You might also like
- Linear Space-State Control Systems Solutions ManualDocument141 pagesLinear Space-State Control Systems Solutions ManualOrlando Aguilar100% (4)
- Lecture 7Document126 pagesLecture 7suchi9mayNo ratings yet
- A Detailed Explanation of Solenoid ForceDocument8 pagesA Detailed Explanation of Solenoid ForceidescitationNo ratings yet
- Toward A Design Theory of Problem SolvingDocument24 pagesToward A Design Theory of Problem SolvingThiago GonzagaNo ratings yet
- A Language Independent Approach To Develop URDUIR SystemDocument10 pagesA Language Independent Approach To Develop URDUIR SystemCS & ITNo ratings yet
- Komputerisasi Penelitian Hukum DGN Teknologi Data MiningDocument8 pagesKomputerisasi Penelitian Hukum DGN Teknologi Data MiningsunnysamsuniNo ratings yet
- IRS NotesDocument10 pagesIRS NotesMohammad Zaid AnsariNo ratings yet
- Chapter 5 Web and Search EnginesDocument18 pagesChapter 5 Web and Search EnginesabrehamNo ratings yet
- IJCER (WWW - Ijceronline.com) International Journal of Computational Engineering ResearchDocument4 pagesIJCER (WWW - Ijceronline.com) International Journal of Computational Engineering ResearchInternational Journal of computational Engineering research (IJCER)No ratings yet
- Effective Classification of TextDocument6 pagesEffective Classification of TextseventhsensegroupNo ratings yet
- A Survey On Various Architectures, Models and Methodologies For Information RetrievalDocument13 pagesA Survey On Various Architectures, Models and Methodologies For Information RetrievalIAEME PublicationNo ratings yet
- Information Retrieval ThesisDocument5 pagesInformation Retrieval ThesisDaphne Smith100% (2)
- 43.IJCSCN PreprocessingTechniquesforTextMining Ilamathi NithyaDocument11 pages43.IJCSCN PreprocessingTechniquesforTextMining Ilamathi NithyaAshish DasNo ratings yet
- Saravanan ThesisDocument207 pagesSaravanan ThesisUnimarks Legal Solutions100% (1)
- Text Mining: A Burgeoning Technology For Knowledge ExtractionDocument5 pagesText Mining: A Burgeoning Technology For Knowledge Extractionijsret100% (1)
- 43.IJCSCN PreprocessingTechniquesforTextMining Ilamathi NithyaDocument11 pages43.IJCSCN PreprocessingTechniquesforTextMining Ilamathi NithyaHasdi SuhastraNo ratings yet
- AlamiMerrouni2020 Article AutomaticKeyphraseExtractionASDocument34 pagesAlamiMerrouni2020 Article AutomaticKeyphraseExtractionASmainakroniNo ratings yet
- Lab1-Algorithms For Information Retrieval. IntroductionDocument13 pagesLab1-Algorithms For Information Retrieval. IntroductionshanthinisampathNo ratings yet
- Unit 1 - Modern Information Retrieval - WWW - Rgpvnotes.inDocument8 pagesUnit 1 - Modern Information Retrieval - WWW - Rgpvnotes.inKunwar ÅyushNo ratings yet
- Semantic Information Retrieval Based On Domain OntologyDocument4 pagesSemantic Information Retrieval Based On Domain OntologyIntegrated Intelligent ResearchNo ratings yet
- Literature Review of Automatic Multiple Documents Text SummarizationDocument9 pagesLiterature Review of Automatic Multiple Documents Text Summarizationrabbikalia39No ratings yet
- Module 5 - Information Retrieval and Lexical ResourcesDocument80 pagesModule 5 - Information Retrieval and Lexical ResourcesAaron ChrisNo ratings yet
- Wikipidea - Concept SearchDocument7 pagesWikipidea - Concept SearchMichael ZockNo ratings yet
- en Single Document Automatic Text SummarizaDocument10 pagesen Single Document Automatic Text SummarizaAlfikri HikmatiarNo ratings yet
- Chapter One 1.1Document14 pagesChapter One 1.1factorialNo ratings yet
- Ir and NLPDocument6 pagesIr and NLPSachin PathareNo ratings yet
- Information Retrieval SystemDocument4 pagesInformation Retrieval SystemSonu DavidsonNo ratings yet
- IRS B Tech CSE Part 1Document161 pagesIRS B Tech CSE Part 1Rajput SinghNo ratings yet
- Text Mining Using Natural Language ProcessingDocument8 pagesText Mining Using Natural Language ProcessingIJRASETPublicationsNo ratings yet
- Keyword Extraction Issues and MethodsDocument33 pagesKeyword Extraction Issues and MethodsAlejandro Cuatecontzi AyalaNo ratings yet
- Text Analytics and Text Mining OverviewDocument16 pagesText Analytics and Text Mining OverviewShivangi PatelNo ratings yet
- Named Entity Recognition in Social Media DataDocument23 pagesNamed Entity Recognition in Social Media DataIJRASETPublicationsNo ratings yet
- Information Retrieval Algorithms: A Survey: Prabhakar RaghavanDocument8 pagesInformation Retrieval Algorithms: A Survey: Prabhakar RaghavanshanthinisampathNo ratings yet
- Research Papers On Information Retrieval SystemsDocument4 pagesResearch Papers On Information Retrieval Systemsgahebak1mez2100% (1)
- Dissertation Text MiningDocument4 pagesDissertation Text MiningPurchaseCollegePapersCanada100% (1)
- Information Retrieval Thesis PDFDocument4 pagesInformation Retrieval Thesis PDFjessicaoatisneworleans100% (2)
- Unstructured DataDocument6 pagesUnstructured Datajohn949No ratings yet
- Survey Data AnalysisDocument17 pagesSurvey Data Analysisrkarthik403No ratings yet
- Study of Effective AI Algorithms in Natural Language Processing in Todays EraDocument8 pagesStudy of Effective AI Algorithms in Natural Language Processing in Todays EraIJRASETPublicationsNo ratings yet
- Irt 2 Marks With AnswerDocument15 pagesIrt 2 Marks With AnswerAmaya EmaNo ratings yet
- Introduction To Information Extraction Technology: Douglas E. Appelt David J. IsraelDocument41 pagesIntroduction To Information Extraction Technology: Douglas E. Appelt David J. IsraelJumar Divinagracia DimpasNo ratings yet
- An Intelligent TLDR Software For SummarizationDocument6 pagesAn Intelligent TLDR Software For SummarizationIJRASETPublicationsNo ratings yet
- NLP Mod-5Document17 pagesNLP Mod-5sharonsajan438690No ratings yet
- A Statistical Approach To Perform Web Based Summarization: Kirti Bhatia, Dr. Rajendar ChhillarDocument3 pagesA Statistical Approach To Perform Web Based Summarization: Kirti Bhatia, Dr. Rajendar ChhillarInternational Organization of Scientific Research (IOSR)No ratings yet
- Information RetrievalDocument5 pagesInformation RetrievalNBNo ratings yet
- Thesis RetrievalDocument5 pagesThesis RetrievalScientificPaperWritingServicesCanada100% (2)
- Concept MiningDocument2 pagesConcept Miningolivia523No ratings yet
- UnitDocument35 pagesUnitshabir AhmadNo ratings yet
- The Role of Semantics in Searching For Information On The WebDocument12 pagesThe Role of Semantics in Searching For Information On The WebKrismadi SamosirNo ratings yet
- Unit:: A. Text Mining AlgorithmsDocument21 pagesUnit:: A. Text Mining Algorithmsshabir AhmadNo ratings yet
- IR Module For MIS RiftDocument80 pagesIR Module For MIS RiftalemuNo ratings yet
- Grammar Based Annotation Content Mapping in The Social Page in The Context of Short TextDocument3 pagesGrammar Based Annotation Content Mapping in The Social Page in The Context of Short TextInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- (IJCST-V9I6P4) :mohamed MinhajDocument7 pages(IJCST-V9I6P4) :mohamed MinhajEighthSenseGroupNo ratings yet
- Big Data Mining Literature ReviewDocument7 pagesBig Data Mining Literature Reviewea884b2k100% (1)
- Jaya D. Kapoor Alamuri Ratnamala Institute of Engineering and Technology, Shahpur Kailas K. Devadkar Sardar Patel Institute of Technology, AndheriDocument6 pagesJaya D. Kapoor Alamuri Ratnamala Institute of Engineering and Technology, Shahpur Kailas K. Devadkar Sardar Patel Institute of Technology, AndheriJyotiiBubnaRungtaNo ratings yet
- Stemming Information Retrieval Research PaperDocument8 pagesStemming Information Retrieval Research Papercakvaw0q100% (1)
- Tokenization: Token Normalization Is The Process of Canonicalizing Tokens So That Matches OccurDocument3 pagesTokenization: Token Normalization Is The Process of Canonicalizing Tokens So That Matches OccurhugoNo ratings yet
- 1 IR IntroDocument30 pages1 IR IntroMikiyas AbateNo ratings yet
- Ijermt Jan2019Document9 pagesIjermt Jan2019Deepak RathoreNo ratings yet
- Microcontroller Based Digital Trigger Circuit For ConverterDocument7 pagesMicrocontroller Based Digital Trigger Circuit For ConverteridescitationNo ratings yet
- Static-Noise-Margin Analysis of Modified 6T SRAM Cell During Read OperationDocument5 pagesStatic-Noise-Margin Analysis of Modified 6T SRAM Cell During Read OperationidescitationNo ratings yet
- Design of Series Feed Microstrip Patch Antenna Array Using HFSS SimulatorDocument4 pagesDesign of Series Feed Microstrip Patch Antenna Array Using HFSS SimulatoridescitationNo ratings yet
- Comparison of CMOS Current Mirror SourcesDocument5 pagesComparison of CMOS Current Mirror SourcesidescitationNo ratings yet
- Design of Switched Reluctance Motor For Three Wheeler Electric VehicleDocument4 pagesDesign of Switched Reluctance Motor For Three Wheeler Electric VehicleidescitationNo ratings yet
- MTJ-Based Nonvolatile 9T SRAM CellDocument5 pagesMTJ-Based Nonvolatile 9T SRAM CellidescitationNo ratings yet
- A New Approach For Error Reduction in Localization For Wireless Sensor NetworksDocument6 pagesA New Approach For Error Reduction in Localization For Wireless Sensor NetworksidescitationNo ratings yet
- Bersin PredictionsDocument55 pagesBersin PredictionsRahila Ismail Narejo100% (2)
- Grade 3Document4 pagesGrade 3Shai HusseinNo ratings yet
- Chapter 8 - FluidDocument26 pagesChapter 8 - FluidMuhammad Aminnur Hasmin B. HasminNo ratings yet
- BGL01 - 05Document58 pagesBGL01 - 05udayagb9443No ratings yet
- Facilitation TheoryDocument2 pagesFacilitation TheoryYessamin Valerie PergisNo ratings yet
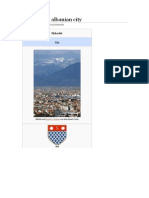
- Shkodër An Albanian CityDocument16 pagesShkodër An Albanian CityXINKIANGNo ratings yet
- Copper Reaction: Guillermo, Charles Hondonero, Christine Ilao, Ellaine Kim, Yumi Lambrinto, Arl JoshuaDocument6 pagesCopper Reaction: Guillermo, Charles Hondonero, Christine Ilao, Ellaine Kim, Yumi Lambrinto, Arl JoshuaCharles GuillermoNo ratings yet
- Test Statistics Fact SheetDocument4 pagesTest Statistics Fact SheetIra CervoNo ratings yet
- HIS Unit COMBINES Two Birthdays:: George Washington's BirthdayDocument9 pagesHIS Unit COMBINES Two Birthdays:: George Washington's BirthdayOscar Panez LizargaNo ratings yet
- Sysmex HemostasisDocument11 pagesSysmex HemostasisElyza L. de GuzmanNo ratings yet
- Easter in RomaniaDocument5 pagesEaster in RomaniaDragos IonutNo ratings yet
- Indus Valley Sites in IndiaDocument52 pagesIndus Valley Sites in IndiaDurai IlasunNo ratings yet
- TOPIC I: Moral and Non-Moral ProblemsDocument6 pagesTOPIC I: Moral and Non-Moral ProblemsHaydee Christine SisonNo ratings yet
- Anclas Placas Base para Columnas Thomas MurrayDocument89 pagesAnclas Placas Base para Columnas Thomas MurrayMariano DiazNo ratings yet
- The Personal Law of The Mahommedans, According To All The Schools (1880) Ali, Syed Ameer, 1849-1928Document454 pagesThe Personal Law of The Mahommedans, According To All The Schools (1880) Ali, Syed Ameer, 1849-1928David BaileyNo ratings yet
- Screening: of Litsea Salicifolia (Dighloti) As A Mosquito RepellentDocument20 pagesScreening: of Litsea Salicifolia (Dighloti) As A Mosquito RepellentMarmish DebbarmaNo ratings yet
- K.M Nanavati v. State of MaharashtraDocument6 pagesK.M Nanavati v. State of MaharashtraPushpank PandeyNo ratings yet
- Errol PNP Chief AzurinDocument8 pagesErrol PNP Chief AzurinDarren Sean NavaNo ratings yet
- Jurnal Politik Dan Cinta Tanah Air Dalam Perspektif IslamDocument9 pagesJurnal Politik Dan Cinta Tanah Air Dalam Perspektif Islamalpiantoutina12No ratings yet
- Graphic Organizers As A Reading Strategy: Research FindDocument9 pagesGraphic Organizers As A Reading Strategy: Research Findzwn zwnNo ratings yet
- BHP Billiton Foundations For Graduates Program Brochure 2012Document4 pagesBHP Billiton Foundations For Graduates Program Brochure 2012JulchairulNo ratings yet
- Google Automatically Generates HTML Versions of Documents As We Crawl The WebDocument2 pagesGoogle Automatically Generates HTML Versions of Documents As We Crawl The Websuchi ravaliaNo ratings yet
- From Jest To Earnest by Roe, Edward Payson, 1838-1888Document277 pagesFrom Jest To Earnest by Roe, Edward Payson, 1838-1888Gutenberg.org100% (1)
- Accountancy Department: Preliminary Examination in MANACO 1Document3 pagesAccountancy Department: Preliminary Examination in MANACO 1Gracelle Mae Oraller0% (1)
- Birds (Aves) Are A Group Of: WingsDocument1 pageBirds (Aves) Are A Group Of: WingsGabriel Angelo AbrauNo ratings yet
- Distributing Business Partner Master Data From SAP CRMDocument28 pagesDistributing Business Partner Master Data From SAP CRMJarko RozemondNo ratings yet
- Upload A Document To Access Your Download: The Psychology Book, Big Ideas Simply Explained - Nigel Benson PDFDocument3 pagesUpload A Document To Access Your Download: The Psychology Book, Big Ideas Simply Explained - Nigel Benson PDFchondroc11No ratings yet
- 2022 Drik Panchang Hindu FestivalsDocument11 pages2022 Drik Panchang Hindu FestivalsBikash KumarNo ratings yet