You might also like
- Transportation HistoryDocument38 pagesTransportation HistoryAndrés AsturiasNo ratings yet
- 2016-01-21 Critical Issues in TransportationDocument19 pages2016-01-21 Critical Issues in TransportationAndrés AsturiasNo ratings yet
- Beautiful Arabic Chant of Naw Ruz Tablet - From YouTube by OfflibertyDocument1 pageBeautiful Arabic Chant of Naw Ruz Tablet - From YouTube by OfflibertyAndrés AsturiasNo ratings yet
- Grupo de Trabajo OPD - El Sistema Diagnóstico Psicodinámico Operacionalizado, Concepto, Fiabilidad, ValidezDocument21 pagesGrupo de Trabajo OPD - El Sistema Diagnóstico Psicodinámico Operacionalizado, Concepto, Fiabilidad, ValidezAndrés AsturiasNo ratings yet
- Solución de Simulacro 1 PDFDocument9 pagesSolución de Simulacro 1 PDFAndrés AsturiasNo ratings yet
- Lifetime Prevalence of Suicide Symptoms and Affective Disorders Among Men Reporting Same-Sex Sexual Partners: Result From NHANES IIIDocument6 pagesLifetime Prevalence of Suicide Symptoms and Affective Disorders Among Men Reporting Same-Sex Sexual Partners: Result From NHANES IIIAndrés AsturiasNo ratings yet
- Meehl, Paul - Clinical Vs Statistic PredictionDocument161 pagesMeehl, Paul - Clinical Vs Statistic Predictionadirago9664No ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- PreliminariesDocument9 pagesPreliminariesErikh James MestidioNo ratings yet
- ThesisDocument108 pagesThesisAmina K. KhalilNo ratings yet
- 01 Koshy Et Al CH 01 PDFDocument24 pages01 Koshy Et Al CH 01 PDFiamgodrajeshNo ratings yet
- Eviews Training For Iain Salatiga Talent Scouting Program: By: Anton BawonoDocument10 pagesEviews Training For Iain Salatiga Talent Scouting Program: By: Anton BawonoHamdan YuafiNo ratings yet
- Quantitative Methods Sessions 11 - 21Document41 pagesQuantitative Methods Sessions 11 - 21Kushal VNo ratings yet
- 3-Critical Appraisal For Secondary ResearchDocument2 pages3-Critical Appraisal For Secondary ResearchCharles Kyalo NyamaiNo ratings yet
- 07 Science Technology and SocietyDocument133 pages07 Science Technology and SocietyJoana Marie Castillo NavasquezNo ratings yet
- Consumer Behavior of Bottled WaterDocument55 pagesConsumer Behavior of Bottled Watersonia23singh247100% (1)
- Problem Set 5Document4 pagesProblem Set 5Luis CeballosNo ratings yet
- Extending The Useful Life of Elevators Through Appropriate Maintenance StrategiesDocument11 pagesExtending The Useful Life of Elevators Through Appropriate Maintenance StrategiesclarkyeahNo ratings yet
- AR (8) Model Is As Follows:: Financial Econometrics Tutorial Exercise 9 SolutionsDocument8 pagesAR (8) Model Is As Follows:: Financial Econometrics Tutorial Exercise 9 SolutionsParidhee ToshniwalNo ratings yet
- The Science of Self - About The BookDocument3 pagesThe Science of Self - About The BookSupreme-Understanding Supremedesignonline63% (8)
- 10 11648 J Ejcbs 20160206 17Document5 pages10 11648 J Ejcbs 20160206 17Mei SanjiwaniNo ratings yet
- Uji Multivariat Tingkat PemanfaatanDocument2 pagesUji Multivariat Tingkat PemanfaatanJulina Br SembiringNo ratings yet
- Appendix EDocument9 pagesAppendix Ejames3h3parkNo ratings yet
- Research Report On Solid Waste Management PDFDocument87 pagesResearch Report On Solid Waste Management PDFAnonymous OP6R1ZS100% (1)
- Nomkhosi Nkomo St10122214 Iner7411 Take Home TestDocument3 pagesNomkhosi Nkomo St10122214 Iner7411 Take Home TestMacowzaNo ratings yet
- Hypotheses and AssumptionsDocument2 pagesHypotheses and AssumptionsJulieta CarcoleNo ratings yet
- Learning Reinforcement 6 J.villanueva Gmath 2567Document4 pagesLearning Reinforcement 6 J.villanueva Gmath 2567Sittie Ainna Acmed UnteNo ratings yet
- Hypothesis Test Example For Population MeanDocument9 pagesHypothesis Test Example For Population MeanLola SaadiNo ratings yet
- Business Research 1Document98 pagesBusiness Research 1vansha_mehra1990No ratings yet
- The Problem and Its Background: University of LuzonDocument14 pagesThe Problem and Its Background: University of LuzonNhicoleChoiNo ratings yet
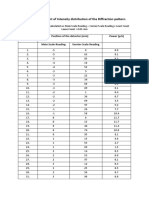
- (A) Measurement of Intensity Distribution of The Diffraction PatternDocument2 pages(A) Measurement of Intensity Distribution of The Diffraction PatternBhupesh YadavNo ratings yet
- Books on marketing modelsDocument4 pagesBooks on marketing modelsElisa BarbuNo ratings yet
- CROMATOGRAPHYDocument4 pagesCROMATOGRAPHYNerlyn Santa FlorezNo ratings yet
- Rye, Owen - Pottery Technology Principles and ReconstructionDocument154 pagesRye, Owen - Pottery Technology Principles and Reconstructiongtametal86% (14)
- Qualitative Versus Quantitative Research: Key Points in A Classic DebateDocument2 pagesQualitative Versus Quantitative Research: Key Points in A Classic DebateGyle Contawe GarciaNo ratings yet
- Keyword For API 580 PDFDocument9 pagesKeyword For API 580 PDFRaymundo ACNo ratings yet
- Hypothesis Testing ANOVADocument61 pagesHypothesis Testing ANOVAyatendra1singhNo ratings yet
- Pool of Issue Prompts EtsDocument29 pagesPool of Issue Prompts Etsapi-327987013No ratings yet