You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Automated Telephone Billing SystemDocument13 pagesAutomated Telephone Billing SystemSuganya PeriasamyNo ratings yet
- Automated Telephone Billing SystemDocument13 pagesAutomated Telephone Billing SystemSuganya PeriasamyNo ratings yet
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Actual4Test: Actual4test - Actual Test Exam Dumps-Pass For IT ExamsDocument7 pagesActual4Test: Actual4test - Actual Test Exam Dumps-Pass For IT ExamsHakanNo ratings yet
- Java AppletsDocument40 pagesJava AppletsSuganya PeriasamyNo ratings yet
- 21.handling Userdefined ExceptionsDocument3 pages21.handling Userdefined ExceptionsSuganya PeriasamyNo ratings yet
- 125.security and Privacy-Enhancing Multicloud Architectures - August 2013Document13 pages125.security and Privacy-Enhancing Multicloud Architectures - August 2013Suganya PeriasamyNo ratings yet
- 125.security and Privacy-Enhancing Multicloud Architectures - August 2013Document13 pages125.security and Privacy-Enhancing Multicloud Architectures - August 2013Suganya PeriasamyNo ratings yet
- 2.class and Object Design in C++.Document4 pages2.class and Object Design in C++.Suganya PeriasamyNo ratings yet
- Ieee Paper On Image Processing Based On HUMAN MACHINE INTERFACEDocument6 pagesIeee Paper On Image Processing Based On HUMAN MACHINE INTERFACESuganya PeriasamyNo ratings yet
- Design and Implementation of Intrusion Response System For Reltional DatabasesDocument2 pagesDesign and Implementation of Intrusion Response System For Reltional DatabasesSuganya PeriasamyNo ratings yet
- Java Swing GUI Toolkit for Eclipse IDEDocument20 pagesJava Swing GUI Toolkit for Eclipse IDERahul ChauhanNo ratings yet
- Achieving Minimum Storage Cost For Intermediate Datasets in The CloudDocument21 pagesAchieving Minimum Storage Cost For Intermediate Datasets in The CloudSuganya PeriasamyNo ratings yet
- A Load Balancing Model Based On Cloud Partitioning For The Public Cloud PDFDocument6 pagesA Load Balancing Model Based On Cloud Partitioning For The Public Cloud PDFRamesh KumarNo ratings yet
- Time Aware Personalized Service Forecasting System For Cloud Services PDFDocument8 pagesTime Aware Personalized Service Forecasting System For Cloud Services PDFSuganya PeriasamyNo ratings yet
- Swing Components and The Containment HierarchyDocument3 pagesSwing Components and The Containment HierarchySuganya PeriasamyNo ratings yet
- Swing Components and The Containment HierarchyDocument3 pagesSwing Components and The Containment HierarchySuganya PeriasamyNo ratings yet
- Privacy Preserving Intermediate Datasets in The CloudDocument83 pagesPrivacy Preserving Intermediate Datasets in The CloudSuganya PeriasamyNo ratings yet
- 3D Password Tecchnology Using Cloud Computing With Its Applications and AdvantagesDocument9 pages3D Password Tecchnology Using Cloud Computing With Its Applications and AdvantagesSuganya PeriasamyNo ratings yet
- Interfaces - Multiple Inheritance.Document4 pagesInterfaces - Multiple Inheritance.Suganya PeriasamyNo ratings yet
- On GPS System With Its Applications and TechnologiesDocument11 pagesOn GPS System With Its Applications and TechnologiesSuganya PeriasamyNo ratings yet
- Open Source Technology in Open Source Software Ieee PaperDocument10 pagesOpen Source Technology in Open Source Software Ieee PaperSuganya PeriasamyNo ratings yet
- 54.secured Role Based Access Control in An OrganizationDocument10 pages54.secured Role Based Access Control in An OrganizationSuganya PeriasamyNo ratings yet
- A Local Optimization Based Strategy For Cost-Effective Datasets Storage of Scientific Applications in The CloudDocument22 pagesA Local Optimization Based Strategy For Cost-Effective Datasets Storage of Scientific Applications in The CloudSuganya PeriasamyNo ratings yet
- Wireless Network Using Manet Technology With Its Applications and Also Mobile ComputingDocument11 pagesWireless Network Using Manet Technology With Its Applications and Also Mobile ComputingSuganya PeriasamyNo ratings yet
- Wi-Max Technology OverviewDocument10 pagesWi-Max Technology OverviewSuganya PeriasamyNo ratings yet
- IEEE Paper On Image Processing Based On The Title Blue Eyes TechnologyDocument12 pagesIEEE Paper On Image Processing Based On The Title Blue Eyes TechnologySuganya PeriasamyNo ratings yet
- Wireless Network Using Manet Technology With Its Applications and Also Mobile ComputingDocument11 pagesWireless Network Using Manet Technology With Its Applications and Also Mobile ComputingSuganya PeriasamyNo ratings yet
- Wireless Technologies and Its Functions, Features and Applications in Mobile ComputingDocument10 pagesWireless Technologies and Its Functions, Features and Applications in Mobile ComputingSuganya PeriasamyNo ratings yet
- 4g Technology With The Wireless Mobile Adhoc NetworkDocument16 pages4g Technology With The Wireless Mobile Adhoc NetworkSuganya PeriasamyNo ratings yet
- Environmental Engineering SyllabusDocument27 pagesEnvironmental Engineering SyllabusSuganya PeriasamyNo ratings yet
- BCA 3rd Practical FileDocument47 pagesBCA 3rd Practical FilePratham Kochhar100% (1)
- ANDROID APPLICATION DEVELOPMENT TRAINING-Course Content PDFDocument4 pagesANDROID APPLICATION DEVELOPMENT TRAINING-Course Content PDFBoopathy PandiNo ratings yet
- Data Access ObjectsDocument8 pagesData Access ObjectsIndrani SenNo ratings yet
- Modbus Driver Guide: M Mo Od DB Bu Uss D Drriiv Ve Err G Gu Uiid de eDocument102 pagesModbus Driver Guide: M Mo Od DB Bu Uss D Drriiv Ve Err G Gu Uiid de eAristide DorsonNo ratings yet
- Movi NandDocument2 pagesMovi NandNo ratings yet
- System On Chip Design and Modelling: University of Cambridge Computer Laboratory Lecture NotesDocument144 pagesSystem On Chip Design and Modelling: University of Cambridge Computer Laboratory Lecture Notesgkk001No ratings yet
- Extended Access-List Example On Cisco RouterDocument1 pageExtended Access-List Example On Cisco RouterSamuel HOUNGBEMENo ratings yet
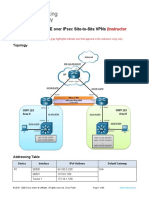
- 16.1.4 Lab - Implement GRE Over IPsec Site-To-Site VPNs - ILMDocument33 pages16.1.4 Lab - Implement GRE Over IPsec Site-To-Site VPNs - ILMAndrei Petru PârvNo ratings yet
- A Note On The Use of These PPT Slides:: Computer Networking: A Top Down ApproachDocument33 pagesA Note On The Use of These PPT Slides:: Computer Networking: A Top Down Approachyo_maxx1988No ratings yet
- VB Code to Populate FlexGrid from RecordsetDocument9 pagesVB Code to Populate FlexGrid from RecordsetMohd Gulfam100% (1)
- 10 TX Inputs AnalyzedDocument5 pages10 TX Inputs AnalyzedRoman SargsyanNo ratings yet
- Classwork of Lab 2: 1. Create A New User, Naming sv2Document18 pagesClasswork of Lab 2: 1. Create A New User, Naming sv2Phú VinhNo ratings yet
- Unit 2 - Lec 2 - Network Layer - AttacksDocument68 pagesUnit 2 - Lec 2 - Network Layer - AttacksD CREATIONNo ratings yet
- Privacy Preserving Multi Keyword Ranked Search Over Encrypted Cloud DataDocument4 pagesPrivacy Preserving Multi Keyword Ranked Search Over Encrypted Cloud DataLOGIC SYSTEMSNo ratings yet
- Chapter - 6: Linux File System StructureDocument38 pagesChapter - 6: Linux File System Structureak.microsoft20056613No ratings yet
- SMF 2-0-4 ChangelogDocument261 pagesSMF 2-0-4 ChangelogKakasi HatakeNo ratings yet
- Cisco Slow Drain PDFDocument61 pagesCisco Slow Drain PDFAbhishekNo ratings yet
- Accounting Information Systems 13th Edition Romney Test BankDocument25 pagesAccounting Information Systems 13th Edition Romney Test Bankrobingomezwqfbdcaksn100% (32)
- User Guide For KPI ReporterDocument61 pagesUser Guide For KPI ReporterAnh DaoNo ratings yet
- Preface: Howto Set Up Certificate Based Vpns With Check Point Appliances - R80.X EditionDocument35 pagesPreface: Howto Set Up Certificate Based Vpns With Check Point Appliances - R80.X Edition000-924680No ratings yet
- Ssqar Solid State Quick Access Recorder P/N: 200-E20-XXXX Installation and Configuration Manual ICM-05Document46 pagesSsqar Solid State Quick Access Recorder P/N: 200-E20-XXXX Installation and Configuration Manual ICM-05Bruno GonçalvesNo ratings yet
- Data warehouse architecture and components overviewDocument56 pagesData warehouse architecture and components overviewNoor ThamerNo ratings yet
- SAP HANA Interview QuestionsDocument17 pagesSAP HANA Interview QuestionsShivani DeshmukhNo ratings yet
- Chapter 3Document40 pagesChapter 3Kj BanalNo ratings yet
- Sorting Algorithms ExplainedDocument17 pagesSorting Algorithms Explainedغانم العتيبيNo ratings yet
- Hashcode 2020 Online Qualification RoundDocument8 pagesHashcode 2020 Online Qualification RoundPilot PirxNo ratings yet
- UPSC EPFO EO 50 Important Computer QuestionsDocument13 pagesUPSC EPFO EO 50 Important Computer QuestionsdeepthiNo ratings yet
- Data Structure (DS) Solved Mcqs Set 4Document7 pagesData Structure (DS) Solved Mcqs Set 4sfarithaNo ratings yet
- What Do You Already Know?: True TrueDocument3 pagesWhat Do You Already Know?: True TrueJeffrey MangaoangNo ratings yet