You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Use of All Basic Controls@Document119 pagesUse of All Basic Controls@lalitha100% (1)
- Manual ZB2L3-Medidor Capacidad BateriaDocument2 pagesManual ZB2L3-Medidor Capacidad BateriaPetérNo ratings yet
- 1757 Um007 - en P PDFDocument160 pages1757 Um007 - en P PDFfitasmounirNo ratings yet
- Claroty Web API User Guide Rev06Document21 pagesClaroty Web API User Guide Rev06Julio VeraNo ratings yet
- Lab. Act#3-1Document5 pagesLab. Act#3-1Zedrik MojicaNo ratings yet
- Canon MF8580Cdw-MF8570Cdw-MF8550Cd-MF8540Cdn-MF8530Cdn PC PDFDocument68 pagesCanon MF8580Cdw-MF8570Cdw-MF8550Cd-MF8540Cdn-MF8530Cdn PC PDFEduard PopescuNo ratings yet
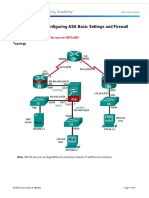
- Chapter 9 Lab A: Configuring ASA Basic Settings and Firewall Using CLIDocument13 pagesChapter 9 Lab A: Configuring ASA Basic Settings and Firewall Using CLIHAMDI GDHAMINo ratings yet
- Improving Code Quality For Java Projects PDFDocument1 pageImproving Code Quality For Java Projects PDFYaegar WainNo ratings yet
- BIOS Handbook D25xx: DescriptionDocument74 pagesBIOS Handbook D25xx: DescriptionIoana BulgariuNo ratings yet
- Module 1 PPTDocument93 pagesModule 1 PPTmahanth gowdaNo ratings yet
- The Fork System CallDocument10 pagesThe Fork System Callpriya1788ekNo ratings yet
- FreeNAS Installation and Configuration GuideDocument20 pagesFreeNAS Installation and Configuration GuidesergiutNo ratings yet
- EBS R12 Error SoutionsDocument5 pagesEBS R12 Error SoutionsDaniel CraigNo ratings yet
- 18csc202j Oodp Ct1 Question-OldDocument8 pages18csc202j Oodp Ct1 Question-OldBergin PremNo ratings yet
- STEP-by-STEP Guide To 1553 Design: Utmc Application NoteDocument28 pagesSTEP-by-STEP Guide To 1553 Design: Utmc Application Notejaysingh12No ratings yet
- 6.1.3.10 Lab - Configure A Wireless NetworkDocument6 pages6.1.3.10 Lab - Configure A Wireless Networkgheoputra55No ratings yet
- Excel Programming Tutorial 1: Macros and FunctionsDocument13 pagesExcel Programming Tutorial 1: Macros and FunctionsSk AkashNo ratings yet
- Computer Abbreviations - Ritambhara PandeyDocument4 pagesComputer Abbreviations - Ritambhara PandeymanuNo ratings yet
- OPENEDGE Managing PerformanceDocument11 pagesOPENEDGE Managing PerformancesudarshanNo ratings yet
- Debugging With GDB: Sakeeb SabakkaDocument60 pagesDebugging With GDB: Sakeeb SabakkasakeebsNo ratings yet
- TB96853 CS68 Upgrade Procedures 20376Document2 pagesTB96853 CS68 Upgrade Procedures 20376ORHAN GÜNEŞNo ratings yet
- DS Lab Record PDFDocument146 pagesDS Lab Record PDFJishnuNo ratings yet
- Log file documenting service startup and connection attemptsDocument2,351 pagesLog file documenting service startup and connection attemptsSebastián HernándezNo ratings yet
- PM810 Modbus Application NoteDocument10 pagesPM810 Modbus Application Notebilal761No ratings yet
- 06 GIT Workflow PDFDocument1 page06 GIT Workflow PDFBruno BriccolaNo ratings yet
- Service Manual HP 602Document91 pagesService Manual HP 602Danny Gonzalez del ValleNo ratings yet
- Clarion CX Basics FundamentalsDocument15 pagesClarion CX Basics FundamentalsRajesh VenkatNo ratings yet
- Yearly Plan Ict Form 1Document15 pagesYearly Plan Ict Form 1Zack JBNo ratings yet
- NLCA Test Admin GuidelinesDocument8 pagesNLCA Test Admin GuidelinesSharon LumingkitNo ratings yet