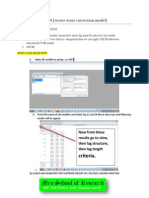
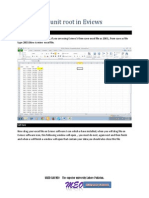
You might also like
- VECMDocument9 pagesVECMsaeed meo100% (3)
- Improve ARDLDocument7 pagesImprove ARDLsaeed meo100% (5)
- ARDL Eviews9 David GilesDocument35 pagesARDL Eviews9 David GilesYasar Yasarlar100% (1)
- Johanson Cointegration Test and ECMDocument7 pagesJohanson Cointegration Test and ECMsaeed meo100% (6)
- ARDL Models-Bounds TestingDocument17 pagesARDL Models-Bounds Testingmzariab88% (8)
- Panel ARDLDocument23 pagesPanel ARDLShuchi Goel100% (1)
- Dynamic Panel Data ModelsDocument20 pagesDynamic Panel Data Modelszaheer khanNo ratings yet
- Panel DataDocument5 pagesPanel Datasaeed meo100% (2)
- GMM Stata Implementation ESS 2017Document33 pagesGMM Stata Implementation ESS 2017Assan AchibatNo ratings yet
- Stata Step by StepDocument47 pagesStata Step by StepDaniel MirandaNo ratings yet
- How to apply panel ARDL using EVIEWS and StataDocument3 pagesHow to apply panel ARDL using EVIEWS and StatazamirNo ratings yet
- ARDL Used in EconometricsDocument6 pagesARDL Used in EconometricsBaber AminNo ratings yet
- Panel Data AssignmentDocument32 pagesPanel Data AssignmentFatima ZehraNo ratings yet
- Panel Data Analysis Sunita AroraDocument28 pagesPanel Data Analysis Sunita Aroralukgv,h100% (1)
- Panel ARDL Second Generation TechniqueDocument2 pagesPanel ARDL Second Generation TechniqueAhmed RagabNo ratings yet
- ARDLDocument10 pagesARDLAdnan SethiNo ratings yet
- Panel Data AnalysisDocument8 pagesPanel Data AnalysisAditya Kumar SinghNo ratings yet
- The Practice of Econometrics Analysis Using EViews Software: Unit Root, Cointegration and Causality Tests (39Document25 pagesThe Practice of Econometrics Analysis Using EViews Software: Unit Root, Cointegration and Causality Tests (39Min Fong LawNo ratings yet
- Panel Data AssignDocument19 pagesPanel Data AssignSyeda Sehrish KiranNo ratings yet
- Econometrics PPT Final Review SlidesDocument41 pagesEconometrics PPT Final Review SlidesIsabelleDwightNo ratings yet
- Xbond2-Dynamic Panel Data EstimatorsDocument50 pagesXbond2-Dynamic Panel Data Estimatorszvika.de100% (1)
- How To Apply Panel ARDL Using EVIEWSDocument4 pagesHow To Apply Panel ARDL Using EVIEWSecobalas7100% (3)
- Panel Data Models Stata Program and Output PDFDocument8 pagesPanel Data Models Stata Program and Output PDFcrinix7265No ratings yet
- FMOLS ModelDocument8 pagesFMOLS Modelsaeed meoNo ratings yet
- Modeling Panel Data EffectsDocument13 pagesModeling Panel Data EffectsAzime Hassen100% (1)
- Panel Data Lecture NotesDocument38 pagesPanel Data Lecture NotesSanam KhanNo ratings yet
- Panel Data Eviews 7 Users Guide IIDocument142 pagesPanel Data Eviews 7 Users Guide IIbaagpankajNo ratings yet
- Panel Data Analysis Using Stata: Sebastian T. Braun University of ST AndrewsDocument90 pagesPanel Data Analysis Using Stata: Sebastian T. Braun University of ST AndrewsKim YongsukNo ratings yet
- Chapter 4 Solutions Solution Manual Introductory Econometrics For FinanceDocument5 pagesChapter 4 Solutions Solution Manual Introductory Econometrics For FinanceNazim Uddin MahmudNo ratings yet
- Panel Data Econometrics KenyaDocument114 pagesPanel Data Econometrics KenyadessietarkoNo ratings yet
- IV Estimation PDFDocument59 pagesIV Estimation PDFduytueNo ratings yet
- Ardl ModelDocument20 pagesArdl ModelMuhammad Nabeel SafdarNo ratings yet
- Nonlinear ARDL Model ManualDocument18 pagesNonlinear ARDL Model ManualDumegã KokutseNo ratings yet
- Ejercicois EviewsDocument10 pagesEjercicois EviewsJuan Meza100% (1)
- Econometrics IIDocument101 pagesEconometrics IIDENEKEW LESEMI100% (1)
- Panel Vs Pooled DataDocument9 pagesPanel Vs Pooled DataFesboekii FesboekiNo ratings yet
- Econ 212: Using Stata To Estimate VAR and Stractural VAR ModelsDocument17 pagesEcon 212: Using Stata To Estimate VAR and Stractural VAR ModelsBrian T. Kim100% (1)
- GMM estimation in Stata 11 for generalized method of moments modelsDocument27 pagesGMM estimation in Stata 11 for generalized method of moments modelsMao CardenasNo ratings yet
- AEconometricAnalysisofQualitativeVariablesDocument21 pagesAEconometricAnalysisofQualitativeVariablesClaudio AballayNo ratings yet
- Time Series AnalysisDocument3 pagesTime Series AnalysisKamil Mehdi AbbasNo ratings yet
- Appliedeconometrics PDFDocument286 pagesAppliedeconometrics PDFMajid AliNo ratings yet
- Lecture 7 VARDocument34 pagesLecture 7 VAREason SaintNo ratings yet
- How to Run Panel Data Analysis Using STATADocument21 pagesHow to Run Panel Data Analysis Using STATADian HendrawanNo ratings yet
- Econometric S Lecture 43Document36 pagesEconometric S Lecture 43Khurram AzizNo ratings yet
- Structural VAR and Applications: Jean-Paul RenneDocument55 pagesStructural VAR and Applications: Jean-Paul RennerunawayyyNo ratings yet
- Econometrics Beat - Dave Giles' Blog - ARDL Modelling in EViews 9Document26 pagesEconometrics Beat - Dave Giles' Blog - ARDL Modelling in EViews 9Hari VenkateshNo ratings yet
- Forecasting AR model with 12 lagsDocument56 pagesForecasting AR model with 12 lagsShashwat DesaiNo ratings yet
- Econometrics Solutions for Finance PanelsDocument4 pagesEconometrics Solutions for Finance PanelsNazim Uddin MahmudNo ratings yet
- Introduction To Econometrics James Stock Watson 2e Part2Document58 pagesIntroduction To Econometrics James Stock Watson 2e Part2grvkpr100% (4)
- DSGE AfricaDocument13 pagesDSGE AfricaWalaa Mahrous100% (1)
- Time Series With EViews PDFDocument37 pagesTime Series With EViews PDFashishankurNo ratings yet
- Stata Guide PDFDocument181 pagesStata Guide PDFNNo ratings yet
- Time Series Analysis and ARDL Modeling in StataDocument26 pagesTime Series Analysis and ARDL Modeling in StataSayed Farrukh AhmedNo ratings yet
- Estng Annotations, Groups & OndependsDocument6 pagesEstng Annotations, Groups & OndependsJoseph WanjekecheNo ratings yet
- Statistical Software Certification: 1, Number 1, Pp. 29-50Document22 pagesStatistical Software Certification: 1, Number 1, Pp. 29-50huat huatNo ratings yet
- Project0 TestingDocument4 pagesProject0 TestingsdfkdnbvbrNo ratings yet
- Cakephp TestDocument22 pagesCakephp Testhathanh13No ratings yet
- CodeReviewChecklist BestPracticesDocument5 pagesCodeReviewChecklist BestPracticesPRABHU SORTURNo ratings yet
- AE and Pplcode TracingDocument4 pagesAE and Pplcode TracingprimusdNo ratings yet
- Advanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandAdvanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Formatting of ThesisDocument42 pagesFormatting of Thesissaeed meo100% (1)
- Best Paper To Learn About ArdlDocument27 pagesBest Paper To Learn About Ardlsaeed meo100% (7)
- Panel DataDocument5 pagesPanel Datasaeed meo100% (2)
- How To Arrange Panel Data For Eviews Into MSDocument2 pagesHow To Arrange Panel Data For Eviews Into MSsaeed meoNo ratings yet
- Importing Data Into R.Document3 pagesImporting Data Into R.saeed meoNo ratings yet
- Mediation If We Have More Then One Mediating VariableDocument39 pagesMediation If We Have More Then One Mediating Variablesaeed meo100% (3)
- Specific Facinating Words For Literature ReviewDocument1 pageSpecific Facinating Words For Literature Reviewsaeed meo100% (1)
- VAR, VECM, Impulse Response TheoryDocument12 pagesVAR, VECM, Impulse Response Theorysaeed meo100% (4)
- MediationDocument5 pagesMediationsaeed meo100% (1)
- Cronbach's AlphaDocument5 pagesCronbach's Alphasaeed meoNo ratings yet
- Granger CusalityDocument4 pagesGranger Cusalitysaeed meoNo ratings yet
- List of Impact Factor JournalsDocument3 pagesList of Impact Factor Journalssaeed meoNo ratings yet
- Business Research MathodDocument95 pagesBusiness Research Mathodsaeed meo100% (2)
- DW Values TableDocument8 pagesDW Values Tablesaeed meoNo ratings yet
- Quantative TechniqesDocument155 pagesQuantative Techniqessaeed meo100% (2)
- FMOLS ModelDocument8 pagesFMOLS Modelsaeed meoNo ratings yet
- Traditional Granger Causality (1969 1972) VS Toda and Yamamoto (1995)Document9 pagesTraditional Granger Causality (1969 1972) VS Toda and Yamamoto (1995)saeed meo100% (6)
- Unit Root Using EviewDocument9 pagesUnit Root Using Eviewsaeed meo75% (4)
- Regression Results ElementsDocument4 pagesRegression Results Elementssaeed meo100% (1)
- DOLS ModelDocument8 pagesDOLS Modelsaeed meo100% (2)
- Many Way of Serial Correlation CheckingDocument5 pagesMany Way of Serial Correlation Checkingsaeed meo100% (2)
- AutocorrelationDocument6 pagesAutocorrelationsaeed meo100% (1)
- Stability Diognostic Through CUSUMDocument8 pagesStability Diognostic Through CUSUMsaeed meo100% (1)
- Primary Data and Secondary Data: Reliability Test?Document15 pagesPrimary Data and Secondary Data: Reliability Test?saeed meo100% (3)
- CV For Teaching SaeedDocument4 pagesCV For Teaching Saeedsaeed meoNo ratings yet
- Selected Problem Solutions from Chapter 8 on Confidence Intervals and Tolerance IntervalsDocument6 pagesSelected Problem Solutions from Chapter 8 on Confidence Intervals and Tolerance IntervalsSergio A. Florez BNo ratings yet
- Regresi GandaDocument33 pagesRegresi GandaekoefendiNo ratings yet
- Chapter 8Document3 pagesChapter 8Mahmudul HasanNo ratings yet
- Contact and Office Hours for STAB27 CourseDocument51 pagesContact and Office Hours for STAB27 CourseBharani DharanNo ratings yet
- Unit 4-B: Multiple RegressionDocument75 pagesUnit 4-B: Multiple RegressionBasma EissaNo ratings yet
- (Wiley Series in Probability and Mathematical Statistics) Vic Barnett, Toby Lewis - Outliers in Statistical Data-John Wiley and Sons (1978) PDFDocument376 pages(Wiley Series in Probability and Mathematical Statistics) Vic Barnett, Toby Lewis - Outliers in Statistical Data-John Wiley and Sons (1978) PDFSiddarth SharrmaNo ratings yet
- Econometrics NotesDocument2 pagesEconometrics NotesDaniel Bogiatzis GibbonsNo ratings yet
- SPSSTutorial Math CrackerDocument43 pagesSPSSTutorial Math CrackerKami4038No ratings yet
- Lecture # 2 (The Classical Linear Regression Model) PDFDocument3 pagesLecture # 2 (The Classical Linear Regression Model) PDFBatool SahabnNo ratings yet
- Session 11 - Multiple Regression Analysis (GbA) PDFDocument119 pagesSession 11 - Multiple Regression Analysis (GbA) PDFkhkarthikNo ratings yet
- 1 SMDocument11 pages1 SMCrush TNo ratings yet
- Skating Speed: A Statistical Approach To ModellingDocument13 pagesSkating Speed: A Statistical Approach To ModellingJason MeehanNo ratings yet
- Datascience 2 PDFDocument24 pagesDatascience 2 PDFVijayan .NNo ratings yet
- Factors Affecting Employee PerformanceDocument12 pagesFactors Affecting Employee PerformanceBayu PutraNo ratings yet
- 6 RegresieDocument6 pages6 RegresieStefan CatalinNo ratings yet
- Lecture10 7012 LogitDocument45 pagesLecture10 7012 LogitPerike Chandra SekharNo ratings yet
- Multiple Linear Regression and Checking For Collinearity Using SASDocument18 pagesMultiple Linear Regression and Checking For Collinearity Using SASRobin0% (1)
- Signed Off Statistics and Probability11 q2 m4 Estimation of Parameters v3Document43 pagesSigned Off Statistics and Probability11 q2 m4 Estimation of Parameters v3Eunice PaulNo ratings yet
- Robust Bayesian AllocationDocument18 pagesRobust Bayesian AllocationKaren PaisleyNo ratings yet
- CH 04Document19 pagesCH 04Eng Eman HannounNo ratings yet
- Simple Linear Regression AnalysisDocument21 pagesSimple Linear Regression AnalysisJoses Jenish SmartNo ratings yet
- Uji Asumsi Klasik Regression: Model SummaryDocument3 pagesUji Asumsi Klasik Regression: Model SummaryLatifah YunifaNo ratings yet
- BIOMETRYcDocument319 pagesBIOMETRYcdawud kuroNo ratings yet
- Qualitative Response Regression QuestionsDocument10 pagesQualitative Response Regression QuestionsnkyaNo ratings yet
- Assign REG BbaDocument1 pageAssign REG BbaInoxcent AbdullahNo ratings yet
- Curve Fitting: Instructor: Dr. Aysar Yasin Dep. of Energy and Env. EngineeringDocument18 pagesCurve Fitting: Instructor: Dr. Aysar Yasin Dep. of Energy and Env. EngineeringAmeer AlfuqahaNo ratings yet
- Pengaruh Lingkungan Kerja Dan Stres Kerja Terhadap Work Life Balance Di PT - Pos Indonesia (Persero) BandungDocument7 pagesPengaruh Lingkungan Kerja Dan Stres Kerja Terhadap Work Life Balance Di PT - Pos Indonesia (Persero) Bandungdevana anishaNo ratings yet
- A Review of Weibull Functions in Wind SectorDocument9 pagesA Review of Weibull Functions in Wind SectorRoajs SofNo ratings yet
- Asreml-R Reference Manual: Analysis of Mixed Models For S Language EnvironmentsDocument145 pagesAsreml-R Reference Manual: Analysis of Mixed Models For S Language EnvironmentsRubénNavarroNo ratings yet
- STAT511 SyllabusDocument3 pagesSTAT511 SyllabusSouleymane CoulibalyNo ratings yet