You might also like
- Math 114Document35 pagesMath 114ShailendraPatelNo ratings yet
- Jemh114 PDFDocument35 pagesJemh114 PDFrenuka nagareNo ratings yet
- Mean Mode MedianDocument17 pagesMean Mode MedianzenneyNo ratings yet
- ©ncert Not To Be Republished: StatisticsDocument33 pages©ncert Not To Be Republished: StatisticsBhaskar KarumuriNo ratings yet
- Aritmetička SredinaDocument6 pagesAritmetička SredinapetarnurkiccNo ratings yet
- StatisticsDocument24 pagesStatisticsthinkiitNo ratings yet
- CH 14 StatisticsDocument3 pagesCH 14 StatisticsKarthikeya R SNo ratings yet
- Jee Mains + Boards MathsDocument89 pagesJee Mains + Boards MathsAyush SrivastavNo ratings yet
- Measures of Central TendencyDocument18 pagesMeasures of Central TendencySANIUL ISLAM100% (1)
- 4 Measures Used To Summarise DataDocument44 pages4 Measures Used To Summarise DataAdnan SajidNo ratings yet
- Tatistics: Grouped Data. We Shall Also Discuss The Concept of Cumulative Frequency, The OgivesDocument31 pagesTatistics: Grouped Data. We Shall Also Discuss The Concept of Cumulative Frequency, The OgivesDevNo ratings yet
- Math 10-Q1-M3Document13 pagesMath 10-Q1-M3Ainee Grace DolleteNo ratings yet
- AveragesDocument7 pagesAveragesZerlene RuchandaniNo ratings yet
- Mean Median ModeDocument12 pagesMean Median ModeSriram Mohan100% (2)
- 10th Class AP EM Mathematics 14 StatisticsDocument30 pages10th Class AP EM Mathematics 14 StatisticsmaheshNo ratings yet
- Class 5.2 B Business Statistics Central Tendency: Research Scholar Priya ChughDocument50 pagesClass 5.2 B Business Statistics Central Tendency: Research Scholar Priya ChughPriya ChughNo ratings yet
- NCERT Book Class 10 Mathematics Chapter 14 StatisticsDocument35 pagesNCERT Book Class 10 Mathematics Chapter 14 Statisticssaksham vermaNo ratings yet
- Measures of Central Tendency and Other Positional MeasuresDocument13 pagesMeasures of Central Tendency and Other Positional Measuresbv123bvNo ratings yet
- MEDIAN and The QuartilesDocument6 pagesMEDIAN and The QuartilesWaqasMahmoodNo ratings yet
- StatisticsDocument32 pagesStatisticsthinkiit70% (20)
- Mean Median MathsDocument24 pagesMean Median MathsanandsonachalamNo ratings yet
- 12 StatisticsDocument22 pages12 StatisticsKAPIL SHARMANo ratings yet
- ST102 Exercise 1Document4 pagesST102 Exercise 1Jiang HNo ratings yet
- 9+&+10+Hindi+Umang+-+CBSE+10+-+2020+ +statistics+-+1+ +Introduction+and+mean+of+Grouped+Data+ +16th+IOctDocument40 pages9+&+10+Hindi+Umang+-+CBSE+10+-+2020+ +statistics+-+1+ +Introduction+and+mean+of+Grouped+Data+ +16th+IOctMariyam AfreenNo ratings yet
- Rfewrf 34 F 34 F 3 WDocument6 pagesRfewrf 34 F 34 F 3 WTiago CostaNo ratings yet
- StatisticsDocument72 pagesStatisticsAvinash Sharma100% (1)
- Prepared by Mr. A.P Nanada, Associate Prof. (OM) : Decision Science Sub. Code: MBA 105 (For MBA Students)Document247 pagesPrepared by Mr. A.P Nanada, Associate Prof. (OM) : Decision Science Sub. Code: MBA 105 (For MBA Students)saubhagya ranjan routNo ratings yet
- Ifp 20-21 PNS1 Unit9 Ce01 LiveworkshopDocument44 pagesIfp 20-21 PNS1 Unit9 Ce01 Liveworkshopwepifo5630No ratings yet
- Lesson 3: Measures of Central Tendency: Total Number of Scores Population N Sample NDocument12 pagesLesson 3: Measures of Central Tendency: Total Number of Scores Population N Sample NTracy Blair Napa-egNo ratings yet
- Measure of Central Tendency in StatisticsDocument16 pagesMeasure of Central Tendency in StatisticsAnshu SinghNo ratings yet
- StatisticsDocument17 pagesStatisticsSameer VadsariaNo ratings yet
- Averages SumsDocument9 pagesAverages SumsVarun Urs M SNo ratings yet
- 202021-IX-QB13 - StatisticsDocument3 pages202021-IX-QB13 - Statisticscookie pumpkinNo ratings yet
- Various Measures of Central TendencyDocument17 pagesVarious Measures of Central TendencypurivikrantNo ratings yet
- 6.mean and MedianDocument8 pages6.mean and MedianNitya SooriNo ratings yet
- 10 Mathematics Impq Sa 1 6 Statistics 2Document5 pages10 Mathematics Impq Sa 1 6 Statistics 2ranyNo ratings yet
- Lesson 15 ANOVA (Analysis of Variance)Document6 pagesLesson 15 ANOVA (Analysis of Variance)Maria PappaNo ratings yet
- Chapter 3 - Describing Comparing DataDocument21 pagesChapter 3 - Describing Comparing DataPedro ChocoNo ratings yet
- QuartilesDocument8 pagesQuartilessushiljp1984No ratings yet
- Ex 14.3 SolutionDocument8 pagesEx 14.3 SolutionkokilaNo ratings yet
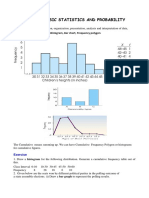
- Unit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonDocument6 pagesUnit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonVenkatesh WaranNo ratings yet
- Wikimama Class 11 CH 15 StatisticsDocument8 pagesWikimama Class 11 CH 15 StatisticsWikimamaNo ratings yet
- Arithematic Mean: B A Final EconomicsDocument12 pagesArithematic Mean: B A Final EconomicsManak Ram SingariyaNo ratings yet
- Tutorial Letter 201/1/2018: Psychological ResearchDocument18 pagesTutorial Letter 201/1/2018: Psychological Researchyjff5k8xxrNo ratings yet
- 5Document16 pages5Sanya BajajNo ratings yet
- X, Taking On K Different Values X, X, X, ... X, F, F, ... F X F X X X X N N FDocument9 pagesX, Taking On K Different Values X, X, X, ... X, F, F, ... F X F X X X X N N FIbrahim OjedokunNo ratings yet
- Lesson 4 Measure of Central TendencyDocument20 pagesLesson 4 Measure of Central Tendencyrahmanzaini100% (1)
- Module 3 and 4 StatDocument31 pagesModule 3 and 4 StatBrandon BorromeoNo ratings yet
- Mathematics 1 Class X (2020-21)Document32 pagesMathematics 1 Class X (2020-21)Binode SarkarNo ratings yet
- Statistics Miscellaneous QuestionsDocument3 pagesStatistics Miscellaneous QuestionsNipun GoyalNo ratings yet
- Measure of Central TendencyDocument113 pagesMeasure of Central TendencyRajdeep DasNo ratings yet
- Calculating Statistics From Group Continuous DataDocument3 pagesCalculating Statistics From Group Continuous DataMaryam AleemNo ratings yet
- Chapter 5Document143 pagesChapter 5Adrian EcojedoNo ratings yet
- Average: Points To RememberDocument8 pagesAverage: Points To RememberAyush PrasadNo ratings yet
- Arithmetic Mean: Averages or Measures of Central TendencyDocument9 pagesArithmetic Mean: Averages or Measures of Central TendencySherona ReidNo ratings yet
- NBME 25 Questions VersionDocument201 pagesNBME 25 Questions VersionManpreet KS100% (10)
- Rotational Dynamics Type 1Document12 pagesRotational Dynamics Type 1AAVANINo ratings yet
- Exercise-01 Check Your Grasp: CH CL (A) CH CL (B) CHDocument29 pagesExercise-01 Check Your Grasp: CH CL (A) CH CL (B) CHRajiv KabadNo ratings yet
- Rotational Dynamics Type 1Document12 pagesRotational Dynamics Type 1AAVANINo ratings yet
- Practice Problems For NeetDocument359 pagesPractice Problems For NeetPrudhvi Nath0% (2)
- AP Study Guide PhysicsDocument96 pagesAP Study Guide PhysicsRajiv KabadNo ratings yet
- Complete Math 2 Tests Answers PDFDocument6 pagesComplete Math 2 Tests Answers PDFRajiv KabadNo ratings yet
- AP Unit9 Worksheet AnswersDocument5 pagesAP Unit9 Worksheet AnswersAAVANINo ratings yet
- Complete Chemistry Tests AnsDocument7 pagesComplete Chemistry Tests AnsRajiv KabadNo ratings yet
- Complete Chemistry Tests PDFDocument136 pagesComplete Chemistry Tests PDFInder BalajiNo ratings yet
- SC2 - O'Malley SAT II Review (Organic)Document2 pagesSC2 - O'Malley SAT II Review (Organic)Rajiv KabadNo ratings yet
- LogicgatesDocument17 pagesLogicgatesRajiv KabadNo ratings yet
- Life Processes Class 10 Notes Science - MyCBSEguide - CBSE Papers & NCERT SolutionsDocument5 pagesLife Processes Class 10 Notes Science - MyCBSEguide - CBSE Papers & NCERT SolutionsRajiv KabadNo ratings yet
- Essentials 2018 Final Feb2018Document45 pagesEssentials 2018 Final Feb2018Rajiv KabadNo ratings yet
- CBSE Class 9 Social Science Question BankDocument120 pagesCBSE Class 9 Social Science Question BankRajiv Kabad100% (2)
- Cardiac CycleDocument1 pageCardiac CycleRajiv KabadNo ratings yet
- 15-0000 - Form - QEWS - Standard Pediatric Observation Chart - 0 To 28 DaysDocument2 pages15-0000 - Form - QEWS - Standard Pediatric Observation Chart - 0 To 28 DaysRajiv KabadNo ratings yet
- NFO Note - Reliance Dual Advantage Fixed Tenure Fund XI - Plan ADocument3 pagesNFO Note - Reliance Dual Advantage Fixed Tenure Fund XI - Plan ARajiv KabadNo ratings yet
- Chem RecordDocument82 pagesChem RecordRajiv KabadNo ratings yet
- 15-0000 - Form - QEWS - Standard Pediatric Observation Chart - 0 To 28 DaysDocument2 pages15-0000 - Form - QEWS - Standard Pediatric Observation Chart - 0 To 28 DaysRajiv KabadNo ratings yet
- 15-0648 Form QEWS Standard+Pediatric+Observation+Chart 5+to+11yrsDocument2 pages15-0648 Form QEWS Standard+Pediatric+Observation+Chart 5+to+11yrsRajiv KabadNo ratings yet
- 1 1 3 5 1Document36 pages1 1 3 5 1rahulNo ratings yet
- ComputerDocument3 pagesComputerRajiv KabadNo ratings yet
- CardiacDocument1 pageCardiacRajiv KabadNo ratings yet
- Birla Public School, Doha-Qatar: Class Xi-Holiday Homework-Biology Record CompletionDocument1 pageBirla Public School, Doha-Qatar: Class Xi-Holiday Homework-Biology Record CompletionRajiv KabadNo ratings yet
- Morp. of PlantsDocument26 pagesMorp. of PlantsRajiv KabadNo ratings yet
- 31-2-2 ScienceDocument16 pages31-2-2 ScienceRajiv KabadNo ratings yet
- © Ncert Not To Be Republished: Principle of Mathematical InductionDocument12 pages© Ncert Not To Be Republished: Principle of Mathematical InductionSCReddyNo ratings yet
- Holiday HWDocument4 pagesHoliday HWRajiv Kabad100% (1)
- Idi AminDocument1 pageIdi AminRajiv KabadNo ratings yet
- Free ConvectionDocument4 pagesFree ConvectionLuthfy AditiarNo ratings yet
- Cella Di Carico Sartorius MP77 eDocument3 pagesCella Di Carico Sartorius MP77 eNCNo ratings yet
- Monster Hunter: World - Canteen IngredientsDocument5 pagesMonster Hunter: World - Canteen IngredientsSong HoeNo ratings yet
- Iso 22301 2019 en PDFDocument11 pagesIso 22301 2019 en PDFImam Saleh100% (3)
- WoundVite®, The #1 Most Comprehensive Wound, Scar and Post-Surgical Repair Formula Receives Amazon's Choice High RatingsDocument3 pagesWoundVite®, The #1 Most Comprehensive Wound, Scar and Post-Surgical Repair Formula Receives Amazon's Choice High RatingsPR.comNo ratings yet
- Te-Chemical Sem5 CPNM-CBCGS Dec19Document2 pagesTe-Chemical Sem5 CPNM-CBCGS Dec19Mayank ShelarNo ratings yet
- High Speed Power TransferDocument33 pagesHigh Speed Power TransferJAYKUMAR SINGHNo ratings yet
- Essay On Stem CellsDocument4 pagesEssay On Stem CellsAdrien G. S. WaldNo ratings yet
- AN44061A Panasonic Electronic Components Product DetailsDocument3 pagesAN44061A Panasonic Electronic Components Product DetailsAdam StariusNo ratings yet
- Taylorism vs. FordismDocument2 pagesTaylorism vs. FordismLiv Maloney67% (3)
- ENSC1001 Unit Outline 2014Document12 pagesENSC1001 Unit Outline 2014TheColonel999No ratings yet
- EDAG0007Document5 pagesEDAG0007krunalNo ratings yet
- Nbme NotesDocument3 pagesNbme NotesShariq AkramNo ratings yet
- 3DS 2017 GEO GEMS Brochure A4 WEBDocument4 pages3DS 2017 GEO GEMS Brochure A4 WEBlazarpaladinNo ratings yet
- The Perception of Luxury Cars MA Thesis 25 03Document60 pagesThe Perception of Luxury Cars MA Thesis 25 03Quaxi1954No ratings yet
- Lab 1Document51 pagesLab 1aliNo ratings yet
- Passage Planning: Dr. Arwa HusseinDocument15 pagesPassage Planning: Dr. Arwa HusseinArwa Hussein100% (3)
- Yu ZbornikDocument511 pagesYu ZbornikВладимирРакоњацNo ratings yet
- Off Grid Solar Hybrid Inverter Operate Without Battery: HY VMII SeriesDocument1 pageOff Grid Solar Hybrid Inverter Operate Without Battery: HY VMII SeriesFadi Ramadan100% (1)
- Citrus Information Kit-Update: Reprint - Information Current in 1998Document53 pagesCitrus Information Kit-Update: Reprint - Information Current in 1998hamsa sewakNo ratings yet
- The Teacher Research Movement: A Decade Later: Cite This PaperDocument13 pagesThe Teacher Research Movement: A Decade Later: Cite This PaperAlexandre NecromanteionNo ratings yet
- Assessment - UK Forestry Data ICT THEORY For CAT1Document13 pagesAssessment - UK Forestry Data ICT THEORY For CAT1Joanna AchemaNo ratings yet
- Or HandoutDocument190 pagesOr Handoutyared haftu67% (6)
- Batron: 29 5 MM Character Height LCD Modules 29Document1 pageBatron: 29 5 MM Character Height LCD Modules 29Diego OliveiraNo ratings yet
- The Fastest Easiest Way To Secure Your NetworkDocument9 pagesThe Fastest Easiest Way To Secure Your NetworkMark ShenkNo ratings yet
- Week 3 Alds 2202Document13 pagesWeek 3 Alds 2202lauren michaelsNo ratings yet
- Macros and DirectiveDocument7 pagesMacros and DirectiveAbdul MoeedNo ratings yet
- Machine Design 2021 Guidelines and MechanicsDocument2 pagesMachine Design 2021 Guidelines and Mechanicsreneil llegueNo ratings yet
- Reinforced Concrete Design PDFDocument1 pageReinforced Concrete Design PDFhallelNo ratings yet
- Exemption in Experience & Turnover CriteriaDocument4 pagesExemption in Experience & Turnover CriteriaVivek KumarNo ratings yet