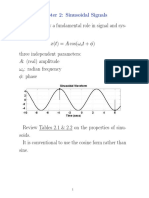
You might also like
- Exercise 8.9 (Johnson Jonaris Gadelkarim) : X Xy YDocument6 pagesExercise 8.9 (Johnson Jonaris Gadelkarim) : X Xy YHuu NguyenNo ratings yet
- Informationtheory Ii: Model Answers To Exercise 4 of March 24, 2010Document4 pagesInformationtheory Ii: Model Answers To Exercise 4 of March 24, 2010GauravSainiNo ratings yet
- Saharon Shelah - Very Weak Zero One Law For Random Graphs With Order and Random Binary FunctionsDocument11 pagesSaharon Shelah - Very Weak Zero One Law For Random Graphs With Order and Random Binary FunctionsJgfm2No ratings yet
- ECE 771 Lecture 10 - The Gaussian ChannelDocument9 pagesECE 771 Lecture 10 - The Gaussian ChannelbabbouzzaNo ratings yet
- EE 121 - Introduction To Digital Communications Final Exam Practice ProblemsDocument4 pagesEE 121 - Introduction To Digital Communications Final Exam Practice ProblemsNowshin AlamNo ratings yet
- G13 1949 PUTNAM Web SolutionDocument8 pagesG13 1949 PUTNAM Web SolutionmokonoaniNo ratings yet
- Assignment - 4: Applications of Derivatives: X 2! X 2 X 4! X 3! X 2! X 4! X 3! X 5! X 2 1 Cos X X /2 Sin C CDocument5 pagesAssignment - 4: Applications of Derivatives: X 2! X 2 X 4! X 3! X 2! X 4! X 3! X 5! X 2 1 Cos X X /2 Sin C CGanesh KumarNo ratings yet
- 1 General Solution To Wave Equation: One Dimensional WavesDocument35 pages1 General Solution To Wave Equation: One Dimensional WaveswenceslaoflorezNo ratings yet
- ProblemsDocument62 pagesProblemserad_5No ratings yet
- Itc0809 Homework7Document5 pagesItc0809 Homework7Refka MansouryNo ratings yet
- Maths - IJAMSS - Common Fixed Point Theorem V.K. GuptaDocument8 pagesMaths - IJAMSS - Common Fixed Point Theorem V.K. Guptaiaset123No ratings yet
- Final SolDocument7 pagesFinal SolIslam El BakouryNo ratings yet
- 2002 - Paper IIDocument6 pages2002 - Paper IIhmphryNo ratings yet
- Ee132b Hw2 SolDocument5 pagesEe132b Hw2 SolAhmed HassanNo ratings yet
- Theorems of Sylvester and SchurDocument19 pagesTheorems of Sylvester and Schuranon020202No ratings yet
- The South African Mathematical Olympiad Third Round 2012 Senior Division (Grades 10 To 12) Time: 4 Hours (No Calculating Devices Are Allowed)Document6 pagesThe South African Mathematical Olympiad Third Round 2012 Senior Division (Grades 10 To 12) Time: 4 Hours (No Calculating Devices Are Allowed)Carlos TorresNo ratings yet
- 5 Channel Capacity and CodingDocument29 pages5 Channel Capacity and CodingOlumayowa IdowuNo ratings yet
- Solutions To Problems Related To Information TheoryDocument4 pagesSolutions To Problems Related To Information TheoryRohit BhadauriaNo ratings yet
- Assignment 3 SolDocument6 pagesAssignment 3 SolChuah Chian YeongNo ratings yet
- OU Open University SM358 2009 Exam SolutionsDocument23 pagesOU Open University SM358 2009 Exam Solutionssam smithNo ratings yet
- H2-Optimal Control - Lec8Document83 pagesH2-Optimal Control - Lec8stara123warNo ratings yet
- 2003 - Paper IIIDocument6 pages2003 - Paper IIIhmphryNo ratings yet
- Ps12 Solutions 1Document7 pagesPs12 Solutions 1trekniwNo ratings yet
- Linear AlgebraDocument6 pagesLinear AlgebraPeterNo ratings yet
- Part A: Chennai Mathematical InstituteDocument2 pagesPart A: Chennai Mathematical InstituteVikas RajpootNo ratings yet
- Digital Communications HomeworkDocument7 pagesDigital Communications HomeworkDavid SiegfriedNo ratings yet
- MRRW Bound and Isoperimetric Problems: 6.1 PreliminariesDocument8 pagesMRRW Bound and Isoperimetric Problems: 6.1 PreliminariesAshoka VanjareNo ratings yet
- Matdid 325610Document14 pagesMatdid 325610Hoàng Khánh HưngNo ratings yet
- Pmath940-W2 Copy 7Document11 pagesPmath940-W2 Copy 7Annie LiNo ratings yet
- Solution Set 3Document11 pagesSolution Set 3HaseebAhmadNo ratings yet
- Topics in Analytic Number Theory, Lent 2013. Lecture 20: Conclusion of Bombieri's TheoremDocument5 pagesTopics in Analytic Number Theory, Lent 2013. Lecture 20: Conclusion of Bombieri's TheoremEric ParkerNo ratings yet
- Computing The (CDF) F (X) P (X X) of The Distribution Maps A Number in The Domain To A Probability Between 0 and 1 and Then Inverting That FunctionDocument9 pagesComputing The (CDF) F (X) P (X X) of The Distribution Maps A Number in The Domain To A Probability Between 0 and 1 and Then Inverting That FunctionipsitaNo ratings yet
- CH 02Document30 pagesCH 02KavunNo ratings yet
- Real Analysis HWDocument8 pagesReal Analysis HWJimmy BroomfieldNo ratings yet
- 1 IEOR 4700: Notes On Brownian Motion: 1.1 Normal DistributionDocument11 pages1 IEOR 4700: Notes On Brownian Motion: 1.1 Normal DistributionshrutigarodiaNo ratings yet
- 2000 - Paper IIDocument6 pages2000 - Paper IIhmphryNo ratings yet
- MIT18 100CF12 Prob Set 4Document5 pagesMIT18 100CF12 Prob Set 4Muhammad TaufanNo ratings yet
- The Average Smarandache FunctionDocument9 pagesThe Average Smarandache FunctionMia AmaliaNo ratings yet
- Solutions To The 61st William Lowell Putnam Mathematical Competition Saturday, December 2, 2000Document3 pagesSolutions To The 61st William Lowell Putnam Mathematical Competition Saturday, December 2, 2000Benny PrasetyaNo ratings yet
- Chapter 2Document25 pagesChapter 2McNemarNo ratings yet
- Urysohnlemma 150115Document3 pagesUrysohnlemma 150115Ongaro Steven OmbokNo ratings yet
- Analysis TestDocument5 pagesAnalysis TestMiliyon TilahunNo ratings yet
- Linear Algebra Cheat SheetDocument2 pagesLinear Algebra Cheat SheettraponegroNo ratings yet
- APM 504 - PS4 SolutionsDocument5 pagesAPM 504 - PS4 SolutionsSyahilla AzizNo ratings yet
- ESM3a: Advanced Linear Algebra and Stochastic ProcessesDocument12 pagesESM3a: Advanced Linear Algebra and Stochastic ProcessesvenisulavNo ratings yet
- a, a, …, a, α, …, α a α a α a …+α a a, a, …, a a α a α a …+α a α …=αDocument7 pagesa, a, …, a, α, …, α a α a α a …+α a a, a, …, a a α a α a …+α a α …=αKimondo KingNo ratings yet
- T9SOLDocument6 pagesT9SOLAjoy SharmaNo ratings yet
- Hw3sol PDFDocument8 pagesHw3sol PDFShy PeachDNo ratings yet
- Equadiff Vienne 2007Document6 pagesEquadiff Vienne 2007hhedfiNo ratings yet
- Problem Set 7: Y 2 X Y X ∞ −∞ X dω 2πDocument4 pagesProblem Set 7: Y 2 X Y X ∞ −∞ X dω 2πanthalyaNo ratings yet
- 2000 2 PDFDocument4 pages2000 2 PDFMuhammad Al KahfiNo ratings yet
- Eecs Spring: 224B: Fundamentals of Wireless Communications 2006Document4 pagesEecs Spring: 224B: Fundamentals of Wireless Communications 2006MohamedSalahNo ratings yet
- 2002 - Paper IIIDocument6 pages2002 - Paper IIIhmphryNo ratings yet
- Week11 AnswersDocument15 pagesWeek11 AnswersAarav ParinNo ratings yet
- SolutionsDocument77 pagesSolutionsramon314dNo ratings yet
- 263 HomeworkDocument153 pages263 HomeworkHimanshu Saikia JNo ratings yet
- Open Set ProofDocument2 pagesOpen Set Proofsagetbob43No ratings yet
- Corporate Tax Avoidance and Performance: Evidence From China's Listed CompaniesDocument23 pagesCorporate Tax Avoidance and Performance: Evidence From China's Listed CompaniesReynardo GosalNo ratings yet
- Chap 6 Hydrograph 1415-IDocument122 pagesChap 6 Hydrograph 1415-IkakmanNo ratings yet
- The Interaction Between Any Two Charges Is Completely Unaffected by The Presence of OthersDocument9 pagesThe Interaction Between Any Two Charges Is Completely Unaffected by The Presence of Otherssuma mumuNo ratings yet
- Concrete Mix Design Is MethodDocument29 pagesConcrete Mix Design Is MethodChirag TanavalaNo ratings yet
- Relational ModelDocument4 pagesRelational ModelPrateek GoyalNo ratings yet
- Handover Parameter 2GDocument17 pagesHandover Parameter 2GSon EricNo ratings yet
- Maths PDFDocument60 pagesMaths PDFLoh Chee WeiNo ratings yet
- DAA PPT DAA PPT by Dr. Preeti BailkeDocument21 pagesDAA PPT DAA PPT by Dr. Preeti BailkeKkNo ratings yet
- Assignment PDFDocument2 pagesAssignment PDFMoazzam HussainNo ratings yet
- Aea Cookbook Econometrics Module 1Document117 pagesAea Cookbook Econometrics Module 1shadayenpNo ratings yet
- Drafting 101Document4 pagesDrafting 101Airene Abear PascualNo ratings yet
- Marasigan, Christian M. CE-2202 Hydrology Problem Set - Chapter 4 Streamflow MeasurementDocument10 pagesMarasigan, Christian M. CE-2202 Hydrology Problem Set - Chapter 4 Streamflow Measurementchrstnmrsgn100% (1)
- Pressure Vessels Lectures 84Document1 pagePressure Vessels Lectures 84Adeel NizamiNo ratings yet
- Math 6 DLP 1 - Giving Meaning of Exponent and Base Giving The Value of Numbers Involving Exponent PDFDocument9 pagesMath 6 DLP 1 - Giving Meaning of Exponent and Base Giving The Value of Numbers Involving Exponent PDFZyreen Joy ServanesNo ratings yet
- LESSON PLAN Coordinate GeometryDocument11 pagesLESSON PLAN Coordinate GeometryLff Lim60% (5)
- ER2010 SchweigerDocument15 pagesER2010 SchweigerAnonymous D5s00DdUNo ratings yet
- Problem Set 3 (Solution)Document5 pagesProblem Set 3 (Solution)Mark AstigNo ratings yet
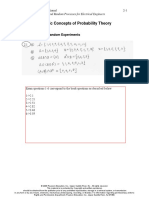
- Chapter 2: Basic Concepts of Probability Theory: 2.1 Specifying Random ExperimentsDocument6 pagesChapter 2: Basic Concepts of Probability Theory: 2.1 Specifying Random ExperimentsSonam AlviNo ratings yet
- Comparative Bio Mechanics of ThrowingsDocument25 pagesComparative Bio Mechanics of ThrowingsAttilio SacripantiNo ratings yet
- How To Calculate P90 (Or Other PXX) PV Energy Yield Estimates - SolargisDocument8 pagesHow To Calculate P90 (Or Other PXX) PV Energy Yield Estimates - SolargisgoyalmanojNo ratings yet
- Lesson Plan - Maths - Create Graphs Based On Data CollectedDocument2 pagesLesson Plan - Maths - Create Graphs Based On Data Collectedapi-464562811No ratings yet
- Frequency Distribution Table GraphDocument10 pagesFrequency Distribution Table GraphHannah ArañaNo ratings yet
- Principles of Form and DesignDocument350 pagesPrinciples of Form and DesignNora Maloku100% (8)
- An Improved Method For Grinding Mill Filling Measurement and TheDocument9 pagesAn Improved Method For Grinding Mill Filling Measurement and Thehasan70 sheykhiNo ratings yet
- Package Survival': R Topics DocumentedDocument185 pagesPackage Survival': R Topics DocumentedFlorencia FirenzeNo ratings yet
- Phet Alpha DecayDocument2 pagesPhet Alpha DecayAndika Sanjaya100% (1)
- Math 10 Week 2Document10 pagesMath 10 Week 2Myla MillapreNo ratings yet
- Fundamentals of Neural NetworksDocument62 pagesFundamentals of Neural NetworksDivya Aseeja100% (2)
- Breaker Thesis PDFDocument121 pagesBreaker Thesis PDFKarthik SriramakavachamNo ratings yet
- Microsoft Azure Infrastructure Services for Architects: Designing Cloud SolutionsFrom EverandMicrosoft Azure Infrastructure Services for Architects: Designing Cloud SolutionsNo ratings yet
- ITIL® 4 Create, Deliver and Support (CDS): Your companion to the ITIL 4 Managing Professional CDS certificationFrom EverandITIL® 4 Create, Deliver and Support (CDS): Your companion to the ITIL 4 Managing Professional CDS certificationRating: 5 out of 5 stars5/5 (2)
- Hacking: A Beginners Guide To Your First Computer Hack; Learn To Crack A Wireless Network, Basic Security Penetration Made Easy and Step By Step Kali LinuxFrom EverandHacking: A Beginners Guide To Your First Computer Hack; Learn To Crack A Wireless Network, Basic Security Penetration Made Easy and Step By Step Kali LinuxRating: 4.5 out of 5 stars4.5/5 (67)
- Hacking Network Protocols: Complete Guide about Hacking, Scripting and Security of Computer Systems and Networks.From EverandHacking Network Protocols: Complete Guide about Hacking, Scripting and Security of Computer Systems and Networks.Rating: 5 out of 5 stars5/5 (2)
- Evaluation of Some Websites that Offer Virtual Phone Numbers for SMS Reception and Websites to Obtain Virtual Debit/Credit Cards for Online Accounts VerificationsFrom EverandEvaluation of Some Websites that Offer Virtual Phone Numbers for SMS Reception and Websites to Obtain Virtual Debit/Credit Cards for Online Accounts VerificationsRating: 5 out of 5 stars5/5 (1)
- The Compete Ccna 200-301 Study Guide: Network Engineering EditionFrom EverandThe Compete Ccna 200-301 Study Guide: Network Engineering EditionRating: 5 out of 5 stars5/5 (4)
- AWS Certified Solutions Architect Study Guide: Associate SAA-C01 ExamFrom EverandAWS Certified Solutions Architect Study Guide: Associate SAA-C01 ExamRating: 4 out of 5 stars4/5 (1)
- Cybersecurity: The Beginner's Guide: A comprehensive guide to getting started in cybersecurityFrom EverandCybersecurity: The Beginner's Guide: A comprehensive guide to getting started in cybersecurityRating: 5 out of 5 stars5/5 (2)
- Palo Alto Networks: The Ultimate Guide To Quickly Pass All The Exams And Getting Certified. Real Practice Test With Detailed Screenshots, Answers And ExplanationsFrom EverandPalo Alto Networks: The Ultimate Guide To Quickly Pass All The Exams And Getting Certified. Real Practice Test With Detailed Screenshots, Answers And ExplanationsNo ratings yet
- Practical TCP/IP and Ethernet Networking for IndustryFrom EverandPractical TCP/IP and Ethernet Networking for IndustryRating: 4 out of 5 stars4/5 (2)
- Cybersecurity: A Simple Beginner’s Guide to Cybersecurity, Computer Networks and Protecting Oneself from Hacking in the Form of Phishing, Malware, Ransomware, and Social EngineeringFrom EverandCybersecurity: A Simple Beginner’s Guide to Cybersecurity, Computer Networks and Protecting Oneself from Hacking in the Form of Phishing, Malware, Ransomware, and Social EngineeringRating: 5 out of 5 stars5/5 (40)
- AWS Certified Solutions Architect Study Guide: Associate SAA-C02 ExamFrom EverandAWS Certified Solutions Architect Study Guide: Associate SAA-C02 ExamNo ratings yet
- Set Up Your Own IPsec VPN, OpenVPN and WireGuard Server: Build Your Own VPNFrom EverandSet Up Your Own IPsec VPN, OpenVPN and WireGuard Server: Build Your Own VPNRating: 5 out of 5 stars5/5 (1)
- Computer Networking: The Complete Beginner's Guide to Learning the Basics of Network Security, Computer Architecture, Wireless Technology and Communications Systems (Including Cisco, CCENT, and CCNA)From EverandComputer Networking: The Complete Beginner's Guide to Learning the Basics of Network Security, Computer Architecture, Wireless Technology and Communications Systems (Including Cisco, CCENT, and CCNA)Rating: 4 out of 5 stars4/5 (4)
- ITIL® 4 Create, Deliver and Support (CDS): Your companion to the ITIL 4 Managing Professional CDS certificationFrom EverandITIL® 4 Create, Deliver and Support (CDS): Your companion to the ITIL 4 Managing Professional CDS certificationNo ratings yet
- Open Radio Access Network (O-RAN) Systems Architecture and DesignFrom EverandOpen Radio Access Network (O-RAN) Systems Architecture and DesignNo ratings yet
- CWNA Certified Wireless Network Administrator Study Guide: Exam CWNA-108From EverandCWNA Certified Wireless Network Administrator Study Guide: Exam CWNA-108No ratings yet
- Microsoft Certified Azure Fundamentals Study Guide: Exam AZ-900From EverandMicrosoft Certified Azure Fundamentals Study Guide: Exam AZ-900No ratings yet