You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Assignment 1 - Tiered LessonDocument15 pagesAssignment 1 - Tiered Lessonapi-320736246No ratings yet
- © Call Centre Helper: 171 Factorial #VALUE! This Will Cause Errors in Your CalculationsDocument19 pages© Call Centre Helper: 171 Factorial #VALUE! This Will Cause Errors in Your CalculationswircexdjNo ratings yet
- MBA Study On Organisational Culture and Its Impact On Employees Behaviour - 237652089Document64 pagesMBA Study On Organisational Culture and Its Impact On Employees Behaviour - 237652089sunitha kada55% (20)
- Chapter 3 - Basic Logical Concepts - For Students PDFDocument65 pagesChapter 3 - Basic Logical Concepts - For Students PDFTiên Nguyễn100% (1)
- Project Plan SealDocument19 pagesProject Plan SealantsouNo ratings yet
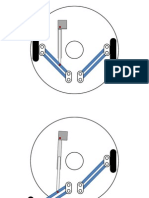
- Landing GearDocument2 pagesLanding GearantsouNo ratings yet
- 2N CatalogDocument31 pages2N CatalogantsouNo ratings yet
- Face RecognitionDocument8 pagesFace RecognitionantsouNo ratings yet
- Portable Ground Control Station: A Universal Off-The Shelf SolutionDocument3 pagesPortable Ground Control Station: A Universal Off-The Shelf SolutionantsouNo ratings yet
- Face RecognitionDocument7 pagesFace RecognitionantsouNo ratings yet
- Portable Ground Control Station User ManualDocument23 pagesPortable Ground Control Station User ManualantsouNo ratings yet
- Onboard Generator System User Manual V1.4 PDFDocument16 pagesOnboard Generator System User Manual V1.4 PDFantsouNo ratings yet
- Pitot-Static Length Selection V1 0 PDFDocument1 pagePitot-Static Length Selection V1 0 PDFantsouNo ratings yet
- Combined Pitot - Static Tube: Datasheet V 2.0Document1 pageCombined Pitot - Static Tube: Datasheet V 2.0antsouNo ratings yet
- 2N SIP Speaker: Far More Than Just IP PagingDocument2 pages2N SIP Speaker: Far More Than Just IP PagingantsouNo ratings yet
- 2N SIP Speaker: Far More Than Just IP PagingDocument2 pages2N SIP Speaker: Far More Than Just IP PagingantsouNo ratings yet
- Betaface SDK PDFDocument45 pagesBetaface SDK PDFantsouNo ratings yet
- Face RecognitionDocument2 pagesFace RecognitionantsouNo ratings yet
- SmartGate BrochureDocument2 pagesSmartGate BrochureantsouNo ratings yet
- Face RecognitionDocument83 pagesFace RecognitionantsouNo ratings yet
- 2N NetStar Product Presentation End Users enDocument14 pages2N NetStar Product Presentation End Users enantsouNo ratings yet
- Face RecognitionDocument30 pagesFace RecognitionantsouNo ratings yet
- 2N Netstar: Discover The Simplicity of CommunicationDocument4 pages2N Netstar: Discover The Simplicity of CommunicationantsouNo ratings yet
- 2n Catalogue 2011Document48 pages2n Catalogue 2011antsouNo ratings yet
- 2N NetStar Product Presentation End Users enDocument14 pages2N NetStar Product Presentation End Users enantsouNo ratings yet
- 2n Catalogue 2009Document26 pages2n Catalogue 2009antsouNo ratings yet
- Top Sec 703 Plus enDocument2 pagesTop Sec 703 Plus enantsouNo ratings yet
- 2n Easygate Umts UsbDocument6 pages2n Easygate Umts UsbantsouNo ratings yet
- OmniSwitch Transceivers GuideDocument52 pagesOmniSwitch Transceivers GuideantsouNo ratings yet
- PanoLogic DS Pano System DS-PS-081710Document2 pagesPanoLogic DS Pano System DS-PS-081710antsouNo ratings yet
- 2n Net Speaker PresentationDocument34 pages2n Net Speaker PresentationantsouNo ratings yet
- Lean Itam WP 221626Document19 pagesLean Itam WP 221626antsouNo ratings yet
- PanoLogic DS Pano Device DS-PD-081010Document2 pagesPanoLogic DS Pano Device DS-PD-081010antsouNo ratings yet
- A Method For Identifying Human Factors Concerns During The HAZOP Process - Dennis AttwoodDocument5 pagesA Method For Identifying Human Factors Concerns During The HAZOP Process - Dennis AttwoodAlvaro Andres Blanco GomezNo ratings yet
- Dasha TransitDocument43 pagesDasha Transitvishwanath100% (2)
- Mitchell 1986Document34 pagesMitchell 1986Sara Veronica Florentin CuencaNo ratings yet
- Upsized To 12 Gallon Still On A 36"x56" Sheet: Pint O Shine's 6 Gallon Pot Still Design and TemplateDocument50 pagesUpsized To 12 Gallon Still On A 36"x56" Sheet: Pint O Shine's 6 Gallon Pot Still Design and TemplateyamyrulesNo ratings yet
- Receiving Welcoming and Greeting of GuestDocument18 pagesReceiving Welcoming and Greeting of GuestMarwa KorkabNo ratings yet
- Navier-Stokes EquationsDocument395 pagesNavier-Stokes EquationsBouhadjar Meguenni100% (7)
- Digital Logic Design: Dr. Oliver FaustDocument16 pagesDigital Logic Design: Dr. Oliver FaustAtifMinhasNo ratings yet
- C1 Reading 1Document2 pagesC1 Reading 1Alejandros BrosNo ratings yet
- Literary Text Analysis WorksheetDocument1 pageLiterary Text Analysis Worksheetapi-403444340No ratings yet
- Key Note Units 3-4Document4 pagesKey Note Units 3-4Javier BahenaNo ratings yet
- Cellulose StructureDocument9 pagesCellulose Structuremanoj_rkl_07No ratings yet
- Shailesh Sharma HoroscopeDocument46 pagesShailesh Sharma Horoscopeapi-3818255No ratings yet
- Watershed Management A Case Study of Madgyal Village IJERTV2IS70558Document5 pagesWatershed Management A Case Study of Madgyal Village IJERTV2IS70558SharadNo ratings yet
- Users GuideDocument34 pagesUsers GuideZaratustra NietzcheNo ratings yet
- MGMT 410 Book ReportDocument1 pageMGMT 410 Book ReportLester F BoernerNo ratings yet
- Platon Si Academia Veche de ZellerDocument680 pagesPlaton Si Academia Veche de ZellerDan BrizaNo ratings yet
- RealPOS 70Document182 pagesRealPOS 70TextbookNo ratings yet
- Roadmap For SSC CGLDocument11 pagesRoadmap For SSC CGLibt seoNo ratings yet
- Malla Reddy Engineering College (Autonomous)Document17 pagesMalla Reddy Engineering College (Autonomous)Ranjith KumarNo ratings yet
- Policarpio 3 - Refresher GEODocument2 pagesPolicarpio 3 - Refresher GEOJohn RoaNo ratings yet
- Research ProposalDocument2 pagesResearch ProposalHo Manh LinhNo ratings yet
- Assignment2-9509Document5 pagesAssignment2-9509ritadhikarycseNo ratings yet
- Writing and Presenting A Project Proposal To AcademicsDocument87 pagesWriting and Presenting A Project Proposal To AcademicsAllyNo ratings yet
- Lenovo IdeaPad U350 UserGuide V1.0Document138 pagesLenovo IdeaPad U350 UserGuide V1.0Marc BengtssonNo ratings yet
- Investigation of Water Resources Projects - Preparation of DPRDocument148 pagesInvestigation of Water Resources Projects - Preparation of DPRN.J. PatelNo ratings yet
- Shaft design exercisesDocument8 pagesShaft design exercisesIvanRosellAgustíNo ratings yet