You might also like
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Demand Forecasting of A Perishable Dairy Drink: An ARIMA ApproachDocument15 pagesDemand Forecasting of A Perishable Dairy Drink: An ARIMA ApproachLewis TorresNo ratings yet
- Linking Early Detection/treatment of Parkinson's Disease Using Deep Learning TechniquesDocument16 pagesLinking Early Detection/treatment of Parkinson's Disease Using Deep Learning TechniquesLewis TorresNo ratings yet
- Class Imbalance Handling Techniques Used in Depression Prediction and DetectionDocument17 pagesClass Imbalance Handling Techniques Used in Depression Prediction and DetectionLewis TorresNo ratings yet
- International Journal of Data Mining & Knowledge Management Process (IJDKP)Document2 pagesInternational Journal of Data Mining & Knowledge Management Process (IJDKP)Lewis TorresNo ratings yet
- The Stock Market Volatility Between China and Asean Countries Association Studies Based On Complex NetworksDocument16 pagesThe Stock Market Volatility Between China and Asean Countries Association Studies Based On Complex NetworksLewis TorresNo ratings yet
- International Journal of Data Mining & Knowledge Management Process (IJDKP)Document2 pagesInternational Journal of Data Mining & Knowledge Management Process (IJDKP)Lewis TorresNo ratings yet
- Identifying Similar Web Pages Based On Automated and User Preference Value Using Scoring MethodsDocument13 pagesIdentifying Similar Web Pages Based On Automated and User Preference Value Using Scoring MethodsLewis TorresNo ratings yet
- International Journal of Data Mining & Knowledge Management Process (IJDKP)Document2 pagesInternational Journal of Data Mining & Knowledge Management Process (IJDKP)Lewis TorresNo ratings yet
- International Journal of Data Mining & Knowledge Management Process (IJDKP)Document2 pagesInternational Journal of Data Mining & Knowledge Management Process (IJDKP)Lewis TorresNo ratings yet
- Distortion Based Algorithms For Privacy Preserving Frequent Item Set MiningDocument13 pagesDistortion Based Algorithms For Privacy Preserving Frequent Item Set MiningLewis TorresNo ratings yet
- IJDKPDocument1 pageIJDKPLewis TorresNo ratings yet
- 2nd International Conference On Big Data, IoT and Machine Learning (BIOM 2022)Document2 pages2nd International Conference On Big Data, IoT and Machine Learning (BIOM 2022)Lewis TorresNo ratings yet
- International Journal of Data Mining & Knowledge Management Process (IJDKP)Document2 pagesInternational Journal of Data Mining & Knowledge Management Process (IJDKP)Lewis TorresNo ratings yet
- International Journal of Data Mining & Knowledge Management Process (IJDKP)Document2 pagesInternational Journal of Data Mining & Knowledge Management Process (IJDKP)Lewis TorresNo ratings yet
- Data Integration in A Hadoop-Based Data Lake: A Bioinformatics CaseDocument24 pagesData Integration in A Hadoop-Based Data Lake: A Bioinformatics CaseLewis TorresNo ratings yet
- An Experimental Evaluation of Similarity-Based and Embedding-Based Link Prediction Methods On GraphsDocument18 pagesAn Experimental Evaluation of Similarity-Based and Embedding-Based Link Prediction Methods On GraphsLewis TorresNo ratings yet
- Enabling Supply Chains by Adopting Blockchain TechnologyDocument18 pagesEnabling Supply Chains by Adopting Blockchain TechnologyLewis TorresNo ratings yet
- IJDKPDocument1 pageIJDKPLewis TorresNo ratings yet
- Referring Expressions With Rational Speech Act Framework: A Probabilistic ApproachDocument12 pagesReferring Expressions With Rational Speech Act Framework: A Probabilistic ApproachLewis TorresNo ratings yet
- Referring Expressions With Rational Speech Act Framework: A Probabilistic ApproachDocument12 pagesReferring Expressions With Rational Speech Act Framework: A Probabilistic ApproachLewis TorresNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Code ArduinoDocument3 pagesCode ArduinoSuaib DanishNo ratings yet
- Ladd CC 1964 - Stress-Strain Behavior of Saturated Clay and Basic Strength Principles PDFDocument125 pagesLadd CC 1964 - Stress-Strain Behavior of Saturated Clay and Basic Strength Principles PDFSaraswati NoorNo ratings yet
- Fairchild Ll4007 PDFDocument1 pageFairchild Ll4007 PDFKathyNo ratings yet
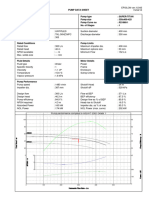
- TKL Pump - Data - SheetDocument1 pageTKL Pump - Data - Sheetธนาชัย เต็งจิรธนาภาNo ratings yet
- 2021 Manual of Clinical Phonetics Siêu HayDocument564 pages2021 Manual of Clinical Phonetics Siêu HaydaohailongNo ratings yet
- Lesson Plan Letter MDocument3 pagesLesson Plan Letter Mapi-307404579No ratings yet
- Social Construction of DisasterDocument385 pagesSocial Construction of DisasterPratik Kumar BandyopadhyayNo ratings yet
- Department of Education: Performance Monitoring and Coaching Form SY 2021-2022Document3 pagesDepartment of Education: Performance Monitoring and Coaching Form SY 2021-2022Sheena Movilla96% (24)
- 20110715122354-B SC - M SC - H S - Mathematics PDFDocument75 pages20110715122354-B SC - M SC - H S - Mathematics PDFn0% (1)
- Examples V4.1 PDFDocument39 pagesExamples V4.1 PDFgerNo ratings yet
- JLG 860SJ Parts - Global - English PDFDocument294 pagesJLG 860SJ Parts - Global - English PDFfater esmandarNo ratings yet
- Dynasylan BSM 40%Document3 pagesDynasylan BSM 40%Francois-No ratings yet
- KTU BTech EEE 2016scheme S3S4KTUSyllabusDocument41 pagesKTU BTech EEE 2016scheme S3S4KTUSyllabusleksremeshNo ratings yet
- Artificial Intelligence (AI) Part - 2, Lecture - 12: Unification in First-Order LogicDocument18 pagesArtificial Intelligence (AI) Part - 2, Lecture - 12: Unification in First-Order LogicMazharul RahiNo ratings yet
- SH Dream Team - PDDocument6 pagesSH Dream Team - PDSimran SinghNo ratings yet
- Yolo v4Document42 pagesYolo v4Deepak SaxenaNo ratings yet
- Curl (Mathematics) - Wikipedia, The Free EncyclopediaDocument13 pagesCurl (Mathematics) - Wikipedia, The Free EncyclopediasoumyanitcNo ratings yet
- Flutter WidgetsDocument43 pagesFlutter WidgetsSangakkara WarriorsNo ratings yet
- Discovery LearningDocument14 pagesDiscovery LearningYuki JudaiNo ratings yet
- DYNAMIC MODELLING AND CONTROL OF A 3-DOF PLANAR PARALLEL ROBOTIC (XYthetaZ MOTION) PLATFORMDocument10 pagesDYNAMIC MODELLING AND CONTROL OF A 3-DOF PLANAR PARALLEL ROBOTIC (XYthetaZ MOTION) PLATFORMVinoth VenkatesanNo ratings yet
- The Health and Sanitary Status of Mamanwa IndigenoDocument9 pagesThe Health and Sanitary Status of Mamanwa IndigenoRush VeltranNo ratings yet
- 21st Bomber Command Tactical Mission Report 64, 65, OcrDocument57 pages21st Bomber Command Tactical Mission Report 64, 65, OcrJapanAirRaidsNo ratings yet
- Lesson 1. Introduction To Metaheuristics and General ConceptsDocument37 pagesLesson 1. Introduction To Metaheuristics and General ConceptshamoNo ratings yet
- 152-Article Text-3978-4-10-20190311Document7 pages152-Article Text-3978-4-10-20190311charlesNo ratings yet
- Ensci 200 Fall 2021 Writting RubricDocument1 pageEnsci 200 Fall 2021 Writting RubricAsheNo ratings yet
- About The ProjectDocument5 pagesAbout The Projectanand kumarNo ratings yet
- Practices Venn DiagramDocument2 pagesPractices Venn DiagramNathanNo ratings yet
- Goulds Pumps: WE SeriesDocument4 pagesGoulds Pumps: WE SeriesJorge ManobandaNo ratings yet
- Nnscore 2.0: A Neural-Network Receptor Ligand Scoring FunctionDocument7 pagesNnscore 2.0: A Neural-Network Receptor Ligand Scoring FunctionAdrián RodríguezNo ratings yet
- Sr. No. Reference - Id Name NQT - Reference - Id Email - Id Highest Institute Name Qualification SpecializationDocument6 pagesSr. No. Reference - Id Name NQT - Reference - Id Email - Id Highest Institute Name Qualification SpecializationKinzang NamgayNo ratings yet