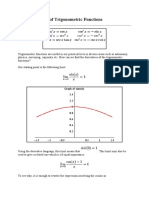
You might also like
- Solution of Linear System Theory and Design 3ed For Chi-Tsong ChenDocument106 pagesSolution of Linear System Theory and Design 3ed For Chi-Tsong ChenQingyu Meng89% (19)
- Matrix Algebra by A.S.HadiDocument4 pagesMatrix Algebra by A.S.HadiHevantBhojaram0% (1)
- First Steps InnaDocument232 pagesFirst Steps InnaEmre CanNo ratings yet
- Gauss SeidelDocument8 pagesGauss SeidelJose Andres G. RojasNo ratings yet
- Cholesky Decomposition: 1 1 2 1 2) /2), and X 2 2 1Document7 pagesCholesky Decomposition: 1 1 2 1 2) /2), and X 2 2 1yuliandraNo ratings yet
- Cholesky DecompositionDocument8 pagesCholesky Decompositionmohsinali680No ratings yet
- Gaussian EliminationDocument22 pagesGaussian Eliminationnefoxy100% (1)
- SymmetryDocument117 pagesSymmetryTom DavisNo ratings yet
- Final Exam - Dela Cruz, RegelleDocument11 pagesFinal Exam - Dela Cruz, RegelleDela Cruz, Sophia Alexisse O.No ratings yet
- Lesson 4Document58 pagesLesson 4Md Kaiser HamidNo ratings yet
- Linear Algebra Review: CSC2515 - Machine Learning - Fall 2002Document7 pagesLinear Algebra Review: CSC2515 - Machine Learning - Fall 2002Pravin BhandarkarNo ratings yet
- Algebra Reference: Basic IdentitiesDocument18 pagesAlgebra Reference: Basic IdentitiesgowsikhNo ratings yet
- Engg AnalysisDocument117 pagesEngg AnalysisrajeshtaladiNo ratings yet
- Linear Models: The Least-Squares Method, The Perceptron: A Heuristic Learning Algorithm ForDocument25 pagesLinear Models: The Least-Squares Method, The Perceptron: A Heuristic Learning Algorithm ForChrsan RamNo ratings yet
- Operation ResearchDocument10 pagesOperation Researchkawaljeet_singhNo ratings yet
- 124 - Section 1.2Document41 pages124 - Section 1.2Aesthetic DukeNo ratings yet
- Linear Models: The Least-Squares MethodDocument24 pagesLinear Models: The Least-Squares MethodAnimated EngineerNo ratings yet
- PHY 313: Quantum Mechanics 2: School of Physics, IISER Thiruvananthapuram (Dated: August 4, 2011)Document4 pagesPHY 313: Quantum Mechanics 2: School of Physics, IISER Thiruvananthapuram (Dated: August 4, 2011)Mani Ratnam RaiNo ratings yet
- Anharmonic Oscillator: Introduction and The Simple Harmonic OscillatorDocument5 pagesAnharmonic Oscillator: Introduction and The Simple Harmonic OscillatorGautam SharmaNo ratings yet
- A Project On Solution To Transcendental Equation Using Clamped Cubic SplineDocument14 pagesA Project On Solution To Transcendental Equation Using Clamped Cubic SplineAmmar NasirNo ratings yet
- Chapter 21Document6 pagesChapter 21manikannanp_ponNo ratings yet
- Why The Sum of Everything Is Almost Negative NothingDocument16 pagesWhy The Sum of Everything Is Almost Negative Nothingsccylones100% (1)
- Module 3: Frequency Control in A Power System Lecture 12a: Solution of Non-Linear Algebraic EquationsDocument5 pagesModule 3: Frequency Control in A Power System Lecture 12a: Solution of Non-Linear Algebraic EquationsAshwani RanaNo ratings yet
- The Derivatives of Trigonometric FunctionsDocument29 pagesThe Derivatives of Trigonometric FunctionsM Arifin RasdhakimNo ratings yet
- Lagrange Multipliers: Navigation SearchDocument25 pagesLagrange Multipliers: Navigation SearchlithaNo ratings yet
- Mandelbrot SetDocument6 pagesMandelbrot SetanonymousplatonistNo ratings yet
- Solving Equations: Word ExamplesDocument5 pagesSolving Equations: Word ExamplesWeb BooksNo ratings yet
- Discrete TopicDocument28 pagesDiscrete TopicJai ChavezNo ratings yet
- Classical LinearReg 000Document41 pagesClassical LinearReg 000Umair AyazNo ratings yet
- Unit 2 - DSADocument15 pagesUnit 2 - DSARoshanaa RNo ratings yet
- Appendex EDocument9 pagesAppendex EMilkessa SeyoumNo ratings yet
- Method of Steepest Descent NavvvDocument6 pagesMethod of Steepest Descent NavvvJassi BoparaiNo ratings yet
- ML Model Paper 2 SolutionDocument15 pagesML Model Paper 2 SolutionVIKAS KUMARNo ratings yet
- Modular ArithmeticDocument7 pagesModular ArithmeticjaneNo ratings yet
- Sym Band DocDocument7 pagesSym Band DocAlex CooperNo ratings yet
- Systems of EquationsDocument26 pagesSystems of EquationsLuis PressoNo ratings yet
- Basic Concepts of Optimization: The The The SetDocument10 pagesBasic Concepts of Optimization: The The The SetDennis LingNo ratings yet
- Linear Programming and The Simplex Method: David GaleDocument6 pagesLinear Programming and The Simplex Method: David GaleRichard Canar PerezNo ratings yet
- Rational Numbers As ExponentsDocument4 pagesRational Numbers As Exponentstutorciecle123No ratings yet
- Remark 27 Remember That, in General, The Word Scalar Is Not Restricted To RealDocument11 pagesRemark 27 Remember That, in General, The Word Scalar Is Not Restricted To RealsatishaparnaNo ratings yet
- Solution of Nonlinear EquationsDocument4 pagesSolution of Nonlinear Equationstarun gehlotNo ratings yet
- WLRDocument4 pagesWLREstira Woro Astrini MartodihardjoNo ratings yet
- Case Study-Ii: G ROU P-1.Muska N SINGH (02 8) 2.naman Kaushik (029) 3.nishanDocument14 pagesCase Study-Ii: G ROU P-1.Muska N SINGH (02 8) 2.naman Kaushik (029) 3.nishanParas GuptaNo ratings yet
- Equations With Linear Coefficients: Expl #9 Non-Parallel CoefficientsDocument6 pagesEquations With Linear Coefficients: Expl #9 Non-Parallel CoefficientsNisa KaleciNo ratings yet
- CH 04Document38 pagesCH 04Musarat NazirNo ratings yet
- Linear Algebra IDocument43 pagesLinear Algebra IDaniel GreenNo ratings yet
- SampleDocument6 pagesSampleShruti SinghNo ratings yet
- Assissgment - 2 Topic:: Google'S Mehanicsim For Ranking Web Pages AimDocument7 pagesAssissgment - 2 Topic:: Google'S Mehanicsim For Ranking Web Pages AimBOGGARAPU KUSHALKUMAR 15MIS0446No ratings yet
- Linear Least SquaresDocument10 pagesLinear Least Squareswatson191No ratings yet
- Asymptotic Analysis - WikipediaDocument5 pagesAsymptotic Analysis - Wikipediabibekananda87No ratings yet
- Partial Fraction DecompositionDocument4 pagesPartial Fraction Decompositionapi-150547803No ratings yet
- ML CourseraDocument10 pagesML CourseraShaheer KhanNo ratings yet
- Reviewer BSEE (Calculus)Document13 pagesReviewer BSEE (Calculus)Ronalyn ManzanoNo ratings yet
- Prove That Eigen Value of Hermittian Matrix Are Alays Real - Give Example - Use The Above Result To Show That Det (H-3I) Cannot Be Zero - If H Is Hermittian Matrix and I Is Unit MatrixDocument13 pagesProve That Eigen Value of Hermittian Matrix Are Alays Real - Give Example - Use The Above Result To Show That Det (H-3I) Cannot Be Zero - If H Is Hermittian Matrix and I Is Unit MatrixAman KheraNo ratings yet
- My Revision Notes (Entire Unit) c4 Edexcel NotesDocument15 pagesMy Revision Notes (Entire Unit) c4 Edexcel Notesjun29No ratings yet
- Residuals Least-Squares Method Univariate RegressionDocument17 pagesResiduals Least-Squares Method Univariate RegressionergrehgeNo ratings yet
- Bool Bool True False False True: Lawvere's Fixed Point TheoremDocument11 pagesBool Bool True False False True: Lawvere's Fixed Point TheoremΓιάννης ΣτεργίουNo ratings yet
- LESSON 5 Systems of Linear EquationsDocument16 pagesLESSON 5 Systems of Linear EquationsMa RiaNo ratings yet
- Eprints - Eemcs.utwente - NL 9077 01 0394VandenBroek Rankings..pairwiseDocument3 pagesEprints - Eemcs.utwente - NL 9077 01 0394VandenBroek Rankings..pairwiseabebotalardyNo ratings yet
- Complex Calculus Formula Sheet - 3rd SEMDocument6 pagesComplex Calculus Formula Sheet - 3rd SEMgetsam123100% (1)
- 18CS42 - Module 5Document52 pages18CS42 - Module 5dreamforya03No ratings yet
- MarkitSERV Presentations 2feb10Document54 pagesMarkitSERV Presentations 2feb10Karen KoleNo ratings yet
- Swift MessagingDocument24 pagesSwift MessagingKaren KoleNo ratings yet
- Tokyo Foreign Exchange MarketDocument30 pagesTokyo Foreign Exchange MarketKaren KoleNo ratings yet
- Otc Processing 1108Document2 pagesOtc Processing 1108Karen KoleNo ratings yet
- Requirements Management InfosysDocument8 pagesRequirements Management InfosysKaren KoleNo ratings yet
- Gaussian Elimination Method PDFDocument14 pagesGaussian Elimination Method PDFUmer farooq100% (1)
- Original PDF Brief Calculus An Applied Approach 9th Edition PDFDocument41 pagesOriginal PDF Brief Calculus An Applied Approach 9th Edition PDFclarence.barcia711100% (36)
- X X X DX: - 1 2 3 - Log Sin XDXDocument6 pagesX X X DX: - 1 2 3 - Log Sin XDXJimmy SinghNo ratings yet
- Chapter 7 StatisticsDocument14 pagesChapter 7 StatisticsBenjamin HiNo ratings yet
- CFD HW2 - Report Prakhar MishraDocument5 pagesCFD HW2 - Report Prakhar Mishraprakhar mishraNo ratings yet
- B.C.A. Semester - II BCA-203: Discrete Mathematics: Difference, D' Morgons Law, Subsets, Power Sets, Partitions SetsDocument2 pagesB.C.A. Semester - II BCA-203: Discrete Mathematics: Difference, D' Morgons Law, Subsets, Power Sets, Partitions SetsBenedictNo ratings yet
- tmp8645 TMPDocument11 pagestmp8645 TMPFrontiersNo ratings yet
- 2019 JC2 H2 Math SA2 Nanyang JCDocument48 pages2019 JC2 H2 Math SA2 Nanyang JCJasmine TanNo ratings yet
- Programming For Computations - PythonDocument244 pagesProgramming For Computations - PythonMarcello CostaNo ratings yet
- CubicandquarticequationsDocument6 pagesCubicandquarticequationssyed junaid ur rehmanNo ratings yet
- Statistical Notes: 1 Normal Random VariableDocument5 pagesStatistical Notes: 1 Normal Random VariableNguyen HangNo ratings yet
- Elementary AlgebraDocument16 pagesElementary AlgebraSaludares, Bonnel John T.No ratings yet
- SS Notes - VMTWDocument67 pagesSS Notes - VMTWNarendra GaliNo ratings yet
- Revision of The Particle-Wave DualismDocument810 pagesRevision of The Particle-Wave DualismMiodrag ProkicNo ratings yet
- Application of Algebra in ArchitectureDocument5 pagesApplication of Algebra in ArchitectureShayne Chinnyreth G. GaloNo ratings yet
- Problems in Lagragian MechanicsDocument1 pageProblems in Lagragian MechanicsPaul RyanNo ratings yet
- Finite Element MethodsDocument20 pagesFinite Element MethodstarasasankaNo ratings yet
- 4 Trigonometric Transformation Trigonometric Substitution and RationalizingDocument10 pages4 Trigonometric Transformation Trigonometric Substitution and RationalizingTreesya EstradaNo ratings yet
- Introduction To Quantizer and Llyod Max QuantizerDocument10 pagesIntroduction To Quantizer and Llyod Max QuantizerNeha SenguptaNo ratings yet
- HTDocument67 pagesHTDHINAKARANVEEMANNo ratings yet
- Kuttler, K. - Multi Variable Calculus, Applications and Theory - 2007, 474sDocument474 pagesKuttler, K. - Multi Variable Calculus, Applications and Theory - 2007, 474sJan_Wensink0% (1)
- The Stable Marriage Problem: Algorithms and NetworksDocument17 pagesThe Stable Marriage Problem: Algorithms and NetworksAhmed ElNaggarNo ratings yet
- 2022dp1maa Test2p2 SolDocument7 pages2022dp1maa Test2p2 SolGrad KeyzNo ratings yet
- Module 3: Linear Programming: Graphical Method: Learning OutcomesDocument9 pagesModule 3: Linear Programming: Graphical Method: Learning OutcomesPeter BobilesNo ratings yet
- Lecture 2: Roots of Equation: Dr. Nor Alafiza YunusDocument62 pagesLecture 2: Roots of Equation: Dr. Nor Alafiza YunusHaziq KhairiNo ratings yet
- 10CS661 Ia2 QBDocument3 pages10CS661 Ia2 QBpramelaNo ratings yet
- Errata 7Document5 pagesErrata 7nemraspNo ratings yet