You might also like
- Arithmetic Mean, Median and Mode ExplainedDocument13 pagesArithmetic Mean, Median and Mode ExplainedNawazish KhanNo ratings yet
- Hypothesis Testing ExplainedDocument16 pagesHypothesis Testing Explainedtemedebere100% (1)
- Linear Regression and Correlation Analysis Presentation1Document71 pagesLinear Regression and Correlation Analysis Presentation1elioNo ratings yet
- Chapter Two: Statistical Estimation: Definition of Terms: Interval EstimateDocument15 pagesChapter Two: Statistical Estimation: Definition of Terms: Interval EstimatetemedebereNo ratings yet
- Graphical Representation of DataDocument36 pagesGraphical Representation of DataNihal AhmadNo ratings yet
- Simple Linear Regression Analysis PDFDocument16 pagesSimple Linear Regression Analysis PDFMeliodas DonoNo ratings yet
- Chapter 3Document12 pagesChapter 3Abdii Dhufeera100% (2)
- Z-Test Formulas: 6 Steps for Hypothesis TestingDocument24 pagesZ-Test Formulas: 6 Steps for Hypothesis TestingSalem Quiachon III100% (1)
- CH 3 and 4Document44 pagesCH 3 and 4zeyin mohammed aumer100% (4)
- wHAT IS STADocument10 pageswHAT IS STAcutee0953No ratings yet
- STA301 - Midterm MCQS 1 PDFDocument28 pagesSTA301 - Midterm MCQS 1 PDFShakir SiddiquiNo ratings yet
- Ang STA230Document62 pagesAng STA230Ibnu Noval100% (1)
- Laerd Statistics 2013Document3 pagesLaerd Statistics 2013Rene John Bulalaque EscalNo ratings yet
- Lecture - 8 - Statistics - Standard Deviation - Dr. (MRS) - Neelam YadavDocument31 pagesLecture - 8 - Statistics - Standard Deviation - Dr. (MRS) - Neelam YadavayushiNo ratings yet
- Business Statistics Module - 1 Introduction-Meaning, Definition, Functions, Objectives and Importance of StatisticsDocument5 pagesBusiness Statistics Module - 1 Introduction-Meaning, Definition, Functions, Objectives and Importance of StatisticsPnx RageNo ratings yet
- Sampling Distribution Revised For IBS 2020 BatchDocument48 pagesSampling Distribution Revised For IBS 2020 Batchnandini swamiNo ratings yet
- Chapter FourDocument44 pagesChapter FourKaleab Tessema100% (1)
- Descriptive Statistics MeasuresDocument10 pagesDescriptive Statistics MeasuresABAGAEL CACHONo ratings yet
- Presentation 3Document37 pagesPresentation 3Swaroop Ranjan Baghar100% (1)
- Phase 1 & 2: 50% OFF On NABARD Courses Code: NABARD50Document23 pagesPhase 1 & 2: 50% OFF On NABARD Courses Code: NABARD50SaumyaNo ratings yet
- Module - 4 PDFDocument15 pagesModule - 4 PDFKeyur PopatNo ratings yet
- Managerial Statistics UuDocument138 pagesManagerial Statistics UuSolomonNo ratings yet
- Set 1Document7 pagesSet 1Teoh Siang YewNo ratings yet
- Uses of Index NumbersDocument7 pagesUses of Index NumbersAjay KarthikNo ratings yet
- Central TendencyDocument26 pagesCentral Tendencyবিজয় সিকদারNo ratings yet
- Linear Regression and CorrelationDocument1 pageLinear Regression and CorrelationAtaleeqNo ratings yet
- Sampling Distribution EstimationDocument21 pagesSampling Distribution Estimationsoumya dasNo ratings yet
- Maximizing Utility with the Law of Diminishing ReturnsDocument15 pagesMaximizing Utility with the Law of Diminishing ReturnsUmesh PrajapatiNo ratings yet
- 4 Measures of Central Tendency, Position, Variability PDFDocument24 pages4 Measures of Central Tendency, Position, Variability PDFJenny Estoconing Sardañas Jr.100% (1)
- Chapter 3Document28 pagesChapter 3Hope Knock100% (1)
- 3.data Summarizing and Presentation PDFDocument34 pages3.data Summarizing and Presentation PDFIoana CroitoriuNo ratings yet
- Sample Mid-Term Exam (The Sample Contains Only 20 Questions)Document5 pagesSample Mid-Term Exam (The Sample Contains Only 20 Questions)Phan Huỳnh Châu TrânNo ratings yet
- QUAMETDocument5 pagesQUAMETedniel maratas100% (2)
- TESTING HYPOTHESESDocument16 pagesTESTING HYPOTHESESDilip YadavNo ratings yet
- Week 8:: Hypothesis Testing With One-Sample T-TestDocument18 pagesWeek 8:: Hypothesis Testing With One-Sample T-TestWillie WeiNo ratings yet
- Accounting 1Document16 pagesAccounting 1Tesfamlak MulatuNo ratings yet
- 11 BS201 Prob and Stat - Ch4Document30 pages11 BS201 Prob and Stat - Ch4knmounika2395100% (1)
- Final Examination 2: Name: - Joven Jaravata (Abpsych1)Document4 pagesFinal Examination 2: Name: - Joven Jaravata (Abpsych1)Joven JaravataNo ratings yet
- Lesson 4-Individual BehaviourDocument42 pagesLesson 4-Individual BehaviourSayed MazakatNo ratings yet
- Sampling Theory And: Its Various TypesDocument46 pagesSampling Theory And: Its Various TypesAashish KumarNo ratings yet
- PLT 6133 Quantitative Correlation and RegressionDocument50 pagesPLT 6133 Quantitative Correlation and RegressionZeinab Goda100% (1)
- Econometrics AssignmentDocument40 pagesEconometrics AssignmentMANAV ASHRAFNo ratings yet
- LECTURED Statistics RefresherDocument123 pagesLECTURED Statistics RefreshertemedebereNo ratings yet
- Module 2 - Research MethodologyDocument18 pagesModule 2 - Research MethodologyPRATHAM MOTWANI100% (1)
- Claasification of CostsDocument21 pagesClaasification of CostsSaima Nazir KhanNo ratings yet
- 4 Circuit TheoremsDocument40 pages4 Circuit TheoremsTanmoy PandeyNo ratings yet
- Render 10Document28 pagesRender 10eliane вelénNo ratings yet
- 7 Chi-Square Test For IndependenceDocument3 pages7 Chi-Square Test For IndependenceMarven LaudeNo ratings yet
- Chapter 3Document19 pagesChapter 3Shimelis TesemaNo ratings yet
- What Are The Components of A Compensation SystemDocument5 pagesWhat Are The Components of A Compensation SystemLing Ching YapNo ratings yet
- Z & T Tests, ANOVA, Correlation: Hypothesis Testing ExamplesDocument33 pagesZ & T Tests, ANOVA, Correlation: Hypothesis Testing ExamplesJovenil BacatanNo ratings yet
- Sampling Distributions, Estimation and Hypothesis Testing - Multiple Choice QuestionsDocument6 pagesSampling Distributions, Estimation and Hypothesis Testing - Multiple Choice Questionsfafa salah100% (1)
- ECONOassessment of Budget Preparation and Performance EvaluationDocument50 pagesECONOassessment of Budget Preparation and Performance EvaluationMubarak100% (1)
- 4T + 3C 240 (Hours of Carpentry Time)Document5 pages4T + 3C 240 (Hours of Carpentry Time)artNo ratings yet
- Final Exam 1 - Part A: Confidence Intervals, Hypothesis Tests & ProbabilityDocument13 pagesFinal Exam 1 - Part A: Confidence Intervals, Hypothesis Tests & Probabilityupload55No ratings yet
- Measure of Central TendencyDocument113 pagesMeasure of Central TendencyRajdeep DasNo ratings yet
- At The End of The Lesson The Students Should Be Able ToDocument19 pagesAt The End of The Lesson The Students Should Be Able ToAlyanna R. JuanNo ratings yet
- Problem Set (Statistics) - AssignmentDocument1 pageProblem Set (Statistics) - Assignmentchelsea kayle licomes fuentes100% (1)
- Statistics - Chi Square: Test of Homogeneity (Reporting)Document21 pagesStatistics - Chi Square: Test of Homogeneity (Reporting)Ionacer Viper0% (1)
- ACCT3563 Issues in Financial Reporting Analysis Part A S12013 1Document3 pagesACCT3563 Issues in Financial Reporting Analysis Part A S12013 1Yousuf khanNo ratings yet
- Pie Charts: December 3, 2015 Typesofgraphs01Document5 pagesPie Charts: December 3, 2015 Typesofgraphs01Leonora Erika RiveraNo ratings yet
- Student Teaching Experiences IN Bicol University College of Education Integrated Laboratory School Daraga, AlbayDocument2 pagesStudent Teaching Experiences IN Bicol University College of Education Integrated Laboratory School Daraga, AlbayLeonora Erika RiveraNo ratings yet
- Survey-Questionnaire (Household Head)Document3 pagesSurvey-Questionnaire (Household Head)Leonora Erika RiveraNo ratings yet
- Calculus Written ReportDocument4 pagesCalculus Written ReportLeonora Erika RiveraNo ratings yet
- ChartDocument4 pagesChartLeonora Erika RiveraNo ratings yet
- JoblessDocument9 pagesJoblessLeonora Erika RiveraNo ratings yet
- Hyperbola With Center at (H, K)Document3 pagesHyperbola With Center at (H, K)Leonora Erika RiveraNo ratings yet
- Family PlanningDocument5 pagesFamily PlanningLeonora Erika RiveraNo ratings yet
- Economic ProblemsDocument12 pagesEconomic ProblemsLeonora Erika RiveraNo ratings yet
- SpeechDocument15 pagesSpeechLeonora Erika RiveraNo ratings yet
- Dr. Helen M. Llenaresas Vice President Academic AffairsDocument1 pageDr. Helen M. Llenaresas Vice President Academic AffairsLeonora Erika RiveraNo ratings yet
- Activity SheetDocument1 pageActivity SheetLeonora Erika RiveraNo ratings yet
- SaleDocument1 pageSaleLeonora Erika RiveraNo ratings yet
- Early ChildhoodDocument8 pagesEarly ChildhoodLeonora Erika Rivera0% (1)
- Lease AgreementDocument2 pagesLease AgreementLeonora Erika RiveraNo ratings yet
- Transcript of Copy of Yearbook Proposal Middle School 2013Document3 pagesTranscript of Copy of Yearbook Proposal Middle School 2013Leonora Erika RiveraNo ratings yet
- Leonora Erika O. Rivera: Career ObjectiveDocument1 pageLeonora Erika O. Rivera: Career ObjectiveLeonora Erika RiveraNo ratings yet
- Cherry Ann Amante Acojedo Resume Objective Skills ExperienceDocument2 pagesCherry Ann Amante Acojedo Resume Objective Skills ExperienceLeonora Erika RiveraNo ratings yet
- Progress ChartDocument2 pagesProgress ChartLeonora Erika RiveraNo ratings yet
- Chapter III (Thesis)Document7 pagesChapter III (Thesis)Leonora Erika RiveraNo ratings yet
- 0000000011Document2 pages0000000011Leonora Erika RiveraNo ratings yet
- Prof - Ed14 Chapter One (Thesis)Document11 pagesProf - Ed14 Chapter One (Thesis)Leonora Erika RiveraNo ratings yet
- SurveyDocument3 pagesSurveyLeonora Erika RiveraNo ratings yet
- Lesson Plan in English ViDocument3 pagesLesson Plan in English ViLeonora Erika RiveraNo ratings yet
- SurveyDocument3 pagesSurveyLeonora Erika RiveraNo ratings yet
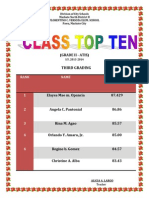
- (Grade Ii - Atis) : Third GradingDocument1 page(Grade Ii - Atis) : Third GradingLeonora Erika RiveraNo ratings yet
- Statistic: Price IndexDocument3 pagesStatistic: Price IndexLeonora Erika RiveraNo ratings yet
- Lesson Plan Math (Repaired)Document4 pagesLesson Plan Math (Repaired)Leonora Erika RiveraNo ratings yet
- Masbate College English Lesson Synonyms AntonymsDocument9 pagesMasbate College English Lesson Synonyms AntonymsLeonora Erika RiveraNo ratings yet
- Liquid Chlorine Shelf Life IncreasedDocument5 pagesLiquid Chlorine Shelf Life IncreasedSyifa FauziyahNo ratings yet
- 3 IS Module 5Document11 pages3 IS Module 5Hiezeyl Ymana GuntangNo ratings yet
- Hinay, Joel A.: Group Count Sum Mean Variance SS STD Err Lower UpperDocument3 pagesHinay, Joel A.: Group Count Sum Mean Variance SS STD Err Lower UpperJoel HinayNo ratings yet
- Statistics For Management Model Paper AnalysisDocument18 pagesStatistics For Management Model Paper AnalysisRahul CharanNo ratings yet
- Cyber Crime Project For MCOMDocument31 pagesCyber Crime Project For MCOMsachinNo ratings yet
- Section 6 Data - Statistics For Quantitative StudyDocument142 pagesSection 6 Data - Statistics For Quantitative StudyTưởng NguyễnNo ratings yet
- Excercise-A Independent Sample Case - Parametric Approach Q-1A)Document11 pagesExcercise-A Independent Sample Case - Parametric Approach Q-1A)Mohammad Talha QureshiNo ratings yet
- Kuiper Ch03 PDFDocument35 pagesKuiper Ch03 PDFjmurcia78No ratings yet
- Analysis of Variance AnovaDocument14 pagesAnalysis of Variance AnovaRichard James MalicdemNo ratings yet
- Effectiveness TBI CBI in Teaching VocabDocument19 pagesEffectiveness TBI CBI in Teaching VocabSu HandokoNo ratings yet
- Management Accounting Change & RolesDocument19 pagesManagement Accounting Change & RolesAmauri OliveiraNo ratings yet
- RobiSetiawan - Tugas 4 .IpynbDocument13 pagesRobiSetiawan - Tugas 4 .IpynbROBI SETIAWANNo ratings yet
- Data ManagementDocument8 pagesData Managementflo sisonNo ratings yet
- Assessment Test in PR 2Document15 pagesAssessment Test in PR 2Den Gesiefer LazaroNo ratings yet
- Government Spending and Income in NigeriaDocument11 pagesGovernment Spending and Income in Nigeriaakita_1610No ratings yet
- Job Satisfaction Study at Rane Engine Valve LtdDocument62 pagesJob Satisfaction Study at Rane Engine Valve Ltdganesh1433100% (1)
- Introduction To Sampling and Sampling Designs: University of BaguioDocument41 pagesIntroduction To Sampling and Sampling Designs: University of BaguioJason Vi LucasNo ratings yet
- G Power ManualDocument78 pagesG Power ManualLavinia Stupariu100% (1)
- A Review of DIMPACK Version 1.0Document11 pagesA Review of DIMPACK Version 1.0Anusorn Koedsri100% (1)
- How ads influence menswear purchasesDocument46 pagesHow ads influence menswear purchasesNaghmanNo ratings yet
- MATLAB Econometric Model ForecastingDocument10 pagesMATLAB Econometric Model ForecastingOmiNo ratings yet
- Statistics and Prob 11 Summative Test 1,2 and 3 Q4Document3 pagesStatistics and Prob 11 Summative Test 1,2 and 3 Q4Celine Mary DamianNo ratings yet
- Major Incident Manager ITIL in San Antonio TX Resume Randall NepsundDocument3 pagesMajor Incident Manager ITIL in San Antonio TX Resume Randall NepsundRandallNepsundNo ratings yet
- Unit 3 Experimental Designs: ObjectivesDocument14 pagesUnit 3 Experimental Designs: ObjectivesDep EnNo ratings yet
- Hypothesis testing two populations quiz answersDocument29 pagesHypothesis testing two populations quiz answersvuduyduc100% (1)
- MBA Syllabus KTU PDFDocument227 pagesMBA Syllabus KTU PDFAnanthan JayapalNo ratings yet
- SPSS 03 Hypothesis and TestsDocument13 pagesSPSS 03 Hypothesis and TestsMathew KanichayNo ratings yet
- Ch3 SlidesDocument37 pagesCh3 SlidesRossy Dinda PratiwiNo ratings yet
- Nonparametric Tests for Medians and DistributionsDocument56 pagesNonparametric Tests for Medians and DistributionsPavithraNo ratings yet
- 365 Data Science - Statistics: Glossary Section Lesson WordDocument5 pages365 Data Science - Statistics: Glossary Section Lesson WordAnuj KaushikNo ratings yet