You might also like
- AP Statistics Chapter 3Document3 pagesAP Statistics Chapter 3jose mendoza0% (1)
- Correlation AnalysisDocument51 pagesCorrelation Analysisjjjjkjhkhjkhjkjk100% (1)
- Linear Regression General Subjective QuestionsDocument13 pagesLinear Regression General Subjective Questionssubodh raiNo ratings yet
- Business Report: Advanced Statistics ProjectDocument24 pagesBusiness Report: Advanced Statistics ProjectVarun Bhayana100% (5)
- MOBILE GAMING'S EFFECT ON STUDENTS' ACADEMICSDocument20 pagesMOBILE GAMING'S EFFECT ON STUDENTS' ACADEMICSZeru VillNo ratings yet
- Weekly Quiz 2 (AS) - PGPBABI.O.OCT19 Advanced Statistics - Great Learning PDFDocument5 pagesWeekly Quiz 2 (AS) - PGPBABI.O.OCT19 Advanced Statistics - Great Learning PDFAnkitNo ratings yet
- CorrelationDocument13 pagesCorrelationShishir SoodanaNo ratings yet
- Correlation and Chi-Square Test - LDR 280Document71 pagesCorrelation and Chi-Square Test - LDR 280RohanPuthalath100% (1)
- Project Report TaineesDocument96 pagesProject Report Taineesanon_26224424650% (2)
- Textbook AnalysisDocument12 pagesTextbook AnalysisAvinNo ratings yet
- Statistics Regression Final ProjectDocument12 pagesStatistics Regression Final ProjectHenry Pinolla100% (1)
- Divyanshi Project Report HRDocument86 pagesDivyanshi Project Report HRNageshwar singh0% (1)
- SPG in Public Elem. Sch. A Sequential Exploratory Approach ThBest ADocument45 pagesSPG in Public Elem. Sch. A Sequential Exploratory Approach ThBest ACamz MedinaNo ratings yet
- Iskak, Stats 2Document5 pagesIskak, Stats 2Iskak MohaiminNo ratings yet
- Correlation AnalysisDocument20 pagesCorrelation AnalysisVeerendra NathNo ratings yet
- CORRELATION ANALYSIS: MEASURING RELATIONSHIPSDocument8 pagesCORRELATION ANALYSIS: MEASURING RELATIONSHIPSGanesh BabuNo ratings yet
- Correlation Anad RegressionDocument13 pagesCorrelation Anad RegressionMY LIFE MY WORDSNo ratings yet
- Module 6 RM: Advanced Data Analysis TechniquesDocument23 pagesModule 6 RM: Advanced Data Analysis TechniquesEm JayNo ratings yet
- Unit 3-1Document12 pagesUnit 3-1Charankumar GuntukaNo ratings yet
- Regression AnlysisDocument6 pagesRegression AnlysisBals BalaNo ratings yet
- Report Statistical Technique in Decision Making (GROUP BPT) - Correlation & Linear Regression123Document20 pagesReport Statistical Technique in Decision Making (GROUP BPT) - Correlation & Linear Regression123AlieffiacNo ratings yet
- Africa Beza College: Chapter 2: Correlation Theory Pre-Test QuestionsDocument11 pagesAfrica Beza College: Chapter 2: Correlation Theory Pre-Test QuestionsAmanuel GenetNo ratings yet
- Regression and CorrelationDocument37 pagesRegression and Correlationmahnoorjamali853No ratings yet
- Correlation & Regression AnalysisDocument39 pagesCorrelation & Regression AnalysisAbhipreeth Mehra100% (1)
- Lesson1 - Simple Linier RegressionDocument40 pagesLesson1 - Simple Linier Regressioniin_sajaNo ratings yet
- Learn Bivariate Statistics MethodsDocument7 pagesLearn Bivariate Statistics MethodsPrince MpofuNo ratings yet
- Simple Linear Regression: Definition of TermsDocument13 pagesSimple Linear Regression: Definition of TermscesardakoNo ratings yet
- Correlation and Regression AnalysisDocument28 pagesCorrelation and Regression AnalysisManjula singhNo ratings yet
- Correlation and covariance explainedDocument11 pagesCorrelation and covariance explainedSrikirupa V MuralyNo ratings yet
- Correlation: (For M.B.A. I Semester)Document46 pagesCorrelation: (For M.B.A. I Semester)Arun Mishra100% (2)
- Modelling and ForecastDocument19 pagesModelling and ForecastCalvince OumaNo ratings yet
- CorrelationDocument19 pagesCorrelationShaifali KumawatNo ratings yet
- DSC 402Document14 pagesDSC 402Mukul PNo ratings yet
- Regression Analysis (Simple)Document8 pagesRegression Analysis (Simple)MUHAMMAD HASAN NAGRA100% (1)
- Stat ReviewDocument5 pagesStat ReviewHasan SamiNo ratings yet
- Correlation and RegressionDocument6 pagesCorrelation and RegressionMr. JahirNo ratings yet
- Primer StatsDocument4 pagesPrimer Statsveda20No ratings yet
- PLT 6133 Quantitative Correlation and RegressionDocument50 pagesPLT 6133 Quantitative Correlation and RegressionZeinab Goda100% (1)
- Bivariate Analysis: Research Methodology Digital Assignment IiiDocument6 pagesBivariate Analysis: Research Methodology Digital Assignment Iiiabin thomasNo ratings yet
- Linear RegressionDocument19 pagesLinear RegressionDipayan Bhattacharya 478No ratings yet
- Regression and CorrelationDocument13 pagesRegression and CorrelationMireille KirstenNo ratings yet
- Chapter 2-Simple Regression ModelDocument25 pagesChapter 2-Simple Regression ModelMuliana SamsiNo ratings yet
- Correlation and CausationDocument6 pagesCorrelation and CausationKzy ayanNo ratings yet
- SRT 605 - Topic (10) SLRDocument39 pagesSRT 605 - Topic (10) SLRpugNo ratings yet
- Correlation and Dependence: Navigation SearchDocument7 pagesCorrelation and Dependence: Navigation Searchanupam62789No ratings yet
- Correlation: HapterDocument16 pagesCorrelation: HapterRiaNo ratings yet
- © Ncert Not To Be Republished: CorrelationDocument16 pages© Ncert Not To Be Republished: Correlationhoney30389No ratings yet
- Biostatistics (Correlation and Regression)Document29 pagesBiostatistics (Correlation and Regression)Devyani Marathe100% (1)
- Reading 11: Correlation and Regression: S S Y X Cov RDocument24 pagesReading 11: Correlation and Regression: S S Y X Cov Rd ddNo ratings yet
- Econometrics LecturesDocument240 pagesEconometrics LecturesDevin-KonulRichmondNo ratings yet
- ADocument6 pagesAAngira KotalNo ratings yet
- CH 5 - Correlation and RegressionDocument9 pagesCH 5 - Correlation and RegressionhehehaswalNo ratings yet
- Module 7 Correlation & RegressionDocument56 pagesModule 7 Correlation & Regressionmanveen kaurNo ratings yet
- Correlation Analysis: Measuring Relationship Between VariablesDocument48 pagesCorrelation Analysis: Measuring Relationship Between VariablesPeter LoboNo ratings yet
- Subjective QuestionsDocument8 pagesSubjective QuestionsKeerthan kNo ratings yet
- Linear regression explainedDocument12 pagesLinear regression explainedPrabhat ShankarNo ratings yet
- ThesisDocument8 pagesThesisdereckg_2No ratings yet
- Correlation and Regression Analysis: Pembe Begul GUNERDocument30 pagesCorrelation and Regression Analysis: Pembe Begul GUNERMuhammad UmairNo ratings yet
- ASS#1-FINALS DoromalDocument8 pagesASS#1-FINALS DoromalAna DoromalNo ratings yet
- Regression and Correlation Analysis ExplainedDocument12 pagesRegression and Correlation Analysis ExplainedK Raghavendra Bhat100% (1)
- Correlation Analysis Notes-2Document5 pagesCorrelation Analysis Notes-2Kotresh KpNo ratings yet
- Regression and CorrelationDocument23 pagesRegression and CorrelationjyothimoncNo ratings yet
- Siness Ethics Week 7 Lec 1Document32 pagesSiness Ethics Week 7 Lec 1Syeda Raiha Raza GardeziNo ratings yet
- Business Ethics Week 5 Lec 1Document35 pagesBusiness Ethics Week 5 Lec 1Syeda Raiha Raza GardeziNo ratings yet
- Business Ethics Lecture on CSR and Case StudiesDocument12 pagesBusiness Ethics Lecture on CSR and Case StudiesSyeda Raiha Raza GardeziNo ratings yet
- Business Ethics Week 4 1Document37 pagesBusiness Ethics Week 4 1Syeda Raiha Raza GardeziNo ratings yet
- Project On Gourmet Final Edited 2Document18 pagesProject On Gourmet Final Edited 2Syeda Raiha Raza GardeziNo ratings yet
- Defining Sequencing VariablesDocument3 pagesDefining Sequencing VariablesSyeda Raiha Raza GardeziNo ratings yet
- Quiz 13Document23 pagesQuiz 13Syeda Raiha Raza GardeziNo ratings yet
- Final - Mamas WearDocument33 pagesFinal - Mamas WearSyeda Raiha Raza GardeziNo ratings yet
- Regression ExDocument13 pagesRegression ExSyeda Raiha Raza GardeziNo ratings yet
- Itm Presentation ON Ibm Spss (Question 4) : Presented By: Akansha GuptaDocument23 pagesItm Presentation ON Ibm Spss (Question 4) : Presented By: Akansha Guptaagga1111No ratings yet
- For Several Years Many Utilities Have Employed Regression AnalysDocument1 pageFor Several Years Many Utilities Have Employed Regression AnalysAmit PandeyNo ratings yet
- P L Lohitha 11-11-22 Data Mining Business ReportDocument47 pagesP L Lohitha 11-11-22 Data Mining Business ReportLohitha PakalapatiNo ratings yet
- Gujarati BookDocument3 pagesGujarati BookManuel Antonio Díaz FloresNo ratings yet
- The Influence of Test-Based Accountability Policies On Early Elementary Teachers: School Climate, Environmental Stress, and Teacher StressDocument13 pagesThe Influence of Test-Based Accountability Policies On Early Elementary Teachers: School Climate, Environmental Stress, and Teacher StressFernandoCedroNo ratings yet
- Marine Insurance OverviewDocument4 pagesMarine Insurance OverviewRoshan Jadhav67% (3)
- GC Getting Started Guide: 223-60220A Jul. 2010Document50 pagesGC Getting Started Guide: 223-60220A Jul. 2010Jeevan JalliNo ratings yet
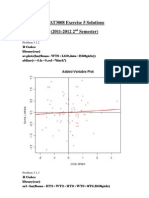
- STAT3008 Exercise 5 SolutionsDocument8 pagesSTAT3008 Exercise 5 SolutionsKewell ChongNo ratings yet
- Kitchin (2014) - Big Data, New Epistemologies and Paradigm ShiftsDocument12 pagesKitchin (2014) - Big Data, New Epistemologies and Paradigm ShiftsRB.ARGNo ratings yet
- MuzammalDocument4 pagesMuzammalUzair RazzaqNo ratings yet
- Unit 5 and 6 - Inferential Statistics and Regression AnalysisDocument68 pagesUnit 5 and 6 - Inferential Statistics and Regression AnalysisRajdeep SinghNo ratings yet
- The History, Evolution, and Technologies of Big Data with Use CasesDocument11 pagesThe History, Evolution, and Technologies of Big Data with Use CasesRam RNo ratings yet
- DWDM Lab Manual Using Weka-For MICDocument42 pagesDWDM Lab Manual Using Weka-For MICKrishnamohan YerrabilliNo ratings yet
- Data Mining For Business Analytics Concepts Techniques and Applications in Python EbookDocument62 pagesData Mining For Business Analytics Concepts Techniques and Applications in Python Ebookvicki.jackson553100% (42)
- How To Write A Quantitative Research Paper ExampleDocument8 pagesHow To Write A Quantitative Research Paper ExamplejsllxhbndNo ratings yet
- 8510Document9 pages8510Faisal SialNo ratings yet
- Correlation Matrix PDFDocument15 pagesCorrelation Matrix PDF123455690210No ratings yet
- Total Quality Management PracticesDocument30 pagesTotal Quality Management Practiceshesham_tm3658No ratings yet
- Correlation Research TechniquesDocument24 pagesCorrelation Research TechniquesFahad MushtaqNo ratings yet
- T TestDocument6 pagesT TestsamprtNo ratings yet
- Computerised Accounting Information Systems Lessons in State-Owned Enterprise in Developing Economies PDFDocument23 pagesComputerised Accounting Information Systems Lessons in State-Owned Enterprise in Developing Economies PDFjcgutz3No ratings yet
- العلاقة بين أساليب إدارة النزاع التنظيمي وفعالية فريق العمل في الإدارات المحلية دراسة حالة في المجالس الشعبية البلديةDocument21 pagesالعلاقة بين أساليب إدارة النزاع التنظيمي وفعالية فريق العمل في الإدارات المحلية دراسة حالة في المجالس الشعبية البلديةShawanda FlynnNo ratings yet
- Research Proposal FormatDocument2 pagesResearch Proposal FormatAnuja MishraNo ratings yet