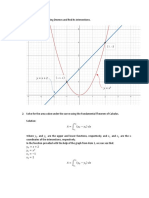
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Power Semiconductor Controlled Drives - Gopal K Dubey PDFDocument514 pagesPower Semiconductor Controlled Drives - Gopal K Dubey PDFLevingstan Yesudhas84% (103)
- Manual LDM5 U enDocument3 pagesManual LDM5 U enLuizAugustoMedeirosNo ratings yet
- EMTP Ref Model-FinalDocument61 pagesEMTP Ref Model-FinalRadhika PriyadarshiniNo ratings yet
- Eee SyllabusDocument111 pagesEee SyllabusDhana SelvamNo ratings yet
- Insulation - InsulationDocument9 pagesInsulation - InsulationPaneendra KumarNo ratings yet
- Sample New Age Dem PDFDocument6 pagesSample New Age Dem PDFSubanth WiiliamsNo ratings yet
- UG - Except 8th Sem and UG PG 2 Sem PDFDocument1 pageUG - Except 8th Sem and UG PG 2 Sem PDFSam Devid Jero DuraisamyNo ratings yet
- Ee2355 Dem Nol 2013Document24 pagesEe2355 Dem Nol 2013Anurag AryaNo ratings yet
- Unit 1Document65 pagesUnit 1Kabi RockNo ratings yet
- EE2355 DEM Unit-I Solved ProblemsDocument3 pagesEE2355 DEM Unit-I Solved ProblemsSubanth WiiliamsNo ratings yet
- Thyristor DC Drives. P.c.senDocument307 pagesThyristor DC Drives. P.c.senpalu259478% (9)
- EE2355 Design of Electrical Machines NotesDocument24 pagesEE2355 Design of Electrical Machines Notesmadhes14No ratings yet
- Paper 4Document6 pagesPaper 4Subanth WiiliamsNo ratings yet
- EE2355 DEM 2marks 2013Document19 pagesEE2355 DEM 2marks 2013baks007No ratings yet
- Dem May June 2013 QPDocument3 pagesDem May June 2013 QPSubanth WiiliamsNo ratings yet
- Anna University Report FormatDocument7 pagesAnna University Report Formatdilip_66690% (10)
- Guidelines for M.E./M.Tech Phase I Report & Phase II ThesisDocument13 pagesGuidelines for M.E./M.Tech Phase I Report & Phase II Thesisபுருஷோத்தமன் சரவணன்No ratings yet
- Pipelining (DSP Implementation) - Wikipedia, The Free EncyclopediaDocument5 pagesPipelining (DSP Implementation) - Wikipedia, The Free EncyclopediaSubanth WiiliamsNo ratings yet
- DSP ArchitectureDocument63 pagesDSP Architecturekrrakesh5No ratings yet
- Unit 3Document15 pagesUnit 3Subanth WiiliamsNo ratings yet
- ParallelismDocument4 pagesParallelismSubanth WiiliamsNo ratings yet
- Coe1.annauniv - Edu Aucoe PDF 2015 Apr May UG PG Second Sem Am15 PDFDocument1 pageCoe1.annauniv - Edu Aucoe PDF 2015 Apr May UG PG Second Sem Am15 PDFSubanth WiiliamsNo ratings yet
- WWW - Eit.lth - Se Fileadmin Eit Courses Eti180 Slides2011 Lec-PipeParDocument23 pagesWWW - Eit.lth - Se Fileadmin Eit Courses Eti180 Slides2011 Lec-PipeParSubanth WiiliamsNo ratings yet
- Parallel Processing (DSP Implementation) - Wikipedia, The Free EncyclopediaDocument5 pagesParallel Processing (DSP Implementation) - Wikipedia, The Free EncyclopediaSubanth WiiliamsNo ratings yet
- Part-A Answer All (5x2 10)Document1 pagePart-A Answer All (5x2 10)Subanth WiiliamsNo ratings yet
- Evs Quest 1asecDocument1 pageEvs Quest 1asecSubanth WiiliamsNo ratings yet
- Ec 1362-Microprocessors AndicrocontrollerDocument7 pagesEc 1362-Microprocessors Andicrocontrollerpurushoth@aeroNo ratings yet
- Lab5 AssignmentDocument3 pagesLab5 AssignmentSelva KumarNo ratings yet
- Introduction To Real-Time ProgrammingDocument15 pagesIntroduction To Real-Time ProgrammingSubanth WiiliamsNo ratings yet
- Syllabus MII LabDocument1 pageSyllabus MII LabSubanth WiiliamsNo ratings yet
- Metodo Fotometrico para La Determinación de La Concentración de Ozono AtmosféricoDocument8 pagesMetodo Fotometrico para La Determinación de La Concentración de Ozono AtmosféricoVarinia ZubiletaNo ratings yet
- Model For Calculating The Refractive Index of DiffDocument5 pagesModel For Calculating The Refractive Index of DiffNANNo ratings yet
- Microsoft Office Tips and TricksDocument12 pagesMicrosoft Office Tips and TricksJayr BVNo ratings yet
- Area Under The CurveDocument3 pagesArea Under The CurveReyland DumlaoNo ratings yet
- Mid Drive Vs HubDocument15 pagesMid Drive Vs HubRivan PamungkasNo ratings yet
- NCERT Solutions For Class 8 Maths Chapter 14 - FactorizationDocument25 pagesNCERT Solutions For Class 8 Maths Chapter 14 - FactorizationSATAMANYU BHOLNo ratings yet
- Uniform ForceDocument11 pagesUniform ForcearnoldistunoNo ratings yet
- Ray OpticsDocument41 pagesRay OpticsHannah VsNo ratings yet
- 24Document3 pages24sdssdNo ratings yet
- WPMD 3002Document6 pagesWPMD 3002Adilson LucaNo ratings yet
- Doubble EncriptionDocument60 pagesDoubble Encriptiondeepak kumarNo ratings yet
- BA (Hons) Philosophy CurriculumDocument123 pagesBA (Hons) Philosophy CurriculumDARSHAN RAAJANNo ratings yet
- Raman BandsDocument2 pagesRaman Bandspreyas1No ratings yet
- Chieftain 2100X (2-Deck) Data SheetDocument1 pageChieftain 2100X (2-Deck) Data SheetbrianNo ratings yet
- Introduction to Nautilus 8 Mold Qualification and Design of Experiments SoftwareDocument66 pagesIntroduction to Nautilus 8 Mold Qualification and Design of Experiments SoftwareJohn SuperdetalleNo ratings yet
- GR/KWH, KG/HR or Tons/Month.: ScopeDocument5 pagesGR/KWH, KG/HR or Tons/Month.: ScopeThaigroup CementNo ratings yet
- CS5371 Theory of Computation: Lecture 1: Mathematics Review I (Basic Terminology)Document23 pagesCS5371 Theory of Computation: Lecture 1: Mathematics Review I (Basic Terminology)Kamal WaliaNo ratings yet
- Effort Distribution On Waterfall and AgileDocument12 pagesEffort Distribution On Waterfall and Agileanandapramanik100% (2)
- PAPER I MATHEMATICS PRACTICE SETDocument6 pagesPAPER I MATHEMATICS PRACTICE SETRitesh Raj PandeyNo ratings yet
- TIMO Mock 2019 卷P3fDocument9 pagesTIMO Mock 2019 卷P3fDo Yun100% (1)
- UCE802 Earthquake SyllabusDocument2 pagesUCE802 Earthquake Syllabuskullu88No ratings yet
- Assignment2AI - 2023 Moderated2Document11 pagesAssignment2AI - 2023 Moderated2minajadritNo ratings yet
- Notes 3 - Consistent Deformation DerivationDocument3 pagesNotes 3 - Consistent Deformation DerivationAdi DeckNo ratings yet
- Manual Handbook Ripping Cat Selection Techniques Applications Production CompatibilityDocument32 pagesManual Handbook Ripping Cat Selection Techniques Applications Production CompatibilityPoPandaNo ratings yet
- Modern Scoring BRASS Manual1Document25 pagesModern Scoring BRASS Manual1Pepe ChorrasNo ratings yet
- Brushless DC Motor Control Using PLCDocument6 pagesBrushless DC Motor Control Using PLCvuluyen6688No ratings yet
- Akvola Technologies MicroGas S Technical Specifications - Web PDFDocument2 pagesAkvola Technologies MicroGas S Technical Specifications - Web PDFHardik VavdiyaNo ratings yet
- Simulation and Implementation of Servo Motor Control With Sliding Mode Control (SMC) Using Matlab and LabviewDocument30 pagesSimulation and Implementation of Servo Motor Control With Sliding Mode Control (SMC) Using Matlab and Labviewmjohn87No ratings yet
- 1956 - Colinese - Boiler Efficiencies in SugarDocument7 pages1956 - Colinese - Boiler Efficiencies in SugarPaul DurkinNo ratings yet