You might also like
- 4779 705057 PDFDocument78 pages4779 705057 PDFidsuNo ratings yet
- MetGP PDFDocument5 pagesMetGP PDFidsuNo ratings yet
- Calendrier 2014Document6 pagesCalendrier 2014idsuNo ratings yet
- Calendrier 2014.odsDocument4 pagesCalendrier 2014.odsidsuNo ratings yet
- Calendrier 2014.odsDocument4 pagesCalendrier 2014.odsidsuNo ratings yet
- Cal - 2014 PDFDocument4 pagesCal - 2014 PDFidsuNo ratings yet
- Cours Max VraisDocument18 pagesCours Max VraisidsuNo ratings yet
- Modele GARCH Analyse CvarDocument34 pagesModele GARCH Analyse CvaridsuNo ratings yet
- 4779 705054 PDFDocument79 pages4779 705054 PDFidsuNo ratings yet
- CourseDocument266 pagesCoursemustapha_005100% (1)
- Cours FinanceDocument78 pagesCours FinanceidsuNo ratings yet
- Chap3 EAUCHAUDESANITAIREDocument40 pagesChap3 EAUCHAUDESANITAIREDjiriga Michel GnahoreNo ratings yet
- Calendrier Mai 2014Document1 pageCalendrier Mai 2014idsuNo ratings yet
- Cours FinanceDocument78 pagesCours FinanceidsuNo ratings yet
- ThermExcel - Programme HydroExcelDocument25 pagesThermExcel - Programme HydroExcelidsuNo ratings yet
- Sys HydrauliqueDocument15 pagesSys HydrauliqueidsuNo ratings yet
- Allocation Dynamique Coeur SatelliteDocument6 pagesAllocation Dynamique Coeur SatelliteidsuNo ratings yet
- ThermExcel - Programme HydroWaterDocument26 pagesThermExcel - Programme HydroWateridsuNo ratings yet
- ThermExcel - Programme Calcul EvacuationsDocument21 pagesThermExcel - Programme Calcul Evacuationsidsu100% (2)
- Appareils de ProducECS DimensionnementDocument60 pagesAppareils de ProducECS DimensionnementReda Guellil0% (1)
- 04 01 08la Conception Des Installations de Distribution D Eau SanitaireDocument54 pages04 01 08la Conception Des Installations de Distribution D Eau SanitaireidsuNo ratings yet
- 4 Etude de Cas Systemes HydroliqueDocument23 pages4 Etude de Cas Systemes Hydroliquesalma_herriNo ratings yet
- Flex InvestDocument12 pagesFlex InvestidsuNo ratings yet
- Modulo Control Doc Technique Atlantic GuillotDocument64 pagesModulo Control Doc Technique Atlantic Guillotidsu0% (1)
- Position 1 BasseDocument3 pagesPosition 1 BasseidsuNo ratings yet
- Fiche Blues - Fiche BluesDocument2 pagesFiche Blues - Fiche BluesidsuNo ratings yet
- Man ChesDocument1 pageMan ChesidsuNo ratings yet
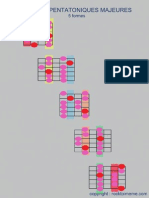
- Penttonic MajeurDocument1 pagePenttonic MajeuridsuNo ratings yet
- Accords Simples PositionDocument17 pagesAccords Simples PositionidsuNo ratings yet
- ControleAut19 PDFDocument3 pagesControleAut19 PDFazzamNo ratings yet
- Rapport tp2 Deep LearningDocument10 pagesRapport tp2 Deep LearningM MAXNo ratings yet
- Optimisation ContinueDocument2 pagesOptimisation ContinueSerigne GueyeNo ratings yet
- FE07 - PolynômesDocument10 pagesFE07 - PolynômesTom BarNo ratings yet
- TP3 Résolution Des Équations Non LinéaireDocument3 pagesTP3 Résolution Des Équations Non Linéairebriki ayoubNo ratings yet
- Cour Algèbre1Document32 pagesCour Algèbre1Aymen BaccoucheNo ratings yet
- Cours de Simulation Et Modélisation en HydrauliqueDocument19 pagesCours de Simulation Et Modélisation en Hydrauliqueléa's SpaceNo ratings yet
- TDcor MNBDocument81 pagesTDcor MNBjames nortonNo ratings yet
- Polycopie ANIDocument68 pagesPolycopie ANImarwen12345No ratings yet
- Chapitre2 Méthode de GAUSSDocument7 pagesChapitre2 Méthode de GAUSSمنير راميNo ratings yet
- Liste Des Exposés STIC 2022-2023Document1 pageListe Des Exposés STIC 2022-2023saidista2021No ratings yet
- TD4 Séance.1.Document4 pagesTD4 Séance.1.Badre OuzougarNo ratings yet
- TP 03Document4 pagesTP 03Abdelkader HaouariNo ratings yet
- Calcul Formel Et Numerique in French Handbook of The Numerical Analysis Course of ULB Computer Science DepartmentDocument166 pagesCalcul Formel Et Numerique in French Handbook of The Numerical Analysis Course of ULB Computer Science DepartmentboboyiNo ratings yet
- TD - CH3 Méthodes Indirectes2023 PDFDocument2 pagesTD - CH3 Méthodes Indirectes2023 PDFTriEmblem 6No ratings yet
- 2F Cours Methodes Locales PDFDocument7 pages2F Cours Methodes Locales PDFkaytokid2No ratings yet
- MEF DK Chap2 2 InterpolationDocument21 pagesMEF DK Chap2 2 InterpolationMohamed SelmiNo ratings yet
- Chap 01 - Ex 3B - Résolutions D'équations Du Second Degré - CORRIGEDocument3 pagesChap 01 - Ex 3B - Résolutions D'équations Du Second Degré - CORRIGEsalmaahrdNo ratings yet
- Analyse Numerique 2Document16 pagesAnalyse Numerique 2Aymen AbbaNo ratings yet
- IA Chap4Document19 pagesIA Chap4Meriem cherguiNo ratings yet
- Chap 2 DDocument7 pagesChap 2 DExion GroupNo ratings yet
- Anal Num RouibaDocument47 pagesAnal Num RouibaMohammed Baha Eddine FETNACINo ratings yet
- TD Polynomes ENSAM-2Document2 pagesTD Polynomes ENSAM-2HIBA BOUKELLOUCHENo ratings yet
- Comparaison UsuelleDocument2 pagesComparaison UsuellemissdropaNo ratings yet
- Mathématiques - Correction Exercice 4Document2 pagesMathématiques - Correction Exercice 4contact_swadonNo ratings yet
- Dicho TomieDocument5 pagesDicho Tomiemn13hhNo ratings yet
- MAH4444Document139 pagesMAH4444بلقاسم جلاليNo ratings yet
- Univ Orleans Plaquette Master Mathématiques Appliquées 2022Document2 pagesUniv Orleans Plaquette Master Mathématiques Appliquées 2022mohamedNo ratings yet
- Correction Exercice 3 AnDocument18 pagesCorrection Exercice 3 Anoussama.ahmedNo ratings yet
- E Fini Important PDFDocument256 pagesE Fini Important PDFMarouane Samadi100% (1)