chauhan100% (4)
- School Fee ManagementDocument27 pagesSchool Fee ManagementJatin SinghNo ratings yet
- CSI 4107 - Winter 2016 - MidtermDocument10 pagesCSI 4107 - Winter 2016 - MidtermAmin Dhouib0% (1)
- Wa0003.Document15 pagesWa0003.Divyanshu YadavNo ratings yet
- Parallelization of Dijkstra's AlgorithmDocument14 pagesParallelization of Dijkstra's AlgorithmDionysios Zelios100% (2)
- MH3400 Algorithms for Real World ApplicationsDocument40 pagesMH3400 Algorithms for Real World ApplicationsSon NguyenNo ratings yet
- 005-001-000-019 Give Binary A Try!Document12 pages005-001-000-019 Give Binary A Try!Balian1908No ratings yet
- Department of Computer Science and EngineeringDocument45 pagesDepartment of Computer Science and EngineeringSharonNo ratings yet
- Delivery Management Algorithms and Their ApplicationsDocument6 pagesDelivery Management Algorithms and Their ApplicationsIJAR JOURNALNo ratings yet
- Generate SEO-Optimized Title for Investigatory Project Certificate DocumentDocument13 pagesGenerate SEO-Optimized Title for Investigatory Project Certificate DocumentT VpNo ratings yet
- Women'S University in Africa: Addressing Gender Disparity and Fostering Equity in University EducationDocument4 pagesWomen'S University in Africa: Addressing Gender Disparity and Fostering Equity in University EducationlloydmuyaNo ratings yet
- Web Data AnalysisDocument93 pagesWeb Data AnalysisCheng-Jun WangNo ratings yet
- 1 TensorFlowDocument66 pages1 TensorFlowSWAMYA RANJAN DASNo ratings yet
- and Edit (Report)Document22 pagesand Edit (Report)5cxd7r9nmdNo ratings yet
- Visualise ECLiPSe Constraint ProgramsDocument28 pagesVisualise ECLiPSe Constraint ProgramsyassinezbakheNo ratings yet
- Fundamental Act. 1.3Document7 pagesFundamental Act. 1.3Alfredo de Alba AlvaradoNo ratings yet
- Quiz MasterDocument15 pagesQuiz MasterÂñúräg Sîñgh100% (1)
- Practical Journal Sna With WriteupsDocument37 pagesPractical Journal Sna With Writeupssakshi mishraNo ratings yet
- Quiz Master Certificate Earns Top Student RecognitionDocument17 pagesQuiz Master Certificate Earns Top Student RecognitionMukesh JangraNo ratings yet
- 137 DSDocument14 pages137 DSPatel VivekNo ratings yet
- 6081.hostel Management (1) OrgDocument13 pages6081.hostel Management (1) Orgkarthi keyanNo ratings yet
- New TextMaker DocumentDocument32 pagesNew TextMaker Documentvineet sharmaNo ratings yet
- EE-BMS Micro ProjectDocument12 pagesEE-BMS Micro ProjectPrashant KuwarNo ratings yet
- CS FinalDocument26 pagesCS FinalBhavya SoniNo ratings yet
- Improve Text Classification Accuracy Based On Classifier Fusion MethodsDocument6 pagesImprove Text Classification Accuracy Based On Classifier Fusion Methodsdanesh110No ratings yet
- ilovepdf_merged (3) (1)Document25 pagesilovepdf_merged (3) (1)ayushkale231105No ratings yet
- Discrete Mathamethics: Algorithm Makes Google Map PossibleDocument16 pagesDiscrete Mathamethics: Algorithm Makes Google Map Possiblechetan jangirNo ratings yet
- Sample 1Document21 pagesSample 1zakariyaramees260No ratings yet
- AI MidsDocument22 pagesAI MidsTalha MansoorNo ratings yet
- Master Thesis Uni BonnDocument6 pagesMaster Thesis Uni Bonnaflodtsecumyed100% (2)
- Week 10-11 ModuleDocument52 pagesWeek 10-11 ModuleYuri MahilumNo ratings yet
- Safal's ProjectDocument15 pagesSafal's ProjectSafal PoudelNo ratings yet
- Assignment XML Doc CodeDocument2 pagesAssignment XML Doc CodeNadia ButtNo ratings yet
- NPV 1Document8 pagesNPV 1Nadia ButtNo ratings yet
- INFO5992 2013S1 Wk1 AboutThisUnitDocument34 pagesINFO5992 2013S1 Wk1 AboutThisUnitNadia ButtNo ratings yet
- Creating Interactive Dashboards and Using Oracle Business Intelligence AnswersDocument65 pagesCreating Interactive Dashboards and Using Oracle Business Intelligence AnswersRazzak RamzanNo ratings yet
- RemedyDocument1 pageRemedyNadia ButtNo ratings yet
- Sama AjaxDocument17 pagesSama Ajaxernestohp7No ratings yet
- HackingDocument14 pagesHackinghacking hNo ratings yet
- MMA307 Lecture 2: Introduction To (Matlab) ProgrammingDocument32 pagesMMA307 Lecture 2: Introduction To (Matlab) ProgrammingDenis Martins DantasNo ratings yet
- Examples Distributed Systems PDFDocument2 pagesExamples Distributed Systems PDFMichaelNo ratings yet
- SQA Plan TemplateDocument106 pagesSQA Plan TemplatedtsharpieNo ratings yet
- DSSDocument13 pagesDSSKeerthi PalariNo ratings yet
- Biometrics PresentationDocument35 pagesBiometrics PresentationberengerroshenNo ratings yet
- Veritas Backup Exec 16 DsDocument5 pagesVeritas Backup Exec 16 Dsjuan.pasion3696No ratings yet
- Learn C and C++ Programming in 6 WeeksDocument3 pagesLearn C and C++ Programming in 6 WeeksKruthik KruthiNo ratings yet
- Sheet8 SolutionDocument4 pagesSheet8 SolutionSyed Furqan AlamNo ratings yet
- The Beauty of Bresenham's AlgorithmDocument3 pagesThe Beauty of Bresenham's AlgorithmAnh Truong MinhNo ratings yet
- GENEXUS X EPISODIO 1 2da EDICION EN PDFDocument136 pagesGENEXUS X EPISODIO 1 2da EDICION EN PDFTinel Paulo RobertoNo ratings yet
- VB Script Coding ConventionsDocument11 pagesVB Script Coding ConventionsvinylscribdNo ratings yet
- Fast Track Orientation: Building a Basic Application in PRPCDocument4 pagesFast Track Orientation: Building a Basic Application in PRPCSudheer ChowdaryNo ratings yet
- Report Anomalies and Normalization SummaryDocument5 pagesReport Anomalies and Normalization SummaryThomas_GodricNo ratings yet
- 1333228531.0442unit 4Document19 pages1333228531.0442unit 4RolandDanangWijaya0% (1)
- DotNet SQL Interview QuestionsDocument167 pagesDotNet SQL Interview QuestionsDuccati ZiNo ratings yet
- Intro Basic Network ConceptsDocument48 pagesIntro Basic Network ConceptsJay Carlo SalcedoNo ratings yet
- CC RecordDocument83 pagesCC RecordDumbNo ratings yet
- Conditional Constructs: Shivani Varshney/RCET/Programming With CDocument86 pagesConditional Constructs: Shivani Varshney/RCET/Programming With Csonu1070No ratings yet
- OSDocument4 pagesOSChai Jin YingNo ratings yet
- PBO - Inheritance & Abstract Method and ClassDocument10 pagesPBO - Inheritance & Abstract Method and ClassDani RamadaniNo ratings yet
- Specification, Design and Implementation of A Reuse RepositoryDocument4 pagesSpecification, Design and Implementation of A Reuse RepositoryAfonso Flash HenriqueNo ratings yet
- Dept. CS (SF) BHC Question Bank (UG) Web App. DevDocument25 pagesDept. CS (SF) BHC Question Bank (UG) Web App. DevhairboiNo ratings yet
- Virtual Classroom Java Project ReportDocument42 pagesVirtual Classroom Java Project ReportShekhar Imvu100% (1)
- VM OvsDocument9 pagesVM OvsdesertcoderNo ratings yet
- BMC PATROL Getting Started Guide - 4.3Document308 pagesBMC PATROL Getting Started Guide - 4.3btolawoyinNo ratings yet
- MiContactCenter InstallationandAdministrationGuideDocument527 pagesMiContactCenter InstallationandAdministrationGuideGuillaume HochainNo ratings yet
- Briscoe G., Caelli T. A Compendium of Machine Learning. Symbolic Machine LearningDocument9 pagesBriscoe G., Caelli T. A Compendium of Machine Learning. Symbolic Machine LearningVíctor Iván González GuevaraNo ratings yet
- Sense of Security Whitepaper Skype For Business SecurityDocument18 pagesSense of Security Whitepaper Skype For Business SecuritySeetha LakshmiNo ratings yet