You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Reiki Level 1 Guide - Learn the Cho Ku Rei SymbolDocument1 pageReiki Level 1 Guide - Learn the Cho Ku Rei SymbolJaney24No ratings yet
- Precalculus ReviewerDocument6 pagesPrecalculus ReviewerIna Louise MagnoNo ratings yet
- What Is Time, The Daily RegimenDocument34 pagesWhat Is Time, The Daily RegimenJaney24100% (1)
- Continued Fractions ExplainedDocument8 pagesContinued Fractions ExplainedLexi RizziaNo ratings yet
- InterruptsDocument34 pagesInterruptsJaney24100% (1)
- HN Impulsive Procrastinator of The Highest OrderDocument5 pagesHN Impulsive Procrastinator of The Highest OrderJaney24No ratings yet
- Software - Engineering Overview SlidesDocument31 pagesSoftware - Engineering Overview SlideslittleboywebNo ratings yet
- How Can You Be Happy?Document3 pagesHow Can You Be Happy?Janey24No ratings yet
- Limitations of Algorithm Power: ObjectivesDocument14 pagesLimitations of Algorithm Power: ObjectivesJaney24No ratings yet
- Unit5 RMSDocument17 pagesUnit5 RMSJaney24No ratings yet
- Limitations of Algorithm Power: ObjectivesDocument14 pagesLimitations of Algorithm Power: ObjectivesJaney24No ratings yet
- Finite AutomataDocument27 pagesFinite AutomataJaney24No ratings yet
- Synchronous Counter GuideDocument50 pagesSynchronous Counter GuideJaney24No ratings yet
- Fundamentals of Analysis of Algorithms EfficiencyDocument9 pagesFundamentals of Analysis of Algorithms EfficiencyNaveen KumarNo ratings yet
- TreeDocument7 pagesTreeMohammad Gulam AhamadNo ratings yet
- Emulator CalcuDocument20 pagesEmulator CalcuFernabeth NgNo ratings yet
- Recursion: Data Structures and Algorithms in Java 1/25Document25 pagesRecursion: Data Structures and Algorithms in Java 1/25Tryer0% (1)
- Galois Theory Examples (Michaelmas 2022Document2 pagesGalois Theory Examples (Michaelmas 2022Aryan GadhaveNo ratings yet
- Real Time Heuristic SearchDocument35 pagesReal Time Heuristic SearchAditya NambiarNo ratings yet
- GROUP 2015 BASIC ADVANCE ALGEBRADocument8 pagesGROUP 2015 BASIC ADVANCE ALGEBRAMeliza AdvinculaNo ratings yet
- Numerical Analysis Question PaperDocument1 pageNumerical Analysis Question PaperAndrea DouglasNo ratings yet
- The Locating-Chromatic Number of Binary TreesDocument5 pagesThe Locating-Chromatic Number of Binary TreesVy'n Iipsychz AthrylithNo ratings yet
- 1 5 Assignment Parent Functions and TransformationsDocument10 pages1 5 Assignment Parent Functions and Transformationsreemib100No ratings yet
- Algorithm Design Paradigm-2 PDFDocument28 pagesAlgorithm Design Paradigm-2 PDFYukti SatheeshNo ratings yet
- Ojimc 2021 (Imo Mock)Document8 pagesOjimc 2021 (Imo Mock)NonuNo ratings yet
- Grade6 Full Year 6th Grade Review PDFDocument10 pagesGrade6 Full Year 6th Grade Review PDFEduGainNo ratings yet
- Revision Questions Yr7Document10 pagesRevision Questions Yr7vanithasarasu532No ratings yet
- Chapterd 5 C SolutionsDocument57 pagesChapterd 5 C SolutionsazharjavedNo ratings yet
- BTech CS Course Plans & SyllabiDocument31 pagesBTech CS Course Plans & Syllabianahh ramakNo ratings yet
- Squares and Square Roots Worksheet 1Document6 pagesSquares and Square Roots Worksheet 1Maira IsmailNo ratings yet
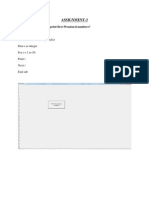
- Assignment-3: Sol Private Sub Command1 - Click Dim I As Integer For I 1 To 50 Print I Next I End SubDocument24 pagesAssignment-3: Sol Private Sub Command1 - Click Dim I As Integer For I 1 To 50 Print I Next I End SubNitin GroverNo ratings yet
- 5277681e 374Document1 page5277681e 374Alexander Segura BallesterosNo ratings yet
- Logarithm: Section-A 1Document7 pagesLogarithm: Section-A 1adityaNo ratings yet
- FibonacciDocument12 pagesFibonacciluhusapa-1No ratings yet
- Functional Equations Winter Camp 2012: Lindsey Shorser January 4, 2012Document2 pagesFunctional Equations Winter Camp 2012: Lindsey Shorser January 4, 2012viosirelNo ratings yet
- INFORMATION THEORY QuizDocument5 pagesINFORMATION THEORY Quizbabugaru12No ratings yet
- Discrete Mathematics: T.K. Maryati, A.N.M. Salman, E.T. BaskoroDocument9 pagesDiscrete Mathematics: T.K. Maryati, A.N.M. Salman, E.T. BaskoroEnzha Conrad Der'panserNo ratings yet
- Cs 6503 Toc Question BankDocument27 pagesCs 6503 Toc Question BankrishikarthickNo ratings yet
- SY Binary NumbersDocument14 pagesSY Binary NumbersNeelam KapoorNo ratings yet
- Quiz 1: Massachusetts Institute of Technology 6.042J/18.062J, Fall '05 Prof. Albert R. Meyer Prof. Ronitt RubinfeldDocument9 pagesQuiz 1: Massachusetts Institute of Technology 6.042J/18.062J, Fall '05 Prof. Albert R. Meyer Prof. Ronitt RubinfeldAlireza KafaeiNo ratings yet
- DAoA Week 11 Lecture 19 Shortest Path AlgorithmsDocument29 pagesDAoA Week 11 Lecture 19 Shortest Path AlgorithmsMuhammad AmmarNo ratings yet
- Soluciones Ejercicios 8.3 y 9.3 sobre algoritmos de grafosDocument8 pagesSoluciones Ejercicios 8.3 y 9.3 sobre algoritmos de grafosvirybattenNo ratings yet