You might also like
- Using The Write Accelerator From TMSDocument18 pagesUsing The Write Accelerator From TMSAmila KumanayakeNo ratings yet
- What Is A Checkpoint?Document7 pagesWhat Is A Checkpoint?Prabhat BhushanNo ratings yet
- Tuning The Redo Log BufferDocument3 pagesTuning The Redo Log BufferSHAHID FAROOQNo ratings yet
- Tuning The Redolog Buffer Cache and Resolving Redo Latch ContentionDocument5 pagesTuning The Redolog Buffer Cache and Resolving Redo Latch ContentionMelissa MillerNo ratings yet
- Awr Report AnalysisDocument43 pagesAwr Report Analysismaheshsrikakula1162No ratings yet
- TuningDocument53 pagesTuningbalajismithNo ratings yet
- Generating Awr ReportDocument3 pagesGenerating Awr ReportnitdkNo ratings yet
- Oracle RedologDocument26 pagesOracle RedologAMEYNo ratings yet
- Interpret Statspack ReportDocument9 pagesInterpret Statspack ReportaryadipayudhanaNo ratings yet
- 9ib HADRDocument179 pages9ib HADRapi-3831209No ratings yet
- Oracle Rdbms KeypointsDocument1,439 pagesOracle Rdbms Keypointsdeepak1133100% (2)
- SPDocument4 pagesSPbaraka08No ratings yet
- Checkpoint Tuning and Troubleshooting GuideDocument8 pagesCheckpoint Tuning and Troubleshooting GuideMelissa MillerNo ratings yet
- Applies To:: Checkpoint Tuning and Troubleshooting Guide (Doc ID 147468.1)Document6 pagesApplies To:: Checkpoint Tuning and Troubleshooting Guide (Doc ID 147468.1)Jon HiaaNo ratings yet
- Performance TuningDocument38 pagesPerformance TuningAnweshKota100% (1)
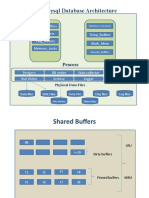
- Postgresql DBA ArchitectureDocument60 pagesPostgresql DBA ArchitectureRakesh DBANo ratings yet
- 2013 544 Sagrillo PPTDocument34 pages2013 544 Sagrillo PPTThota Mahesh DbaNo ratings yet
- Internals of PostgreSQL WalDocument51 pagesInternals of PostgreSQL WalSrikanth Pentakota100% (1)
- Oracle DBA 11gR2 ArchitectureDocument9 pagesOracle DBA 11gR2 ArchitectureAzmath Tech TutsNo ratings yet
- Exadata X3 in Action: Measuring Smart Scan Efficiency With AWRDocument7 pagesExadata X3 in Action: Measuring Smart Scan Efficiency With AWRFranck PachotNo ratings yet
- Addmrpt 1 36561 36562Document5 pagesAddmrpt 1 36561 36562Anonymous ZGcs7MwsLNo ratings yet
- Chapter - 1: Oracle Architecture - Module 1Document39 pagesChapter - 1: Oracle Architecture - Module 1Vivek MeenaNo ratings yet
- Oe InterviewDocument51 pagesOe InterviewnareshNo ratings yet
- 10gnew FeaturesDocument141 pages10gnew FeaturesPrateek DaveNo ratings yet
- Oracle Instance ArchitectureDocument28 pagesOracle Instance ArchitecturemonsonNo ratings yet
- 2014-Db-Franck Pachot-Interpreting Awr Reports Straight To The Goal-ManuskriptDocument11 pages2014-Db-Franck Pachot-Interpreting Awr Reports Straight To The Goal-ManuskriptAnonymous OBPVTEuQLNo ratings yet
- Addmrpt 1 36558 36559Document7 pagesAddmrpt 1 36558 36559Anonymous ZGcs7MwsLNo ratings yet
- BIAS Recommended SettingsDocument6 pagesBIAS Recommended SettingsniaamNo ratings yet
- Performacne - Tuning - Vol1 (Unlock) - 5Document50 pagesPerformacne - Tuning - Vol1 (Unlock) - 5ChristianQuirozPlefkeNo ratings yet
- PT Vol1-3 PDFDocument100 pagesPT Vol1-3 PDFshafeeq1985gmailNo ratings yet
- AWR Reports (Part I) - 10 Most Important Bits PDFDocument4 pagesAWR Reports (Part I) - 10 Most Important Bits PDFModesto Lopez RamosNo ratings yet
- Oracle Database Oracle Instance + Data Files: AsktomDocument5 pagesOracle Database Oracle Instance + Data Files: Asktomvaloo_phoolNo ratings yet
- MMM MM M M MMMM M MMMMMMMMMMMMMMM M MM MMMMMMMMM MMMMMMMMMMMDocument10 pagesMMM MM M M MMMM M MMMMMMMMMMMMMMM M MM MMMMMMMMM MMMMMMMMMMMLokesh ChinniNo ratings yet
- How To Read Awr ReportDocument22 pagesHow To Read Awr Reportsoma3nathNo ratings yet
- Chapter 1. Oracle Database ArchitectureDocument7 pagesChapter 1. Oracle Database ArchitectureAdryan AnghelNo ratings yet
- Tuning Buffer Busy Waits With FreelistsDocument9 pagesTuning Buffer Busy Waits With FreelistsharipemmasaniNo ratings yet
- Oracle ArchitectureDocument102 pagesOracle ArchitecturemanavalanmichaleNo ratings yet
- Report Statspack 2dayDocument4 pagesReport Statspack 2dayghassenNo ratings yet
- 2.1 - DB2 Backup and Recovery - LabDocument15 pages2.1 - DB2 Backup and Recovery - LabraymartomampoNo ratings yet
- How To Read AWR ReportsDocument17 pagesHow To Read AWR Reportsbabitae100% (1)
- Advanced Internal Oracle Tuning Techniques For SAP SystemsDocument79 pagesAdvanced Internal Oracle Tuning Techniques For SAP SystemsMarri MahipalNo ratings yet
- Oracle Architechture & ConceptsDocument90 pagesOracle Architechture & ConceptsElango GopalNo ratings yet
- Checkpoint Tuning and Troubleshooting GuideDocument14 pagesCheckpoint Tuning and Troubleshooting Guidegkiran_chNo ratings yet
- Background Processes in OracleDocument12 pagesBackground Processes in OracleGautam TrivediNo ratings yet
- Maa GG Performance 1969630Document51 pagesMaa GG Performance 1969630sjkhappsNo ratings yet
- Oracle Performance Tuning Part 7Document21 pagesOracle Performance Tuning Part 7tavi.firceaNo ratings yet
- Awr Report AnalysisDocument13 pagesAwr Report Analysissrinivas1224No ratings yet
- Analysing Oracle AWR2Document17 pagesAnalysing Oracle AWR2Anil ReddyNo ratings yet
- Reading Statspack ReportDocument24 pagesReading Statspack Reportravtank1982_28100% (1)
- Oracle Database ArchitectureDocument7 pagesOracle Database ArchitecturearavinthNo ratings yet
- Cpanellogd PDFDocument14 pagesCpanellogd PDFAhmed MekkiNo ratings yet
- Automatic Shared Memory Management in Oracle 10g: ZahidDocument10 pagesAutomatic Shared Memory Management in Oracle 10g: ZahidNst TnagarNo ratings yet
- 14jan Bangkok - HPE 3PAR NVMe-SCMDocument56 pages14jan Bangkok - HPE 3PAR NVMe-SCMNarongNacity NaNo ratings yet
- Exadata Support ChecklistDocument7 pagesExadata Support Checklistshaikali1980No ratings yet
- 4602 - r11x - Bestpractices - AutosysDocument13 pages4602 - r11x - Bestpractices - AutosysRavi DNo ratings yet
- Oracle 11g R1/R2 Real Application Clusters EssentialsFrom EverandOracle 11g R1/R2 Real Application Clusters EssentialsRating: 5 out of 5 stars5/5 (1)
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Preliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960From EverandPreliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960No ratings yet
- Understand Sultan Bahu Poetry by Sharief Sabir WorkDocument216 pagesUnderstand Sultan Bahu Poetry by Sharief Sabir WorkSHAHID FAROOQNo ratings yet
- Remedies From The Holy Qur'AnDocument79 pagesRemedies From The Holy Qur'Anislamiq98% (220)
- Fazli Anwar e ElahiDocument95 pagesFazli Anwar e ElahiSHAHID FAROOQNo ratings yet
- Ibtidai Suluk (Urdu)Document28 pagesIbtidai Suluk (Urdu)Jalalludin Ahmad Ar-Rowi100% (1)
- Baba Bulehshah Punjabi Read PDF FormatDocument440 pagesBaba Bulehshah Punjabi Read PDF FormatSHAHID FAROOQNo ratings yet
- Tears of Rasool PBUH UrduDocument72 pagesTears of Rasool PBUH Urduapi-3704968100% (3)
- All About Tracing Oracle SQL SessionsDocument12 pagesAll About Tracing Oracle SQL SessionsSHAHID FAROOQNo ratings yet
- Dil Daryia SamundarDocument303 pagesDil Daryia SamundarSHAHID FAROOQNo ratings yet
- Waseela Mufti M Faiz Awasi Qadri UrduDocument28 pagesWaseela Mufti M Faiz Awasi Qadri UrduSHAHID FAROOQNo ratings yet
- Anguthay ChoomnaDocument90 pagesAnguthay ChoomnaISLAMIC LIBRARYNo ratings yet
- Wazu Ka TareekaDocument20 pagesWazu Ka TareekaSHAHID FAROOQNo ratings yet
- Syeda Fatima (A.s)Document71 pagesSyeda Fatima (A.s)Syed Imran Shah100% (1)
- Was Eel ADocument158 pagesWas Eel ASHAHID FAROOQNo ratings yet
- Sultan Bahu PoetryDocument216 pagesSultan Bahu PoetrySHAHID FAROOQNo ratings yet
- Imam-e-Aazam Awr Imam Bukhari (Nisbat o Taaluq Awr Wajuhaat e Adam-e-Riwayat) Part-2Document66 pagesImam-e-Aazam Awr Imam Bukhari (Nisbat o Taaluq Awr Wajuhaat e Adam-e-Riwayat) Part-2MinhajBooksNo ratings yet
- Tabarrakut (Relics) Are Blessings (Urdu)Document64 pagesTabarrakut (Relics) Are Blessings (Urdu)faisal.noori5932No ratings yet
- Hujjat Allah Al-Baligha (Arabic / Urdu) by Shah Waliullah / Shah Wali UllahDocument1 pageHujjat Allah Al-Baligha (Arabic / Urdu) by Shah Waliullah / Shah Wali UllahRana Mazhar75% (4)
- Nijasaton Kee Pehchaan (Urdu)Document23 pagesNijasaton Kee Pehchaan (Urdu)faisal.noori5932No ratings yet
- Remedies From The Holy Qur'AnDocument79 pagesRemedies From The Holy Qur'Anislamiq98% (220)
- Sirr Al Israr Urdu by Sh. Gilani R.ADocument204 pagesSirr Al Israr Urdu by Sh. Gilani R.ASHAHID FAROOQNo ratings yet
- Complete 136Document25 pagesComplete 136ISLAMIC LIBRARYNo ratings yet
- Fatuh Al Ghaib Urdu by Sh. Gilani R.A Urdu TranslationDocument167 pagesFatuh Al Ghaib Urdu by Sh. Gilani R.A Urdu TranslationSHAHID FAROOQ100% (4)
- Nuh Ha Mim Keller - Kalam and IslamDocument14 pagesNuh Ha Mim Keller - Kalam and IslamMTYKK100% (8)
- Hazrat Fatima Sayeda e Qainaat (R.A)Document122 pagesHazrat Fatima Sayeda e Qainaat (R.A)Faisal MalikNo ratings yet
- Biography of Naqhsbandi Shuyukh (Urdu)Document108 pagesBiography of Naqhsbandi Shuyukh (Urdu)Talib Ghaffari100% (1)
- Naat - Subze Gumbad Kay Sayee MainDocument200 pagesNaat - Subze Gumbad Kay Sayee MainKaleem Ahmed100% (10)
- Dil Daryia SamundarDocument303 pagesDil Daryia SamundarSHAHID FAROOQNo ratings yet
- Dreams in Islam - The Window To The Heart! by Shaikh. Imran Nazar HoseinDocument105 pagesDreams in Islam - The Window To The Heart! by Shaikh. Imran Nazar Hoseinm.suh100% (10)
- Aqeedah WastiyahDocument97 pagesAqeedah Wastiyahapi-3700670No ratings yet
- 99 Perfect Names and Attributes of AllahDocument5 pages99 Perfect Names and Attributes of AllahSHAHID FAROOQNo ratings yet
- SQL Interview Questions and AnswersDocument4 pagesSQL Interview Questions and AnswerssudhakarsoornaNo ratings yet
- Mirasys VMS 7.5 Administrator Guide ENDocument159 pagesMirasys VMS 7.5 Administrator Guide ENjerryrapNo ratings yet
- How Singapore Is Paving The Way For Global Smart Cities: Sumeet Puri VP, Systems Engineering, InternationalDocument25 pagesHow Singapore Is Paving The Way For Global Smart Cities: Sumeet Puri VP, Systems Engineering, InternationalГоша ЗемлянкоNo ratings yet
- ABAP TestsDocument25 pagesABAP TestsSwati Jain100% (1)
- Module 5Document118 pagesModule 5Naresh Batra AssociatesNo ratings yet
- Difference Between SE CS and ITDocument5 pagesDifference Between SE CS and ITDaniyal NisarNo ratings yet
- Merlin-V3.6.1 Quick Reference Guide - QRG-000009-01-ENDocument2 pagesMerlin-V3.6.1 Quick Reference Guide - QRG-000009-01-ENIkunduNo ratings yet
- Uwu2x Guide Better Version Than The One in Uwu2x.zipDocument6 pagesUwu2x Guide Better Version Than The One in Uwu2x.zipmichalstegnerskiiNo ratings yet
- B.Tech. (CSE) - 7 - 23 - 10 - 2016 PDFDocument15 pagesB.Tech. (CSE) - 7 - 23 - 10 - 2016 PDFyawar sajadkNo ratings yet
- Mscdn-Mp1 Technical Manual: Capacitor Bank Overall Differential and Capacitor Unbalance ProtectionDocument3 pagesMscdn-Mp1 Technical Manual: Capacitor Bank Overall Differential and Capacitor Unbalance Protectionpepaboh820No ratings yet
- BNHS Computer Laboratory RulesDocument2 pagesBNHS Computer Laboratory RulesmichaelalangcasNo ratings yet
- Connor Brady Resume Ocr 2017Document1 pageConnor Brady Resume Ocr 2017api-284104482No ratings yet
- Koletzke Lock It Down PLSQL Security FeaturesDocument17 pagesKoletzke Lock It Down PLSQL Security Featuresjlc1967No ratings yet
- Nischals ResumeDocument2 pagesNischals ResumeHumanshu AroraNo ratings yet
- Informatica Cloud For NYFDocument19 pagesInformatica Cloud For NYFKishorNo ratings yet
- DBMS Exercise Final TemplateDocument27 pagesDBMS Exercise Final TemplateMamunur RashidNo ratings yet
- Director Project Portfolio Management in Sacramento CA Resume Carl ReedDocument2 pagesDirector Project Portfolio Management in Sacramento CA Resume Carl ReedCarlReed2No ratings yet
- Consumerdirect OnesheetDocument1 pageConsumerdirect OnesheetbharatposwalNo ratings yet
- PHP AJAX Programming - PhppotDocument4 pagesPHP AJAX Programming - PhppotAsmaNo ratings yet
- ISO-IEC 20000 Foundation Exam Sample Paper - January 2014Document16 pagesISO-IEC 20000 Foundation Exam Sample Paper - January 2014chiwaicNo ratings yet
- Chapter 3 Memory and Basic IO InterfaceDocument39 pagesChapter 3 Memory and Basic IO InterfacetesfayebbNo ratings yet
- NCC KAUNGSINTHANT 00185277 OSD AssignmentDocument32 pagesNCC KAUNGSINTHANT 00185277 OSD AssignmentKaung Sin Thant100% (1)
- Cloud Digital Leader Best Training Material and Practice Test Q&A FromDocument60 pagesCloud Digital Leader Best Training Material and Practice Test Q&A Fromhitesh100% (3)
- Implementing Enterprise Storage SolutionsDocument36 pagesImplementing Enterprise Storage SolutionsSanitaracNo ratings yet
- NAME: Nirmal Nemade Class: Te-5-B Roll No: 27Document16 pagesNAME: Nirmal Nemade Class: Te-5-B Roll No: 27Nirmal NemadeNo ratings yet
- Manual Testing Interview QuestionsDocument21 pagesManual Testing Interview QuestionspoorilonavalaNo ratings yet
- Citra Log - Txt.oldDocument15 pagesCitra Log - Txt.oldTavo BetancourtNo ratings yet
- Panorama AdminDocument478 pagesPanorama AdminThilaga Raj100% (1)
- Naukri Manrajkaur (12y 0m)Document2 pagesNaukri Manrajkaur (12y 0m)Arup NaskarNo ratings yet
- Yealink IP Phones Configuration Guide For User Access Level V81 70Document220 pagesYealink IP Phones Configuration Guide For User Access Level V81 70Silvano F. RochaNo ratings yet