You might also like
- Intervalos de Confianza y de Predicción. Regresion MultipleDocument23 pagesIntervalos de Confianza y de Predicción. Regresion MultipleXisco ArjonaNo ratings yet
- Presentación Power Point - Distribuciones Continuas - AplicacionesDocument32 pagesPresentación Power Point - Distribuciones Continuas - AplicacionesjocoblomushyNo ratings yet
- Ejercicios Determinantes SelectividadDocument10 pagesEjercicios Determinantes SelectividadJUAN DAVID CORTÉS OSSANo ratings yet
- S1 - Apunte 3 - EconomnetríaDocument14 pagesS1 - Apunte 3 - EconomnetríacRISTIANNo ratings yet
- Tema 5Document33 pagesTema 5MauricioNo ratings yet
- Melendez-Roberto-Gm71-Varianza de Estimacion, El Error de Estimacion y Su DistribuccionDocument16 pagesMelendez-Roberto-Gm71-Varianza de Estimacion, El Error de Estimacion y Su DistribuccionRoberto Melendez CastilloNo ratings yet
- Intervalos de Confianza para Diferencias de MediosDocument16 pagesIntervalos de Confianza para Diferencias de MediosMary Chuy Gutierrez LeónNo ratings yet
- MiFee - CL - Inferencia Modelo MultipleDocument18 pagesMiFee - CL - Inferencia Modelo MultiplepaquebotttNo ratings yet
- Clase #06 - Regresion Con Dos VariablesDocument30 pagesClase #06 - Regresion Con Dos VariablesFREDERIC REY YACILA LUNANo ratings yet
- 5 Estimacion de Parametros Estadisticos Modo de CompatibilidadDocument21 pages5 Estimacion de Parametros Estadisticos Modo de Compatibilidadlucas1600No ratings yet
- Econometría Cap 4 y 5Document24 pagesEconometría Cap 4 y 5KAREN DANIELA FAJARDO MATALLANANo ratings yet
- Regresión Lineal Simple GuíaDocument64 pagesRegresión Lineal Simple Guíaerikbambino100% (1)
- Estimación estadística: Tipos de estimación, intervalos de confianza y fuentesDocument10 pagesEstimación estadística: Tipos de estimación, intervalos de confianza y fuentesPABLO ROMERONo ratings yet
- Econometria - IDocument16 pagesEconometria - IAlejandro S Figueroa AriasNo ratings yet
- Clasesestadistica I Est de Par y Test MediaDocument21 pagesClasesestadistica I Est de Par y Test MediaFran IgarzabalNo ratings yet
- Ejemplos Hipotesis-Chi-Cuadrado PDFDocument14 pagesEjemplos Hipotesis-Chi-Cuadrado PDFfernalva2014No ratings yet
- Semana 11Document52 pagesSemana 11Anthony SaldanaNo ratings yet
- Clase Estimacion Puntual IntervalosDocument19 pagesClase Estimacion Puntual IntervalosGilbert Alexander SalasNo ratings yet
- Apuntes EconometríaDocument16 pagesApuntes EconometríaMarc PalauNo ratings yet
- Regresión Lineal SimpleDocument36 pagesRegresión Lineal SimpleHans Hidalgo AltaNo ratings yet
- Est Imac IonDocument8 pagesEst Imac IonYessenia ContrerasNo ratings yet
- 1 - Regresión Lineal SimpleDocument18 pages1 - Regresión Lineal SimpleJessica Chaparrita de DiegoNo ratings yet
- Estadistica ExpoDocument18 pagesEstadistica ExpoIgnacio Lama RosasNo ratings yet
- Ayudantía 3 [Enunciado]Document8 pagesAyudantía 3 [Enunciado]Rodrigo VillenaNo ratings yet
- 2020 Estimación de Parametros y Pruebas de HipotesisDocument51 pages2020 Estimación de Parametros y Pruebas de HipotesisJavi OlmNo ratings yet
- Obtener Archivo RecursoDocument48 pagesObtener Archivo RecursoJorge Luis Ruiz ToroNo ratings yet
- Dos PoblacionesDocument23 pagesDos PoblacionesRoxy VasNo ratings yet
- Preguntas de Regresion LinealDocument10 pagesPreguntas de Regresion LinealVale_IGEBNo ratings yet
- Clase 6 Supuestos Clásicos Del Modelo de RegresiónDocument22 pagesClase 6 Supuestos Clásicos Del Modelo de RegresiónCosetteYinelaValenzuelaRiosNo ratings yet
- Estadística y ProbabilidadDocument11 pagesEstadística y ProbabilidadCatherine CastillaNo ratings yet
- Taller de ADocument8 pagesTaller de AMaythe LissethNo ratings yet
- Guia Biosta2Document7 pagesGuia Biosta2alexNo ratings yet
- Estimacion - Puntual - e - Intervalo 2Document28 pagesEstimacion - Puntual - e - Intervalo 2Xavier CedeñoNo ratings yet
- Clase 4 - Estimación Puntual e Intervalos de Confianza para La Media y ProporciónDocument21 pagesClase 4 - Estimación Puntual e Intervalos de Confianza para La Media y ProporciónCatalina Muñoz0% (1)
- Ova Semama 7 UiiDocument19 pagesOva Semama 7 Uiijoseph gonzalesNo ratings yet
- Estadistica y ProbabilidadesDocument17 pagesEstadistica y ProbabilidadesAmanda Riley100% (1)
- Tema III - Estimacion Puntual y Por IntervalosDocument35 pagesTema III - Estimacion Puntual y Por IntervalosMady CifuentesNo ratings yet
- Intervalos de ConfianzaDocument10 pagesIntervalos de ConfianzaSebastian Bedoya LopezNo ratings yet
- 04.00 Estmacion EstadisticaDocument52 pages04.00 Estmacion EstadisticaFroylan MHNo ratings yet
- Econoemtria ExpooDocument5 pagesEconoemtria ExpooBrus Condori CcoraNo ratings yet
- Tema 9Document19 pagesTema 9jorgeluis ramos maqueraNo ratings yet
- Regresión Lineal: Inferencia, Predicción y Significancia EstadísticaDocument25 pagesRegresión Lineal: Inferencia, Predicción y Significancia EstadísticaCarlos Vargas RodríguezNo ratings yet
- Clase 7 Estimación 1 Pobla-10-05-22-AVMDocument52 pagesClase 7 Estimación 1 Pobla-10-05-22-AVMMati FiedlerNo ratings yet
- Estimación EstadísticaDocument56 pagesEstimación EstadísticaLuis Angel Martinez Rojas100% (1)
- Regresion Lineal SimpleDocument14 pagesRegresion Lineal SimplefacenunaNo ratings yet
- Estimación Puntual e IntercalicaDocument32 pagesEstimación Puntual e IntercalicaRicardo Julk' VeraNo ratings yet
- Inferencia Estadística y Prueba Chi-cuadradoDocument13 pagesInferencia Estadística y Prueba Chi-cuadradoElias Jose Albis PachecoNo ratings yet
- Regresion Lineal SimpleDocument21 pagesRegresion Lineal SimpleSasha Valeria Siguenza RoblesNo ratings yet
- Inferencia EstadisticaDocument16 pagesInferencia EstadisticaMarco Antonio RiveroNo ratings yet
- Estimación Estadística: Intervalos de Confianza para Parámetros PoblacionalesDocument16 pagesEstimación Estadística: Intervalos de Confianza para Parámetros PoblacionalesleoastorsNo ratings yet
- Unidad IV EstadisticaDocument37 pagesUnidad IV EstadisticaNayarid OcañaNo ratings yet
- Prueba de Hipotesis Muestra Pequeña y PareadaDocument9 pagesPrueba de Hipotesis Muestra Pequeña y PareadaKEVIN ALEX CCANA TORRESNo ratings yet
- Semana #02 - Tratamiento Estadístico de Los DatosDocument36 pagesSemana #02 - Tratamiento Estadístico de Los DatosChristian DiazNo ratings yet
- Conceptos Basicos de EstadisticaDocument82 pagesConceptos Basicos de EstadisticaGiovanni GarciaNo ratings yet
- Estimación de parámetros poblacionalesDocument23 pagesEstimación de parámetros poblacionalesRoque RendonNo ratings yet
- Intervalos de ConfianzaDocument30 pagesIntervalos de ConfianzaErick Tc33% (3)
- Inferencia EstadísticaDocument51 pagesInferencia Estadísticablado1No ratings yet
- Estimacion Por IntervalosDocument20 pagesEstimacion Por IntervalosBrian Rugerio SanchezNo ratings yet
- Actividad Integración Requisitos LiderSGIDocument1 pageActividad Integración Requisitos LiderSGIAlejandro Sebastián Piñeiro CaroNo ratings yet
- Actividad Integración Requisitos LiderSGIDocument1 pageActividad Integración Requisitos LiderSGIAlejandro Sebastián Piñeiro CaroNo ratings yet
- Pauta Guia de Procesos Industriales N°2 (Final)Document3 pagesPauta Guia de Procesos Industriales N°2 (Final)Alejandro Sebastián Piñeiro CaroNo ratings yet
- Guia 1 Procesos Industriales2Document7 pagesGuia 1 Procesos Industriales2Alejandro Sebastián Piñeiro CaroNo ratings yet
- Construcción PYMESDocument91 pagesConstrucción PYMESAlejandro Sebastián Piñeiro CaroNo ratings yet
- Optimización Módulo 2 OptimizaciónDocument104 pagesOptimización Módulo 2 OptimizaciónDanny Paz VidalNo ratings yet
- Introduccion A Los Procesos IndustrialesDocument67 pagesIntroduccion A Los Procesos IndustrialesAlejandro Sebastián Piñeiro Caro100% (1)
- Hoja Resp ALiderInt IQNetDocument19 pagesHoja Resp ALiderInt IQNetAlejandro Sebastián Piñeiro CaroNo ratings yet
- Formulario LISTA VERIFICACION SGI-04 Rev 01Document2 pagesFormulario LISTA VERIFICACION SGI-04 Rev 01Alejandro Sebastián Piñeiro CaroNo ratings yet
- Manual Inacap Procesos Industriales (LOPI01) VFDocument88 pagesManual Inacap Procesos Industriales (LOPI01) VFAlejandro Sebastián Piñeiro CaroNo ratings yet
- Guia de Procesos Industriales N°2Document2 pagesGuia de Procesos Industriales N°2Alejandro Sebastián Piñeiro CaroNo ratings yet
- Guia Diagrama de ProcesoDocument7 pagesGuia Diagrama de ProcesoAlejandro Sebastián Piñeiro CaroNo ratings yet
- Optimización - Módulo 1 - Las Funciones de Varias VariablesDocument92 pagesOptimización - Módulo 1 - Las Funciones de Varias VariablesAlejandro Sebastián Piñeiro CaroNo ratings yet
- Estrategia Logística - Módulo 2 - Logística InternacionalDocument68 pagesEstrategia Logística - Módulo 2 - Logística InternacionalAlejandro Sebastián Piñeiro CaroNo ratings yet
- Optimización - Módulo 6 - Análisis de SensibilidadDocument38 pagesOptimización - Módulo 6 - Análisis de SensibilidadAlejandro Sebastián Piñeiro CaroNo ratings yet
- Optimización - Módulo 4 - El Algoritmo SimplexDocument58 pagesOptimización - Módulo 4 - El Algoritmo SimplexAlejandro Sebastián Piñeiro CaroNo ratings yet
- Inventario-Introducción-ClasificacionesDocument123 pagesInventario-Introducción-ClasificacionesAlejandro Sebastián Piñeiro CaroNo ratings yet
- Optimización - Módulo 3 - Introducción A La Investigación OperativaDocument52 pagesOptimización - Módulo 3 - Introducción A La Investigación OperativaAlejandro Sebastián Piñeiro CaroNo ratings yet
- Permiso traslado interregionalDocument2 pagesPermiso traslado interregionalAlejandro Sebastián Piñeiro CaroNo ratings yet
- Permiso traslado interregionalDocument2 pagesPermiso traslado interregionalAlejandro Sebastián Piñeiro CaroNo ratings yet
- Blog Logistica CurseraDocument1 pageBlog Logistica CurseraAlejandro Sebastián Piñeiro CaroNo ratings yet
- Permiso traslado interregionalDocument2 pagesPermiso traslado interregionalAlejandro Sebastián Piñeiro CaroNo ratings yet
- Guía RSCDocument6 pagesGuía RSCholaNo ratings yet
- Permiso Temporal: Carabineros de ChileDocument1 pagePermiso Temporal: Carabineros de ChileAlejandro Sebastián Piñeiro CaroNo ratings yet
- Que Es Ser ConsultorDocument9 pagesQue Es Ser ConsultorAlejandro Sebastián Piñeiro CaroNo ratings yet
- Documentos Minimos Sistema de Gestion MaquehuaDocument5 pagesDocumentos Minimos Sistema de Gestion MaquehuaAlejandro Sebastián Piñeiro CaroNo ratings yet
- Como Hacer PresupuestoDocument1 pageComo Hacer PresupuestoAlejandro Sebastián Piñeiro CaroNo ratings yet
- No quemas residuos forestalesDocument4 pagesNo quemas residuos forestalesAlejandro Sebastián Piñeiro CaroNo ratings yet
- Trabajo Final Responsabilidad Social CorporativaDocument5 pagesTrabajo Final Responsabilidad Social CorporativaAnonymous TGUj4mSx44% (9)
- Documentos Minimos Sistema de Gestion MaquehuaDocument5 pagesDocumentos Minimos Sistema de Gestion MaquehuaAlejandro Sebastián Piñeiro CaroNo ratings yet
- Conceptos Sobre AnaulidadesDocument4 pagesConceptos Sobre AnaulidadesIndira Carolina100% (1)
- Ceros RaicesDocument50 pagesCeros RaicesHoracio UsecheNo ratings yet
- Ejercicios de Vectores y Fuerzas D PDFDocument4 pagesEjercicios de Vectores y Fuerzas D PDFLucho H. G.100% (1)
- S14.s2-Longitud de ArcoDocument13 pagesS14.s2-Longitud de ArcoVíctor MarchánNo ratings yet
- PITÁGORASDocument4 pagesPITÁGORASCarlos Rafael Martinez ArroyoNo ratings yet
- OBIOLSDocument6 pagesOBIOLSMatias LeitezNo ratings yet
- Inf 354Document4 pagesInf 354Jose CordovaNo ratings yet
- Ensayo I Introducción Al Control de BioprocesosDocument25 pagesEnsayo I Introducción Al Control de BioprocesosEdna MartinezNo ratings yet
- Bachiller - Esquema Representación de FuncionesDocument1 pageBachiller - Esquema Representación de FuncionesLorena Del Coz RodríguezNo ratings yet
- Pseudocódigo que pide edad y sexo para verificar si puede votarDocument6 pagesPseudocódigo que pide edad y sexo para verificar si puede votarAbigarey ReyesNo ratings yet
- Baez 2007 PrincipiosDocument20 pagesBaez 2007 PrincipiosVladimir PatiñoNo ratings yet
- Cir01prac Alg UNIDocument3 pagesCir01prac Alg UNIjeapoolNo ratings yet
- Modulo I Secundaria Trig 5° 2020Document6 pagesModulo I Secundaria Trig 5° 2020ROSA MELVA VERA RUEDANo ratings yet
- Preguntas Dinamozadoras Unidad 2 Introduccion A La AdministracionDocument8 pagesPreguntas Dinamozadoras Unidad 2 Introduccion A La AdministracionLuis Fernando Gomez ValcarcelNo ratings yet
- Segundo Examen Teorico Probabilidades y Estadistica-2021-2Document2 pagesSegundo Examen Teorico Probabilidades y Estadistica-2021-2GEORGE IVANOK MUNOZ CASTILLONo ratings yet
- Matematica Geometris Recero Basico PDFDocument1 pageMatematica Geometris Recero Basico PDFCarolximena Rodríguez VallejosNo ratings yet
- Lógica ProposicionalDocument20 pagesLógica ProposicionalDiana NarváezNo ratings yet
- RP-MAT4-K02 - Ficha 2Document11 pagesRP-MAT4-K02 - Ficha 2LucioErnestoRamosPeña50% (4)
- La Ingenieria en Su Evolucion Desde La AntiguedadDocument43 pagesLa Ingenieria en Su Evolucion Desde La AntiguedadWendy Acuña CaceresNo ratings yet
- Reglas de La FracciónDocument8 pagesReglas de La FracciónViviana VargasNo ratings yet
- Trabajo Métodos de EntonaciónDocument22 pagesTrabajo Métodos de EntonaciónCarlos QuintanillaNo ratings yet
- Guía # 1 Geometría 6°Document4 pagesGuía # 1 Geometría 6°geiler jacob medrano martinesNo ratings yet
- Magnitudes y Medidas (Volumen)Document16 pagesMagnitudes y Medidas (Volumen)Randy Hu PereraNo ratings yet
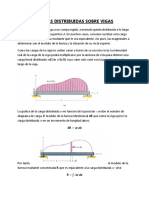
- Cargas Distribuidas Sobre VigasDocument7 pagesCargas Distribuidas Sobre VigasAarón E. Díaz50% (2)
- Muestra EXAMENES SAN MARCOS 2010-2024-II OkDocument3 pagesMuestra EXAMENES SAN MARCOS 2010-2024-II OkPedro Garcia AndesNo ratings yet
- Lógica Síntesis DidácticaDocument12 pagesLógica Síntesis DidácticaJuly Marcela Ramirez LuisNo ratings yet
- Examen final grado 5 áreas, perímetros, volúmenes y operacionesDocument3 pagesExamen final grado 5 áreas, perímetros, volúmenes y operacionescarmen perezNo ratings yet
- Aplicaciones de La Transforma - Laplace - 2020 - IDocument10 pagesAplicaciones de La Transforma - Laplace - 2020 - IJUAN DIEGO DUEÑAS FLORESNo ratings yet
- EXELDocument81 pagesEXELAngelica MoscosoNo ratings yet






















![Ayudantía 3 [Enunciado]](https://imgv2-2-f.scribdassets.com/img/document/721917979/149x198/b504fefa3f/1712789639?v=1)