You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hata and Hata SRD Implementation v3Document5 pagesHata and Hata SRD Implementation v3hckhoa1238No ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Secon12 CRNDocument9 pagesSecon12 CRNhckhoa1238No ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- An Efficient Power-Loading Scheme For OFDM-Based Cognitive Radio SystemsDocument7 pagesAn Efficient Power-Loading Scheme For OFDM-Based Cognitive Radio Systemshckhoa1238No ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Itu-R P.1546-4-200910Document57 pagesItu-R P.1546-4-200910Zika ZivkovicNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Derivation of A Block Edge MaskDocument66 pagesDerivation of A Block Edge MaskVadim GoncharovNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Cognitive Radio NetworksDocument5 pagesCognitive Radio Networkshckhoa1238No ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Throughput Study For Dynamic OFDM-FDMADocument5 pagesThroughput Study For Dynamic OFDM-FDMAhckhoa1238No ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Randezvous SolverDocument15 pagesRandezvous Solverhckhoa1238No ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Channel Selection Under Interference Temperature Model in Multi-Hop Cognitive Mesh NetworksDocument12 pagesChannel Selection Under Interference Temperature Model in Multi-Hop Cognitive Mesh Networkshckhoa1238No ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Dynamic Channel AsignmentDocument5 pagesDynamic Channel Asignmenthckhoa1238No ratings yet
- Estimate Interference Power and NoiseDocument9 pagesEstimate Interference Power and Noisehckhoa1238No ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Near Vs Far Field - Interference Aggregation in TV - ExtendedDocument7 pagesNear Vs Far Field - Interference Aggregation in TV - Extendedhckhoa1238No ratings yet
- Allocation For OFDM - Throughput CalDocument5 pagesAllocation For OFDM - Throughput Calhckhoa1238No ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Survey On Multiobject Evolutionary and Real Coded Genetic AlgorithmsDocument12 pagesSurvey On Multiobject Evolutionary and Real Coded Genetic Algorithmshckhoa1238No ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- To Tu Thuong DungDocument64 pagesTo Tu Thuong DungDo Nguyen van VuongNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Chapter 7 Adaptive OFDMDocument50 pagesChapter 7 Adaptive OFDMHc KhoaNo ratings yet
- Interference Analysis of Cognitive Radio Networks inDocument5 pagesInterference Analysis of Cognitive Radio Networks inhckhoa1238No ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Cognet Interf Beacon WCNCDocument6 pagesCognet Interf Beacon WCNCTôm SúNo ratings yet
- Segmentation 268Document12 pagesSegmentation 268hckhoa1238No ratings yet
- Tuglab: A Cooperative Game Theory Toolbox: Mir As Calvo, Miguel Angel and S Anchez Rodr Iguez, EstelaDocument3 pagesTuglab: A Cooperative Game Theory Toolbox: Mir As Calvo, Miguel Angel and S Anchez Rodr Iguez, Estelahckhoa1238100% (1)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Smart Mathematicians Lower Pri SampleDocument10 pagesSmart Mathematicians Lower Pri SamplesvsvidyasagarNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- 16B-5.7 SolidsRevolution PDFDocument7 pages16B-5.7 SolidsRevolution PDFEddyNo ratings yet
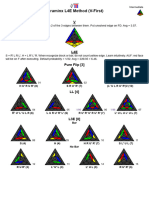
- Pyraminx L4E (V-First)Document2 pagesPyraminx L4E (V-First)tudorsebastian299No ratings yet
- Math Practise Paper X For XBDocument7 pagesMath Practise Paper X For XBRAJ SHEKHARNo ratings yet
- GCSE 1-3 Prime Factors and Trees Week 23Document20 pagesGCSE 1-3 Prime Factors and Trees Week 23MIhaela CorcheNo ratings yet
- Fomcon ExtDocument13 pagesFomcon ExtjesvinNo ratings yet
- Add Maths F5-CHP 1Document13 pagesAdd Maths F5-CHP 1ISMADI SURINNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- FPE7e AppendicesDocument113 pagesFPE7e AppendicesJohnNo ratings yet
- Deathbound SubjectivityDocument109 pagesDeathbound SubjectivityAnonymous IfYLvzpmFeNo ratings yet
- Klimovsky Axiomatica Resumen PDFDocument12 pagesKlimovsky Axiomatica Resumen PDFEsteban BenetonsNo ratings yet
- Theory of Automata: Regular ExpressionsDocument43 pagesTheory of Automata: Regular ExpressionsHassan RazaNo ratings yet
- Working Hours Method WHM and UnitDocument11 pagesWorking Hours Method WHM and UnitSharryne Pador ManabatNo ratings yet
- Hyperdimensional Computing - IntroductionDocument21 pagesHyperdimensional Computing - Introduction고재형No ratings yet
- Day 3 Ratio and ProportionDocument2 pagesDay 3 Ratio and ProportionCarl Dominic LlavanNo ratings yet
- PIC, PID Control 2Document8 pagesPIC, PID Control 2Ermias NigussieNo ratings yet
- Modern Crypto 18 Homework 2 SolutionDocument5 pagesModern Crypto 18 Homework 2 Solutionعبدالله بحراويNo ratings yet
- MA244 - Analysis IIIDocument13 pagesMA244 - Analysis IIIRebecca RumseyNo ratings yet
- Tenths and Hundredths: Mathematics CurriculumDocument4 pagesTenths and Hundredths: Mathematics Curriculumnew vivyNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Physical Quantum AlgorithmsDocument7 pagesPhysical Quantum AlgorithmsSankha DeepNo ratings yet
- WEBINAR 2016 Nonlinear DiagnosticDocument24 pagesWEBINAR 2016 Nonlinear DiagnosticMukil DevNo ratings yet
- Linear and Quadratic Equations and Their Graphs (H) MSDocument2 pagesLinear and Quadratic Equations and Their Graphs (H) MSVindra Stacyann DhanrajNo ratings yet
- MIMO Pole PlacementDocument32 pagesMIMO Pole PlacementBharat MahajanNo ratings yet
- Algorithmic Specified Complexity in The Game of LifeDocument11 pagesAlgorithmic Specified Complexity in The Game of LifeLelieth Martin CastroNo ratings yet
- Maths Today 4 RedDocument258 pagesMaths Today 4 Redadmire matariranoNo ratings yet
- Math Finance Assignment Session 1718Document11 pagesMath Finance Assignment Session 1718Fani Masturina100% (1)
- Superficies RegularesDocument21 pagesSuperficies RegularesFabio ArevaloNo ratings yet
- Solucionario Advanced Engineering MathematicsDocument621 pagesSolucionario Advanced Engineering MathematicsHelena VelosaNo ratings yet
- (6.3) Solving Systems EliminationDocument29 pages(6.3) Solving Systems Eliminationgtan@icacademy.orgNo ratings yet
- Arml: 1995-2003Document422 pagesArml: 1995-2003Daniel Bao100% (1)
- Abstract Reasoning-GuideDocument6 pagesAbstract Reasoning-GuideAlberto HerreraNo ratings yet
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)