You might also like
- Linear Law Best FitDocument1 pageLinear Law Best FithazirahbaharinNo ratings yet
- Sheet No.15 Autocad ExercisesDocument1 pageSheet No.15 Autocad ExercisesHaitham YoussefNo ratings yet
- CARTA de SMITH - Acople de ImpedanciasDocument27 pagesCARTA de SMITH - Acople de ImpedanciasjhairNo ratings yet
- ECE333 Renewable Energy Systems 2015 Lect10Document30 pagesECE333 Renewable Energy Systems 2015 Lect10rdelgranadoNo ratings yet
- Brosur Takagi CP-40Document4 pagesBrosur Takagi CP-40reagan setiawanNo ratings yet
- Handout IntermediateDocument1 pageHandout Intermediatearmanulhaq60No ratings yet
- Week 10 L1Document9 pagesWeek 10 L1Venkat ReddiNo ratings yet
- #REF! #REF!: SukabumiDocument18 pages#REF! #REF!: SukabumiabahaangNo ratings yet
- Handout Intermediate MatplotlipDocument1 pageHandout Intermediate MatplotlipAbdo GaberNo ratings yet
- For Intermediate Users: Anatomy of A FigureDocument1 pageFor Intermediate Users: Anatomy of A FigureJHONNY OSORIO GALLEGONo ratings yet
- For Intermediate Users: Anatomy of A FigureDocument1 pageFor Intermediate Users: Anatomy of A FigureNotiyal SolutionsNo ratings yet
- Safety CultureDocument11 pagesSafety CultureSam SunNo ratings yet
- 2nd-Order System: Lab-808: Power Electronic Systems & Chips Lab., NCTU, TaiwanDocument12 pages2nd-Order System: Lab-808: Power Electronic Systems & Chips Lab., NCTU, Taiwanhord72No ratings yet
- AN010 - CT's Specification Guidelines For Pro-N, Xmore & Smart - 11 - 2022 PDFDocument12 pagesAN010 - CT's Specification Guidelines For Pro-N, Xmore & Smart - 11 - 2022 PDFPrje AccNo ratings yet
- AN010 CTs Specification Guidelines For Pro N Pro NX Smart 10 2016Document12 pagesAN010 CTs Specification Guidelines For Pro N Pro NX Smart 10 2016Petre GabrielNo ratings yet
- 1 PDFDocument1 page1 PDFYohannes HabeshawiNo ratings yet
- DVB-S2 Communication Chain ProjectDocument15 pagesDVB-S2 Communication Chain ProjectHuongNguyenNo ratings yet
- Plano Juntas FinalDocument1 pagePlano Juntas FinalJhon GomezNo ratings yet
- BAR 303 Attachment 4-5 - Column Design ChartsDocument3 pagesBAR 303 Attachment 4-5 - Column Design ChartsMuthomi MunyuaNo ratings yet
- Locating Poles and Zeros On S-Plane and Z-PlaneDocument1 pageLocating Poles and Zeros On S-Plane and Z-PlaneHafizuddinMahmadNo ratings yet
- Design Spectra Philippines Seismic Part 4Document144 pagesDesign Spectra Philippines Seismic Part 4Mike2322No ratings yet
- Ca8345-185567wfh-Ktx A - Thd-ADocument1 pageCa8345-185567wfh-Ktx A - Thd-ATuan LeNo ratings yet
- Column LayoutDocument1 pageColumn LayoutAlhanNo ratings yet
- 19MAT209 3 MVUO Geometrical AnalyticalSolnsDocument16 pages19MAT209 3 MVUO Geometrical AnalyticalSolnsSurya KotamrajaNo ratings yet
- Zone 3 & Soil SD Input Zone 3 & Soil SD Input: Ca T 1.3 DBE MCEDocument3 pagesZone 3 & Soil SD Input Zone 3 & Soil SD Input: Ca T 1.3 DBE MCEEngr Ghulam MustafaNo ratings yet
- w0698 PDFDocument1 pagew0698 PDFThiago Rocha GomesNo ratings yet
- Sub:-Working Drawing: Title:-Column Layout PlanDocument1 pageSub:-Working Drawing: Title:-Column Layout Planfasi rahmanNo ratings yet
- High Pass Filter Frequency ResponseDocument6 pagesHigh Pass Filter Frequency ResponseMohsin TariqNo ratings yet
- Sub:-Working Drawing: Title:-Column Layout PlanDocument1 pageSub:-Working Drawing: Title:-Column Layout PlanFasi Rahman AbrarNo ratings yet
- Sub:-Working Drawing: Title:-Column Layout PlanDocument1 pageSub:-Working Drawing: Title:-Column Layout PlanFasi Rahman AbrarNo ratings yet
- Sub:-Working Drawing: Title:-Column Layout PlanDocument1 pageSub:-Working Drawing: Title:-Column Layout Planfasi rahmanNo ratings yet
- Summary Advancements in Full-Scale Wind Engineering Experimental FacilitiesDocument20 pagesSummary Advancements in Full-Scale Wind Engineering Experimental FacilitiesPetr M.No ratings yet
- FLOOR PLAN A PDFDocument1 pageFLOOR PLAN A PDFYohannes HabeshawiNo ratings yet
- Reinforcement Detail: Section A-ADocument1 pageReinforcement Detail: Section A-AAnup KhoslaNo ratings yet
- Temperature distribution in solid with convection boundaryDocument11 pagesTemperature distribution in solid with convection boundaryEdwin Orozco ReyesNo ratings yet
- Using graphics and pictures in L TEX 2ε: 1 The picture environmentDocument3 pagesUsing graphics and pictures in L TEX 2ε: 1 The picture environmentnalluri_08No ratings yet
- p4f Mockup v3Document1 pagep4f Mockup v3beisenbergNo ratings yet
- Ejemplo 8.15 Seader: Edward Alejandro TorresDocument5 pagesEjemplo 8.15 Seader: Edward Alejandro TorresPaulina Velandia LopezNo ratings yet
- Diagram Layang Analisis Swot O: Turn Arround AgresifDocument2 pagesDiagram Layang Analisis Swot O: Turn Arround AgresifRiki96No ratings yet
- Distribucion 1Document1 pageDistribucion 1ANYELI VALERIA QUIROZ LOPEZNo ratings yet
- View Factor TablesDocument2 pagesView Factor TablesGayashan KulathungaNo ratings yet
- P 1Document1 pageP 1hedayatullahNo ratings yet
- Compact Photocouplers with Single, Dual, and Quad ChannelsDocument3 pagesCompact Photocouplers with Single, Dual, and Quad ChannelsLuigi PortugalNo ratings yet
- Effectiveness-NTU Curves For Shell and Tube Heat Exchangers: Min MaxDocument2 pagesEffectiveness-NTU Curves For Shell and Tube Heat Exchangers: Min MaxKwark SangNo ratings yet
- Hábitat PlanoDocument1 pageHábitat PlanoAna Paula HNo ratings yet
- Fig 31 PDFDocument1 pageFig 31 PDFEdrian SantosNo ratings yet
- EquipoDocument6 pagesEquipoJuan QuintanaNo ratings yet
- CH4-Root Locus Design PDFDocument11 pagesCH4-Root Locus Design PDFLove StrikeNo ratings yet
- Load Chart - Stc500Document2 pagesLoad Chart - Stc500Jorge L.0% (1)
- Surface Plot of Sine and Exponential FunctionsDocument2 pagesSurface Plot of Sine and Exponential FunctionsSaied Aly SalamahNo ratings yet
- Relationship between mass, time and areaDocument3 pagesRelationship between mass, time and areaLukas KristovićNo ratings yet
- Smitch ChartDocument3 pagesSmitch ChartBharat ChNo ratings yet
- Reinforcement Detail: Section AaDocument1 pageReinforcement Detail: Section AaAnup KhoslaNo ratings yet
- Dinamicateta 1 FixDocument8 pagesDinamicateta 1 FixAlin DiaconuNo ratings yet
- PlaaaaaaDocument1 pagePlaaaaaaAbdirizak HusseinNo ratings yet
- 15 FIR Filter Design by WindowingDocument9 pages15 FIR Filter Design by Windowingnitesh mudgalNo ratings yet
- (I) Re 10 (Iii) Re 100 (Ii) Re 40Document5 pages(I) Re 10 (Iii) Re 100 (Ii) Re 40Asif MohammadNo ratings yet
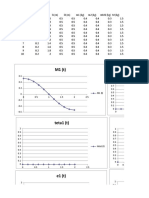
- V Rectificador I Rectificador 0.2 0 0.3 0 0.4 0.12 0.5 0.21 0.6 2.11 0.7 11.41Document3 pagesV Rectificador I Rectificador 0.2 0 0.3 0 0.4 0.12 0.5 0.21 0.6 2.11 0.7 11.41Galeria de ShitpostNo ratings yet
- Financial Applications using Excel Add-in Development in C / C++From EverandFinancial Applications using Excel Add-in Development in C / C++No ratings yet
- Numpy Idx TutDocument14 pagesNumpy Idx Tutdignor.sign3941No ratings yet
- Rolling The Dice FasterDocument4 pagesRolling The Dice Fasterdignor.sign3941No ratings yet
- Unfolded InsertDocument5 pagesUnfolded Insertdignor.sign3941No ratings yet
- Understanding Cover TreesDocument4 pagesUnderstanding Cover Treesdignor.sign3941No ratings yet
- Microsoft Office PowerPoint Shortcuts KeysDocument4 pagesMicrosoft Office PowerPoint Shortcuts KeyssheriffdeenaladeNo ratings yet
- Loan Application Form TCHFLDocument4 pagesLoan Application Form TCHFLxyzNo ratings yet
- DSA Lab Program - 5Document4 pagesDSA Lab Program - 5kashafaznain5No ratings yet
- HRMS User ManualDocument30 pagesHRMS User ManualNino Joshua CastinoNo ratings yet
- 6969864_20210130230106523 (1)-1Document411 pages6969864_20210130230106523 (1)-1Kelly. cutyNo ratings yet
- TSP Launch Postmortem Meeting - Script LAUPM Purpose Entry CriteriaDocument1 pageTSP Launch Postmortem Meeting - Script LAUPM Purpose Entry CriteriajorgeNo ratings yet
- Más Teoría de ConverDocument76 pagesMás Teoría de ConverAngelNo ratings yet
- A Convenient Approach For Penalty Parameter Selection in Robust Lasso RegressionDocument12 pagesA Convenient Approach For Penalty Parameter Selection in Robust Lasso Regressionasfar as-salafiyNo ratings yet
- Website: Vce To PDF Converter: Facebook: Twitter:: 300-535.vceplus - Premium.Exam.60QDocument35 pagesWebsite: Vce To PDF Converter: Facebook: Twitter:: 300-535.vceplus - Premium.Exam.60QAla JebnounNo ratings yet
- Exposé AnglaisDocument8 pagesExposé AnglaisAnichatou BELEMNo ratings yet
- Android system log errors and warningsDocument49 pagesAndroid system log errors and warningsARCANGEL Airiel jhoiceNo ratings yet
- Rebuilding Tourism Post-COVIDDocument24 pagesRebuilding Tourism Post-COVIDMaria Angela BarrigaNo ratings yet
- Module 3Document55 pagesModule 3Vincent luiNo ratings yet
- International - Rectifier 92 0065 DatasheetDocument85 pagesInternational - Rectifier 92 0065 DatasheetDomenico ScorranoNo ratings yet
- Hetzner 2022-12-05 R0017636179Document1 pageHetzner 2022-12-05 R0017636179Vladimir PetrovNo ratings yet
- B.Tech EEE112 Principles of Electrical and Electronics EngineeringDocument3 pagesB.Tech EEE112 Principles of Electrical and Electronics EngineeringAkash GandharNo ratings yet
- PSP FullNotes Backbencher - ClubDocument99 pagesPSP FullNotes Backbencher - Clubkaranphutane2254No ratings yet
- Appendix 1 (For Clinical Departments) Information Security and Privacy Compliance Audit RequirementsDocument4 pagesAppendix 1 (For Clinical Departments) Information Security and Privacy Compliance Audit RequirementsHui Lok SZENo ratings yet
- Helical Gearmotor SpecificationsDocument5 pagesHelical Gearmotor Specificationsdeepak kumarNo ratings yet
- Phạm Lê Ngọc Sơn - 2051185 - - DSP - LAB3 - - FINALDocument25 pagesPhạm Lê Ngọc Sơn - 2051185 - - DSP - LAB3 - - FINALNgọc Khánh100% (1)
- Module 1 - Flat IronDocument7 pagesModule 1 - Flat IronROJANE F. BERNAS, PhD.100% (3)
- Sigma A-Cp: Conventional Control PanelDocument2 pagesSigma A-Cp: Conventional Control PanelEngTyranNo ratings yet
- Koppel KFM36E2 Package Type Floor Mounted Air ConditionerDocument2 pagesKoppel KFM36E2 Package Type Floor Mounted Air ConditionerpogisimpatikoNo ratings yet
- Enterprise Resource Planning ERP EvaluatDocument18 pagesEnterprise Resource Planning ERP EvaluatEdnan HanNo ratings yet
- Powershell Quick Reference - Security and Compliance CenterDocument6 pagesPowershell Quick Reference - Security and Compliance CenterdemoNo ratings yet
- Javascript SnowfallDocument4 pagesJavascript Snowfallccatalin10No ratings yet
- Installation of SAP Content Server 7.5 and Higher On UnixDocument60 pagesInstallation of SAP Content Server 7.5 and Higher On UnixAdauto PolizeliNo ratings yet
- 4jer en - Tze00086 PDFDocument6 pages4jer en - Tze00086 PDFr0ll3rNo ratings yet
- Media InvitationDocument3 pagesMedia InvitationMoneesh MsNo ratings yet
- ES Final Jan10 PDFDocument6 pagesES Final Jan10 PDFKaemryn SaeNo ratings yet