You might also like
- 2018-19 APSC 201 Course OutlineDocument9 pages2018-19 APSC 201 Course Outlinenaismith1No ratings yet
- Oup Case StudyDocument4 pagesOup Case StudyAnonymous raI6uYNo ratings yet
- Cement Industry Overview in BangladeshDocument19 pagesCement Industry Overview in BangladeshSANIUL ISLAM91% (44)
- Weekly Home Learning Plans for Empowerment TechnologiesDocument3 pagesWeekly Home Learning Plans for Empowerment TechnologiesCharlon Mamacos100% (9)
- AppleDocument11 pagesAppleSayyid Muhammad AliNo ratings yet
- How Unilever Connects with Consumers through Extensive ResearchDocument5 pagesHow Unilever Connects with Consumers through Extensive ResearchAlexandraNo ratings yet
- Essay Technology Killing CreativityDocument3 pagesEssay Technology Killing CreativityAnzu Honda0% (2)
- Digital Media Assigment 2Document10 pagesDigital Media Assigment 2Divya JoyceNo ratings yet
- Brand Trust and Brand Loyalty An Empirical Study in Indonesia Consumers PDFDocument11 pagesBrand Trust and Brand Loyalty An Empirical Study in Indonesia Consumers PDFMoein AbasinNo ratings yet
- Tally ForteDocument100 pagesTally ForteVijay SoniNo ratings yet
- Chapter 9 - Using Secondary DataDocument11 pagesChapter 9 - Using Secondary DataArly TolentinoNo ratings yet
- Students During Covid: A Correlation StudyDocument20 pagesStudents During Covid: A Correlation StudyVance BonjocNo ratings yet
- Pestle and Banking IndustryDocument16 pagesPestle and Banking IndustryRegina Leona DeLos SantosNo ratings yet
- Unit-I: Human Resource Management (H R M) Definition 1 - IntegrationDocument49 pagesUnit-I: Human Resource Management (H R M) Definition 1 - IntegrationPremendra SahuNo ratings yet
- The Value of Social Media For SmallDocument22 pagesThe Value of Social Media For SmallAnonymous PXNHxgckNo ratings yet
- Principles of Effective CommunicationDocument1 pagePrinciples of Effective Communicationapi-309947771No ratings yet
- Sources of Secondary DataDocument13 pagesSources of Secondary DataSanoob Sidiq0% (1)
- Writing A Dissertation: An OverviewDocument67 pagesWriting A Dissertation: An OverviewInformationTechnology ConsultingGroupNo ratings yet
- Effectiveness of Online Teaching in Covid Lockdown Dental Students ViewpointDocument3 pagesEffectiveness of Online Teaching in Covid Lockdown Dental Students ViewpointEditor IJTSRDNo ratings yet
- Stewardship Theory Stakeholder Theory and ConvergenceDocument5 pagesStewardship Theory Stakeholder Theory and ConvergenceMuhammad MéhråjNo ratings yet
- Developing Human Resource Management EffectivenessDocument11 pagesDeveloping Human Resource Management EffectivenessKennedy Gitonga ArithiNo ratings yet
- Diversity Management - New Organizational ParadigmDocument16 pagesDiversity Management - New Organizational ParadigmLing YiNo ratings yet
- Performance AppraisalDocument4 pagesPerformance AppraisalAshish GuptaNo ratings yet
- Fashion and MarketingDocument9 pagesFashion and MarketingAnonymous IStk6QNo ratings yet
- Assignment CSR #2Document3 pagesAssignment CSR #2Gerald F. SalasNo ratings yet
- Obstacles To Education of Children A Study of Underprivileged Sections of SocietyDocument6 pagesObstacles To Education of Children A Study of Underprivileged Sections of SocietyQysar Afzal SofiNo ratings yet
- A Study of Consumers Behaviour Towards Purchasing Decision of CarDocument14 pagesA Study of Consumers Behaviour Towards Purchasing Decision of CararcherselevatorsNo ratings yet
- Education Industry in IndiaDocument7 pagesEducation Industry in IndiaNandita Asthana SankerNo ratings yet
- A Student Satisfaction ModelDocument15 pagesA Student Satisfaction ModelVesna RodicNo ratings yet
- Attrition and Retention in Higher Education Institution: A Conjoint Analysis of Consumer Behavior in Higher EducationDocument12 pagesAttrition and Retention in Higher Education Institution: A Conjoint Analysis of Consumer Behavior in Higher Educationapjeas100% (1)
- Demand For Edn & Its DeterminantsDocument11 pagesDemand For Edn & Its DeterminantsSUNIJA BEEGUM. NNo ratings yet
- FG - 115845 - Implement Sales and Marketing StrategiesDocument24 pagesFG - 115845 - Implement Sales and Marketing StrategiesChristian MakandeNo ratings yet
- Significance of Educational TechnologyDocument2 pagesSignificance of Educational TechnologyShanti Laika TrazoNo ratings yet
- Beyond Teacher Leadership TeachersDocument12 pagesBeyond Teacher Leadership Teacherspopok999No ratings yet
- Behavioral Learning TheoriesDocument19 pagesBehavioral Learning TheoriesNathirshaRahimNo ratings yet
- Perceptual MappingDocument12 pagesPerceptual Mappingranu nugrahaNo ratings yet
- Gamification Themes Analysis EeDocument15 pagesGamification Themes Analysis EeM Faraz Naim100% (1)
- Impact of Social Media On Emotional Health of The Senior Highschool JAM (AutoRecovered)Document21 pagesImpact of Social Media On Emotional Health of The Senior Highschool JAM (AutoRecovered)Jasmin CaballeroNo ratings yet
- Importance of Culture in AdvertisingDocument11 pagesImportance of Culture in AdvertisingNatasha AlikiNo ratings yet
- Advertising Management - Meaning and Important Concepts PDFDocument3 pagesAdvertising Management - Meaning and Important Concepts PDFjrenceNo ratings yet
- Curriculum ExplanationDocument2 pagesCurriculum ExplanationJoshua CoxNo ratings yet
- STEM Education in Malaysia: Policy, Trajectories and InitiativesDocument12 pagesSTEM Education in Malaysia: Policy, Trajectories and InitiativesFariza ZahariNo ratings yet
- Purchase Intention of College Students Through Social MediaDocument7 pagesPurchase Intention of College Students Through Social MediaInternational Journal of Advanced Scientific Research and DevelopmentNo ratings yet
- Importance of Marketing Mix in Higher Education InstitutionsDocument13 pagesImportance of Marketing Mix in Higher Education InstitutionsGuna SekarNo ratings yet
- The Ideal Work EnvironmentDocument3 pagesThe Ideal Work Environmentselina_kollsNo ratings yet
- Final Paper in Research Methods - Melissa ReyesDocument17 pagesFinal Paper in Research Methods - Melissa ReyesAlyana ContyNo ratings yet
- Theory and Social Research - Neuman - Chapter2Document24 pagesTheory and Social Research - Neuman - Chapter2Madie Chua0% (1)
- CH 14Document16 pagesCH 14Huzaifa Bin SaeedNo ratings yet
- BRMDocument21 pagesBRMKhadar100% (1)
- What Is The Best Response Scale For Survey and Questionnaire Design Review of Different Lengths of Rating Scale Attitude Scale Likert ScaleDocument12 pagesWhat Is The Best Response Scale For Survey and Questionnaire Design Review of Different Lengths of Rating Scale Attitude Scale Likert ScaleHamed TaherdoostNo ratings yet
- Principles For Ethical Research Involving Humans Ethical Professional Practice in Impact Assessment Part IDocument12 pagesPrinciples For Ethical Research Involving Humans Ethical Professional Practice in Impact Assessment Part IApoorva MaheshNo ratings yet
- Bridging The Gap From Student Teacher To Classroom TeacherDocument11 pagesBridging The Gap From Student Teacher To Classroom TeacherGlobal Research and Development ServicesNo ratings yet
- Research Course Outline For Resarch Methodology Fall 2011 (MBA)Document3 pagesResearch Course Outline For Resarch Methodology Fall 2011 (MBA)mudassarramzanNo ratings yet
- Understanding The Consumer Behaviour Towards Organic Food: A Study of The Bangladesh MarketDocument16 pagesUnderstanding The Consumer Behaviour Towards Organic Food: A Study of The Bangladesh MarketIOSRjournalNo ratings yet
- Human Resource ManagementDocument22 pagesHuman Resource ManagementKEDARANATHA PADHYNo ratings yet
- MBA 2nd-Research-Paper-on-Marketing-EthicsDocument15 pagesMBA 2nd-Research-Paper-on-Marketing-EthicsYadav Manish KumarNo ratings yet
- ECE Workforce MsiaDocument28 pagesECE Workforce MsiachsleongNo ratings yet
- Influence of Type of Courses Offered On Enrolment To Technical Vocational Education and Training in Trans Nzoia County, KenyaDocument9 pagesInfluence of Type of Courses Offered On Enrolment To Technical Vocational Education and Training in Trans Nzoia County, KenyaEditor IJTSRDNo ratings yet
- Tema 1: History of Qualitative ResearchDocument36 pagesTema 1: History of Qualitative ResearchCamiluTripleSNo ratings yet
- On The Ethics of Psychometric Instruments Used in Leadership Development ProgrammesDocument17 pagesOn The Ethics of Psychometric Instruments Used in Leadership Development ProgrammesHeru WiryantoNo ratings yet
- CH 01Document49 pagesCH 01m m c channelNo ratings yet
- Marketing of Bank Servicesing of Bank ServicesDocument14 pagesMarketing of Bank Servicesing of Bank ServicesSANIUL ISLAMNo ratings yet
- Continuous Probability DistributionDocument7 pagesContinuous Probability DistributionSANIUL ISLAMNo ratings yet
- ProbabilityDocument10 pagesProbabilitySANIUL ISLAM100% (3)
- Quartiles Deciles and PercentilesDocument6 pagesQuartiles Deciles and PercentilesSANIUL ISLAM82% (22)
- Dispersion or VariabilityDocument6 pagesDispersion or VariabilitySANIUL ISLAMNo ratings yet
- Time SeriesDocument11 pagesTime SeriesSANIUL ISLAMNo ratings yet
- Hourly Earnings in March, 1994 Index 100 Hourly Earnings in 1980Document11 pagesHourly Earnings in March, 1994 Index 100 Hourly Earnings in 1980SANIUL ISLAMNo ratings yet
- Correlation and RegressionDocument11 pagesCorrelation and RegressionSANIUL ISLAMNo ratings yet
- Measures of Central TendencyDocument18 pagesMeasures of Central TendencySANIUL ISLAM100% (1)
- Probability DistributionDocument7 pagesProbability DistributionSANIUL ISLAMNo ratings yet
- ProbabilityDocument10 pagesProbabilitySANIUL ISLAM100% (3)
- SamplingDocument9 pagesSamplingSANIUL ISLAMNo ratings yet
- Assignment No: 01: Quarterly Data-Quarter Quantity PriceDocument5 pagesAssignment No: 01: Quarterly Data-Quarter Quantity PriceSANIUL ISLAMNo ratings yet
- Global Warming and BangladeshDocument9 pagesGlobal Warming and BangladeshSANIUL ISLAMNo ratings yet
- LHCDocument21 pagesLHCSANIUL ISLAMNo ratings yet
- Solar CellDocument7 pagesSolar CellSANIUL ISLAMNo ratings yet
- Electricity Distribution, Operation & Maintenance of Sub-StationDocument27 pagesElectricity Distribution, Operation & Maintenance of Sub-StationSANIUL ISLAM67% (3)
- EWU IUMO 2009 - Math OlympiadDocument24 pagesEWU IUMO 2009 - Math OlympiadSANIUL ISLAM100% (1)
- Wind Energy in BangladeshDocument6 pagesWind Energy in BangladeshSANIUL ISLAMNo ratings yet
- Final AssignmentEEE20 (Numerical Analysis)Document8 pagesFinal AssignmentEEE20 (Numerical Analysis)SANIUL ISLAMNo ratings yet
- EWU Assignment Final (4bit Adder, Eprom, Eeprom, Flip Flop)Document10 pagesEWU Assignment Final (4bit Adder, Eprom, Eeprom, Flip Flop)SANIUL ISLAMNo ratings yet
- FormulaDocument4 pagesFormulaSANIUL ISLAM50% (2)
- Constitutive ParameterDocument1 pageConstitutive ParameterSANIUL ISLAMNo ratings yet
- t370hw02 VC AuoDocument27 pagest370hw02 VC AuoNachiket KshirsagarNo ratings yet
- Blockchain Systems and Their Potential Impact On Business ProcessesDocument19 pagesBlockchain Systems and Their Potential Impact On Business ProcessesHussain MoneyNo ratings yet
- Applied Physics B.Tech I Year, I-Semester, I-Mid ExamDocument3 pagesApplied Physics B.Tech I Year, I-Semester, I-Mid Examsumaiyah syedNo ratings yet
- Chapter 1 PPT CondensedDocument5 pagesChapter 1 PPT CondensedRaymond GuillartesNo ratings yet
- Logistics Market:: Global Industry Trends, Share, Size, Growth, Opportunity and Forecast 2019-2024Document55 pagesLogistics Market:: Global Industry Trends, Share, Size, Growth, Opportunity and Forecast 2019-2024Trần Thị Hồng NgọcNo ratings yet
- Pod PDFDocument30 pagesPod PDFnurten devaNo ratings yet
- UAV-based Multispectral Remote Sensing For Precision Agriculture: A T Comparison Between Different CamerasDocument13 pagesUAV-based Multispectral Remote Sensing For Precision Agriculture: A T Comparison Between Different CamerasSantiago BedoyaNo ratings yet
- AOPEN DEV8430 Preliminary DatasheetDocument2 pagesAOPEN DEV8430 Preliminary DatasheetMarisa García CulpiánNo ratings yet
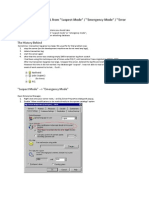
- How To Recover MSSQL From Suspect Mode Emergency Mode Error 1813Document3 pagesHow To Recover MSSQL From Suspect Mode Emergency Mode Error 1813Scott NeubauerNo ratings yet
- Power Point Chapter - 15Document6 pagesPower Point Chapter - 15Shahwaiz Bin Imran BajwaNo ratings yet
- Vinculum's Supply Chain PracticeDocument26 pagesVinculum's Supply Chain PracticeVinculumGroup100% (1)
- Professional Testers Please Step ForwardDocument3 pagesProfessional Testers Please Step ForwardPuneet MaheshwariNo ratings yet
- Q4M2 Giving Technical and Operational Def.2.0Document60 pagesQ4M2 Giving Technical and Operational Def.2.0Shadow Gaming YTNo ratings yet
- ABB Price Book 714Document1 pageABB Price Book 714EliasNo ratings yet
- Low Cost PCO Billing Meter PDFDocument1 pageLow Cost PCO Billing Meter PDFJuber ShaikhNo ratings yet
- Forouzan MCQ in Data and Signals PDFDocument13 pagesForouzan MCQ in Data and Signals PDFPat Dela OstiaNo ratings yet
- Berjuta Rasanya Tere Liye PDFDocument5 pagesBerjuta Rasanya Tere Liye PDFaulia nurmalitasari0% (1)
- Ipv4 Address Classes PDFDocument2 pagesIpv4 Address Classes PDFAmol IngleNo ratings yet
- 15 Reasons To Use Redis As An Application Cache: Itamar HaberDocument9 pages15 Reasons To Use Redis As An Application Cache: Itamar Haberdyy dygysd dsygyNo ratings yet
- ETC012 - Device Driver Development To Accessing SDMMC Card Using SPI On LPC2148Document3 pagesETC012 - Device Driver Development To Accessing SDMMC Card Using SPI On LPC2148Vinay FelixNo ratings yet
- Forward Error Correction (FEC)Document6 pagesForward Error Correction (FEC)gamer08No ratings yet
- SSS Format DescriptionDocument5 pagesSSS Format Descriptionmartinos22No ratings yet
- Ds-7104Ni-Sl/W: Embedded Mini Wifi NVRDocument1 pageDs-7104Ni-Sl/W: Embedded Mini Wifi NVRLuis GutierrezNo ratings yet
- VFACE TOUCH AND BASIC QUICK INSTALLATION GUIDEDocument2 pagesVFACE TOUCH AND BASIC QUICK INSTALLATION GUIDEPunith RajNo ratings yet
- Contoh CVDocument2 pagesContoh CVBetty Pasaribu100% (1)
- Investigating A Theoretical Framework For E-Learning Technology AcceptanceDocument13 pagesInvestigating A Theoretical Framework For E-Learning Technology AcceptanceNguyễn Như ÝNo ratings yet
- Fertilizer Information System For Banana PlantatioDocument5 pagesFertilizer Information System For Banana PlantatioHazem EmadNo ratings yet
- Data Science Batch 8 PDFDocument19 pagesData Science Batch 8 PDFAhmad FajarNo ratings yet
- STRATOS MGM 160 Biogas Cogeneration UnitDocument11 pagesSTRATOS MGM 160 Biogas Cogeneration UnitGeorge PircalabuNo ratings yet