
You might also like
- Oracle Unit-1 AssignmentDocument23 pagesOracle Unit-1 AssignmentRishi 86No ratings yet
- Starting Database Administration: Oracle DBAFrom EverandStarting Database Administration: Oracle DBARating: 3 out of 5 stars3/5 (2)
- 18c ArchitectureDocument33 pages18c ArchitectureRavindra MalwalNo ratings yet
- Oracle Database Oracle Instance + Data Files: AsktomDocument5 pagesOracle Database Oracle Instance + Data Files: Asktomvaloo_phoolNo ratings yet
- 505 - Unit 1 - RDBMSDocument13 pages505 - Unit 1 - RDBMSkrushitghevariya41No ratings yet
- Oracle Database 11g Database Architecture and ASMDocument44 pagesOracle Database 11g Database Architecture and ASMYelena BytenskayaNo ratings yet
- MMM MM M M MMMM M MMMMMMMMMMMMMMM M MM MMMMMMMMM MMMMMMMMMMMDocument10 pagesMMM MM M M MMMM M MMMMMMMMMMMMMMM M MM MMMMMMMMM MMMMMMMMMMMLokesh ChinniNo ratings yet
- In Oracle MilieuDocument6 pagesIn Oracle MilieuzahirhussianNo ratings yet
- Oracle Database Administration Hand BookDocument78 pagesOracle Database Administration Hand Bookmarioy4783% (12)
- ÷y ÷y ÷y ÷y ÷yDocument20 pages÷y ÷y ÷y ÷y ÷ydbareddyNo ratings yet
- Oracle Architecture Diagram and NotesDocument9 pagesOracle Architecture Diagram and Notesanil_shenoyNo ratings yet
- Chapter01 Oracle ArchitectureDocument42 pagesChapter01 Oracle ArchitectureOscar RiveraNo ratings yet
- Chapter01 Oracle ArchitectureDocument42 pagesChapter01 Oracle ArchitecturehenaediNo ratings yet
- Oracle ArchitectureDocument102 pagesOracle ArchitecturemanavalanmichaleNo ratings yet
- Oracle Architechture & ConceptsDocument90 pagesOracle Architechture & ConceptsElango GopalNo ratings yet
- Summary OracleDocument39 pagesSummary OracleRoel DonkerNo ratings yet
- SQL Tuning 11g CustomizedDocument873 pagesSQL Tuning 11g CustomizedMamataMaharanaNo ratings yet
- 8 Memory Architecture OverviewDocument23 pages8 Memory Architecture OverviewBishnu BhandariNo ratings yet
- 10G ConceptsDocument4 pages10G Conceptssrini6886dbaNo ratings yet
- Oracle Instance ArchitectureDocument28 pagesOracle Instance ArchitecturemonsonNo ratings yet
- SGA and PGADocument12 pagesSGA and PGAPILLINAGARAJUNo ratings yet
- Introduction To The Oracle Server: It Includes The FollowingDocument11 pagesIntroduction To The Oracle Server: It Includes The FollowingRishabh BhagatNo ratings yet
- Database Architecture Oracle DbaDocument41 pagesDatabase Architecture Oracle DbaImran ShaikhNo ratings yet
- Oracle Architecture Interview QuestionsDocument11 pagesOracle Architecture Interview QuestionsAnush Reddy100% (1)
- Tuning Day 1 Defition SDocument4 pagesTuning Day 1 Defition SIsraaNo ratings yet
- Basic OracleDocument52 pagesBasic Oraclebanala.kalyanNo ratings yet
- Module 1 - Oracle ArchitectureDocument110 pagesModule 1 - Oracle ArchitectureKranthi KumarNo ratings yet
- Oracle Database 11g: Administration IDocument7 pagesOracle Database 11g: Administration IAbhinavNo ratings yet
- Oe InterviewDocument51 pagesOe InterviewnareshNo ratings yet
- Self Tuning of Oracle Database Using SQL ScriptsDocument7 pagesSelf Tuning of Oracle Database Using SQL ScriptsRavi R SharmaNo ratings yet
- Module 1 - Oracle Architecture: ObjectivesDocument41 pagesModule 1 - Oracle Architecture: ObjectivesNavneet SainiNo ratings yet
- Oracle DBA InterviewDocument73 pagesOracle DBA InterviewjaydevdangarNo ratings yet
- Chapter 1. Oracle Database ArchitectureDocument7 pagesChapter 1. Oracle Database ArchitectureAdryan AnghelNo ratings yet
- Oracle ArchitectureDocument5 pagesOracle ArchitectureVenu BabuNo ratings yet
- Oracle Database Administration: Server Architecture and Instance OverviewDocument54 pagesOracle Database Administration: Server Architecture and Instance OverviewKanchan ChakrabortyNo ratings yet
- Database Architecture: Goutam R TDocument47 pagesDatabase Architecture: Goutam R THema SwaroopNo ratings yet
- Oracle Architecture BasicsDocument5 pagesOracle Architecture Basicschetanb39No ratings yet
- Chapter - 1: Oracle Architecture - Module 1Document39 pagesChapter - 1: Oracle Architecture - Module 1Vivek MeenaNo ratings yet
- 3 Oracle Architecture NotesDocument39 pages3 Oracle Architecture NotesPaul NikolaidisNo ratings yet
- What Is Dynamic SGADocument5 pagesWhat Is Dynamic SGANadiaNo ratings yet
- Describe Oracle Architecture in Brief.: AnswerDocument8 pagesDescribe Oracle Architecture in Brief.: AnswersonijayminNo ratings yet
- Oracle Basic ArchitectureDocument5 pagesOracle Basic ArchitecturePrapanna100% (24)
- Oracle Database Memory StructuresDocument2 pagesOracle Database Memory StructuresAzman Mamat100% (1)
- Module 1 - Oracle Architecture: ObjectivesDocument64 pagesModule 1 - Oracle Architecture: Objectivesshaikali1980No ratings yet
- Basics of The Oracle Database ArchitectureDocument56 pagesBasics of The Oracle Database Architecturevidhi hinguNo ratings yet
- Chapter6 Database ArchitectureDocument56 pagesChapter6 Database ArchitectureMohammed AlramadiNo ratings yet
- Oracle DBA 11gR2 ArchitectureDocument9 pagesOracle DBA 11gR2 ArchitectureAzmath Tech TutsNo ratings yet
- Performance TuningDocument38 pagesPerformance TuningAnweshKota100% (1)
- Object Oriented - Interview Questions: What Is OOP?Document18 pagesObject Oriented - Interview Questions: What Is OOP?Sam RogerNo ratings yet
- 2 Database ArchitectureDocument13 pages2 Database ArchitecturewaleedNo ratings yet
- QuestionaireDocument106 pagesQuestionairevenkatsainath06No ratings yet
- Oracle10g Introduction1eryk 130405011929 Phpapp02Document34 pagesOracle10g Introduction1eryk 130405011929 Phpapp02Sonali SinghNo ratings yet
- Oracle DBA ArchitectureDocument17 pagesOracle DBA ArchitectureDiwakar Reddy SNo ratings yet
- Database ArchitectureDocument6 pagesDatabase ArchitectureSrikanth GoudNo ratings yet
- Oracle Database Architecture: Product Alliance GroupDocument53 pagesOracle Database Architecture: Product Alliance GrouppranayusinNo ratings yet
- Module 1 - Oracle ArchitectureDocument34 pagesModule 1 - Oracle ArchitectureGautam TrivediNo ratings yet
- What is an Oracle Database? ComponentsDocument5 pagesWhat is an Oracle Database? ComponentsAditya JainNo ratings yet
- Oracle Shell ScriptingDocument115 pagesOracle Shell Scriptingpepe0011No ratings yet
- Collab19cannellgridapiessentails 190429020939Document88 pagesCollab19cannellgridapiessentails 190429020939Md Shadab AshrafNo ratings yet
- Lab6 Looking Into PST MetadataDocument7 pagesLab6 Looking Into PST Metadataphaniraj21128981No ratings yet
- Cannellapexgridsessentialsnov2018go 181123090433Document76 pagesCannellapexgridsessentialsnov2018go 181123090433Md Shadab AshrafNo ratings yet
- Json Developers Guide PDFDocument196 pagesJson Developers Guide PDFMd Shadab Ashraf100% (1)
- User Managed Hot BackupsDocument5 pagesUser Managed Hot BackupsMd Shadab AshrafNo ratings yet
- Oracle Shell ScriptingDocument115 pagesOracle Shell Scriptingpepe0011No ratings yet
- Oracle Shell ScriptingDocument115 pagesOracle Shell Scriptingpepe0011No ratings yet
- Ram ConfigurationDocument10 pagesRam ConfigurationMd Shadab AshrafNo ratings yet
- Cross JoinDocument9 pagesCross JoinMd Shadab AshrafNo ratings yet
- Row Chain&migration DiagDocument3 pagesRow Chain&migration DiagMd Shadab AshrafNo ratings yet
- Log MinerDocument4 pagesLog MinerMd Shadab AshrafNo ratings yet
- Hajj Mabroor Najeeb Qasmi 2011Document13 pagesHajj Mabroor Najeeb Qasmi 2011Md Shadab AshrafNo ratings yet
- SQL Test 1Document8 pagesSQL Test 1Md Shadab AshrafNo ratings yet
- SQL QueriesDocument28 pagesSQL QueriesMd Shadab Ashraf100% (1)
- How To Change IP AddressDocument3 pagesHow To Change IP AddressMd Shadab AshrafNo ratings yet
- Controfile RecoveryDocument18 pagesControfile RecoveryMd Shadab AshrafNo ratings yet
- Row ChainDocument3 pagesRow ChainMd Shadab AshrafNo ratings yet
- ORACLE APPS DBA - 11i/r12 Concepts Ad UtilitiesDocument4 pagesORACLE APPS DBA - 11i/r12 Concepts Ad UtilitiesMd Shadab AshrafNo ratings yet
- Database NormalizationDocument15 pagesDatabase NormalizationMd Shadab AshrafNo ratings yet
- Cross JoinDocument9 pagesCross JoinMd Shadab AshrafNo ratings yet
- Database CloningDocument6 pagesDatabase CloningMd Shadab AshrafNo ratings yet
- Electric and Magnetic Field Calculations With Finite Element Methods - Stanley HumphriesDocument130 pagesElectric and Magnetic Field Calculations With Finite Element Methods - Stanley HumphriesHyun Ji LeeNo ratings yet
- Delimited Report Output Using Report BuilderDocument20 pagesDelimited Report Output Using Report BuilderPritesh Mogane0% (1)
- Introduction To Computer Information SystemsDocument27 pagesIntroduction To Computer Information SystemsMr. JahirNo ratings yet
- Custom Blazor Oqtane Modules SuccinctlyDocument107 pagesCustom Blazor Oqtane Modules Succinctlylola lalolaNo ratings yet
- Oracle Payroll 'Subledger Accounting (SLA) ' Frequently Asked Questions (FAQ) (Doc ID 605635.1)Document4 pagesOracle Payroll 'Subledger Accounting (SLA) ' Frequently Asked Questions (FAQ) (Doc ID 605635.1)Hadi AamirNo ratings yet
- Prosave TutorialDocument30 pagesProsave TutorialJohnson ShodipoNo ratings yet
- Quiz FMGDocument11 pagesQuiz FMGJulien Comblé de Joie100% (1)
- Injector Trim File InstallDocument2 pagesInjector Trim File InstallnobodymagdesignNo ratings yet
- Top USB, audio, storage and network devicesDocument12 pagesTop USB, audio, storage and network devicesMokhammad Faisol AbdullahNo ratings yet
- FFT - Proactive Advanced Endpoint Protection, Visiblity and Control For Critical Assets v6.4r8 Lab GuideDocument126 pagesFFT - Proactive Advanced Endpoint Protection, Visiblity and Control For Critical Assets v6.4r8 Lab GuideSony EscriNo ratings yet
- Sap Hana DBDocument13 pagesSap Hana DBSARMANo ratings yet
- SAE J2534 Support Release NotesDocument4 pagesSAE J2534 Support Release NotesJose AGNo ratings yet
- Prison TransferDocument14 pagesPrison TransferVENKATA MANIKANTA SAI BHANU SAMUDRALA100% (2)
- Login Form: Code Sample: Ajaxapplications/Demos/Login - HTMLDocument24 pagesLogin Form: Code Sample: Ajaxapplications/Demos/Login - HTMLkishoreramanaNo ratings yet
- 758317-Neat Scanner ProDocument2 pages758317-Neat Scanner ProGARMAN LIUNo ratings yet
- SQL Server Installation Checklist2Document3 pagesSQL Server Installation Checklist2praveenmpkNo ratings yet
- DN NoteDocument37 pagesDN NoteHan HanNo ratings yet
- Carding Egift Cards On Amazon: Rob A Bank Carding CircleDocument10 pagesCarding Egift Cards On Amazon: Rob A Bank Carding CircleBruce StebbinsNo ratings yet
- SplunkFundamentals1 Module3Document9 pagesSplunkFundamentals1 Module3ealfora100% (1)
- Installing and Configuring Oracle GRC Using WeblogicDocument34 pagesInstalling and Configuring Oracle GRC Using Weblogicmohammed akbar aliNo ratings yet
- Zanti - Android App For Hackers - Haxf4rallDocument35 pagesZanti - Android App For Hackers - Haxf4rallDavid Vacca0% (1)
- Aws TutorialDocument11 pagesAws TutorialShamsuddin MalbariNo ratings yet
- 2 20201tt202 215944Document28 pages2 20201tt202 215944Evan JusephcaNo ratings yet
- 4G Post Consistency Update - P1MC51 52Document193 pages4G Post Consistency Update - P1MC51 52roniNo ratings yet
- Java Project Ideas Communication Networking SecurityDocument4 pagesJava Project Ideas Communication Networking Securityloganathan111No ratings yet
- Advance Steel Optional Additional Class Materials FAB197439L Up and Running With Advance Steel Deepak MainiDocument72 pagesAdvance Steel Optional Additional Class Materials FAB197439L Up and Running With Advance Steel Deepak MainiFongho Eric SinclairNo ratings yet
- ZHR Trigger HR ActionsDocument22 pagesZHR Trigger HR Actionsswadhin14No ratings yet
- How to Compile and Build Squid ProxyDocument7 pagesHow to Compile and Build Squid ProxyJavierNo ratings yet
- Course: Network Service Administrator Code BCN3043 Topic Lab Module: 3 DURATION: 2 HoursDocument6 pagesCourse: Network Service Administrator Code BCN3043 Topic Lab Module: 3 DURATION: 2 HoursDenny ChanNo ratings yet
- The System Requirements DocumentDocument4 pagesThe System Requirements DocumentDini HusainiNo ratings yet
- ITIL 4: Digital and IT strategy: Reference and study guideFrom EverandITIL 4: Digital and IT strategy: Reference and study guideRating: 5 out of 5 stars5/5 (1)
- Monitored: Business and Surveillance in a Time of Big DataFrom EverandMonitored: Business and Surveillance in a Time of Big DataRating: 4 out of 5 stars4/5 (1)
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- COBOL Basic Training Using VSAM, IMS and DB2From EverandCOBOL Basic Training Using VSAM, IMS and DB2Rating: 5 out of 5 stars5/5 (2)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]From EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Rating: 5 out of 5 stars5/5 (8)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- DB2 11 for z/OS: SQL Basic Training for Application DevelopersFrom EverandDB2 11 for z/OS: SQL Basic Training for Application DevelopersRating: 4 out of 5 stars4/5 (1)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- Joe Celko's SQL for Smarties: Advanced SQL ProgrammingFrom EverandJoe Celko's SQL for Smarties: Advanced SQL ProgrammingRating: 3 out of 5 stars3/5 (1)
- Oracle Database 12c Install, Configure & Maintain Like a Professional: Install, Configure & Maintain Like a ProfessionalFrom EverandOracle Database 12c Install, Configure & Maintain Like a Professional: Install, Configure & Maintain Like a ProfessionalNo ratings yet

























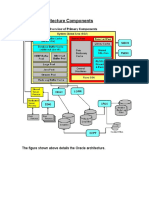
































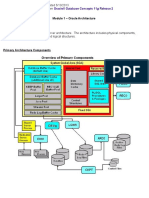
























































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-1-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1713743787?v=1)


















