You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- NEMSDocument14 pagesNEMSsvasanth007No ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- JTAG Use in Embedded SystesmDocument5 pagesJTAG Use in Embedded Systesmsvasanth007No ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- NanofabDocument5 pagesNanofabsvasanth007No ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- NEMSDocument14 pagesNEMSsvasanth007No ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- SDN FirewallDocument11 pagesSDN Firewallsvasanth007No ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- ARM ArchitectureDocument8 pagesARM Architecturesvasanth007No ratings yet
- Lec14 SV AssertionsDocument30 pagesLec14 SV Assertionssvasanth007No ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Floating Point To Fixed Point ConversionDocument19 pagesFloating Point To Fixed Point Conversionnayeem4444No ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Summary Report On The Next Generation of Intel IXP Network ProcessorsDocument5 pagesA Summary Report On The Next Generation of Intel IXP Network Processorssvasanth007No ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Verification Seminar Mapld06Document123 pagesVerification Seminar Mapld06zs8lqr50xb4jNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- ARM ARM Microprocessor Basics Microprocessor Basics: Introduction To ARM Processor Introduction To ARM ProcessorDocument0 pagesARM ARM Microprocessor Basics Microprocessor Basics: Introduction To ARM Processor Introduction To ARM ProcessorVikas UpadhyayNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- FlexPath NP: Reconfigurable Packet Processing ArchitectureDocument5 pagesFlexPath NP: Reconfigurable Packet Processing Architecturesvasanth007No ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- A Summary On "Characterizing Processor Architectures For Programmable Network Interfaces"Document6 pagesA Summary On "Characterizing Processor Architectures For Programmable Network Interfaces"svasanth007No ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- RA7 Vasantham SudheerKumarDocument5 pagesRA7 Vasantham SudheerKumarsvasanth007No ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- EE 533 Verilog Design: Siddharth BhargavDocument25 pagesEE 533 Verilog Design: Siddharth Bhargavsvasanth007No ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
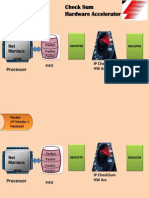
- Check Sum Hardware Accelerator: ProcessorDocument15 pagesCheck Sum Hardware Accelerator: Processorsvasanth007No ratings yet
- Writing Successful Description in VerilogDocument43 pagesWriting Successful Description in VerilogNahyan Chowdhury TamalNo ratings yet
- 2-D Mesh of Switches and Resources Providing Physical-Architectural Level Design Integration Type of Resources Basic ModuleDocument5 pages2-D Mesh of Switches and Resources Providing Physical-Architectural Level Design Integration Type of Resources Basic Modulesvasanth007No ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Measuring Bandwidth between planetlab nodes summaryDocument5 pagesMeasuring Bandwidth between planetlab nodes summarysvasanth007No ratings yet
- Debug WLANDocument3 pagesDebug WLANsvasanth007No ratings yet
- Mems and NemsDocument25 pagesMems and Nemssvasanth007No ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Micro-Network Processor: A Processor Architecture For Implementing Noc RoutersDocument115 pagesMicro-Network Processor: A Processor Architecture For Implementing Noc Routerssvasanth007No ratings yet
- TCL LanguageDocument17 pagesTCL LanguageBinh Phan TranNo ratings yet
- Answer To FIJDocument1 pageAnswer To FIJsvasanth007No ratings yet
- Ridge regression biased estimates nonorthogonal problemsDocument14 pagesRidge regression biased estimates nonorthogonal problemsGHULAM MURTAZANo ratings yet
- Causes and Effects of PollutionDocument6 pagesCauses and Effects of PollutionNhư NgọcNo ratings yet
- II Unit - End EffectorsDocument49 pagesII Unit - End EffectorsGnanasekarNo ratings yet
- NitrocelluloseDocument7 pagesNitrocellulosejumpupdnbdjNo ratings yet
- Knowing Annelida: Earthworms, Leeches and Marine WormsDocument4 pagesKnowing Annelida: Earthworms, Leeches and Marine WormsCherry Mae AdlawonNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Lect 17 Amp Freq RespDocument22 pagesLect 17 Amp Freq RespBent777No ratings yet
- Speech for pecha kuchaDocument6 pagesSpeech for pecha kuchaaira mikaela ruazolNo ratings yet
- Symbols For Signalling Circuit DiagramsDocument27 pagesSymbols For Signalling Circuit DiagramsrobievNo ratings yet
- Ericsson Microwave Outlook 2021Document16 pagesEricsson Microwave Outlook 2021Ahmed HussainNo ratings yet
- 6b530300 04f6 40b9 989e Fd39aaa6293aDocument1 page6b530300 04f6 40b9 989e Fd39aaa6293attariq_jjavedNo ratings yet
- Cricothyroidotomy and Needle CricothyrotomyDocument10 pagesCricothyroidotomy and Needle CricothyrotomykityamuwesiNo ratings yet
- Schaeffler - Account Insights - Mar 2020Document13 pagesSchaeffler - Account Insights - Mar 2020mohit negiNo ratings yet
- Myths of Greece and Rome PDFDocument247 pagesMyths of Greece and Rome PDFratheesh1981No ratings yet
- Enviroclean 25 LTRDocument1 pageEnviroclean 25 LTRMaziyarNo ratings yet
- Cars Ger Eu PCDocument157 pagesCars Ger Eu PCsergeyNo ratings yet
- Lab Manual Cape Bio Unit 1 2023Document37 pagesLab Manual Cape Bio Unit 1 2023drug123addict25No ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Request Letter Group 7Document1 pageRequest Letter Group 7Brent PatarasNo ratings yet
- GSM Modernization Poster2Document1 pageGSM Modernization Poster2leonardomarinNo ratings yet
- Advanced Composite Materials Design EngineeringDocument19 pagesAdvanced Composite Materials Design EngineeringpanyamnrNo ratings yet
- 2021 - Tet Purchase Behavior Report - INFOCUSDocument15 pages2021 - Tet Purchase Behavior Report - INFOCUSGame AccountNo ratings yet
- Sensor Controlled Animatronic Hand: Graduation Project PresentationDocument24 pagesSensor Controlled Animatronic Hand: Graduation Project PresentationAnonymous D2FmKSxuuNo ratings yet
- Aubrey Debut ScriptDocument5 pagesAubrey Debut ScriptKevin Jones CalumpangNo ratings yet
- DerbyCityCouncil Wizquiz Presentation PDFDocument123 pagesDerbyCityCouncil Wizquiz Presentation PDFShubham NamdevNo ratings yet
- 841 Specific GravityDocument1 page841 Specific GravityJam SkyNo ratings yet
- Uji Deteksi Biofilm Dari Isolat Klinik Kateter Urin Bakteri Entercoccus Dibandingkan Dengan Tube MethodDocument27 pagesUji Deteksi Biofilm Dari Isolat Klinik Kateter Urin Bakteri Entercoccus Dibandingkan Dengan Tube MethodIyannyanNo ratings yet
- Palm Wine SpecificationDocument10 pagesPalm Wine SpecificationUday ChaudhariNo ratings yet
- Synopsis - AVR Based Realtime Online Scada With Smart Electrical Grid Automation Using Ethernet 2016Document19 pagesSynopsis - AVR Based Realtime Online Scada With Smart Electrical Grid Automation Using Ethernet 2016AmAnDeepSinghNo ratings yet
- Abundance BlocksDocument1 pageAbundance BlockssunnyNo ratings yet
- DCI-2 Brief Spec-Rev01Document1 pageDCI-2 Brief Spec-Rev01jack allenNo ratings yet
- Downstream Processing and Bioseparation - Recovery and Purification of Biological Products PDFDocument313 pagesDownstream Processing and Bioseparation - Recovery and Purification of Biological Products PDFgonbio67% (3)
- Chip War: The Fight for the World's Most Critical TechnologyFrom EverandChip War: The Fight for the World's Most Critical TechnologyRating: 4.5 out of 5 stars4.5/5 (82)
- CompTIA A+ Complete Review Guide: Exam Core 1 220-1001 and Exam Core 2 220-1002From EverandCompTIA A+ Complete Review Guide: Exam Core 1 220-1001 and Exam Core 2 220-1002Rating: 5 out of 5 stars5/5 (1)
- Hacking With Linux 2020:A Complete Beginners Guide to the World of Hacking Using Linux - Explore the Methods and Tools of Ethical Hacking with LinuxFrom EverandHacking With Linux 2020:A Complete Beginners Guide to the World of Hacking Using Linux - Explore the Methods and Tools of Ethical Hacking with LinuxNo ratings yet
- 8051 Microcontroller: An Applications Based IntroductionFrom Everand8051 Microcontroller: An Applications Based IntroductionRating: 5 out of 5 stars5/5 (6)