You might also like
- Chi Squared Test For IndependenceDocument2 pagesChi Squared Test For Independenceapi-287708416No ratings yet
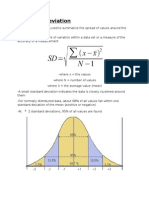
- Standard DeviationDocument2 pagesStandard Deviationapi-287708416No ratings yet
- T TestsDocument2 pagesT Testsapi-287708416No ratings yet
- 2 6 Dna StructureDocument3 pages2 6 Dna Structureapi-287708416No ratings yet
- 1 3 Membrane StructureDocument6 pages1 3 Membrane Structureapi-287708416No ratings yet
- Statistical AnalysisDocument2 pagesStatistical Analysisapi-287708416No ratings yet
- 2 4 ProteinsDocument5 pages2 4 Proteinsapi-287708416No ratings yet
- 2 5 EnzymesDocument8 pages2 5 Enzymesapi-287708416No ratings yet
- 2 3 Carbohydrates and LipidsDocument11 pages2 3 Carbohydrates and Lipidsapi-287708416No ratings yet
- 1 4 Membrane TransportDocument5 pages1 4 Membrane Transportapi-287708416No ratings yet
- 1 2 Ultrastructure of CellsDocument4 pages1 2 Ultrastructure of Cellsapi-287708416No ratings yet
- 1 1 Intro To CellsDocument8 pages1 1 Intro To Cellsapi-287708416No ratings yet
- 3 3 MeiosisDocument6 pages3 3 Meiosisapi-287708416No ratings yet
- 2 1 Molecules To MetabolismDocument4 pages2 1 Molecules To Metabolismapi-287708416No ratings yet
- 2 2 WaterDocument6 pages2 2 Waterapi-287708416No ratings yet
- 2 8 Cell RespirationDocument9 pages2 8 Cell Respirationapi-287708416No ratings yet
- 3 4 and 3 5 NotesDocument6 pages3 4 and 3 5 Notesapi-287708416No ratings yet
- 3 4 InheritanceDocument3 pages3 4 Inheritanceapi-287708416No ratings yet
- 2 9 PhotosynthesisDocument12 pages2 9 Photosynthesisapi-287708416No ratings yet
- 3 2 ChromosomesDocument6 pages3 2 Chromosomesapi-287708416No ratings yet
- 3 1 GeneticsDocument4 pages3 1 Geneticsapi-287708416No ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Parle Project Report Presented by Amit Kumar GiriDocument22 pagesParle Project Report Presented by Amit Kumar GiriAmit Kumar Giri100% (14)
- Ficha Tecnica Sonometro Artisan SL2100PSDocument1 pageFicha Tecnica Sonometro Artisan SL2100PSJackson Steward Ríos SastoqueNo ratings yet
- Worksheet - 2 (Gas Laws, Density, Molar Mass)Document4 pagesWorksheet - 2 (Gas Laws, Density, Molar Mass)Jose Ruben SortoNo ratings yet
- A Qualitative Phenomenological Exploration of Teachers Experience With Nutrition EducationDocument14 pagesA Qualitative Phenomenological Exploration of Teachers Experience With Nutrition EducationDelfin ValdezNo ratings yet
- Homemade Litmus Paper ExperimentDocument3 pagesHomemade Litmus Paper ExperimentEmmanuelle NazarenoNo ratings yet
- IATA 04th Edition Cabin Operations Safety Best Practices GuideDocument260 pagesIATA 04th Edition Cabin Operations Safety Best Practices GuideMakoto Ito100% (1)
- CCUS technologies activities in France: Focus on industriesDocument21 pagesCCUS technologies activities in France: Focus on industriesGaurav MishraNo ratings yet
- Children Education - PPTMONDocument26 pagesChildren Education - PPTMONisna sari kelimagunNo ratings yet
- Radio WavesDocument17 pagesRadio WavesStuart Yong100% (1)
- Specimen - Case - Study - CP1 Paper 2 - 2019 - Final PDFDocument6 pagesSpecimen - Case - Study - CP1 Paper 2 - 2019 - Final PDFking hkhNo ratings yet
- Engineer Course - Plumbing I PDFDocument359 pagesEngineer Course - Plumbing I PDFfanatickakashiNo ratings yet
- Death Certificate: Shaheed Monsur Ali Medical College HospitalDocument3 pagesDeath Certificate: Shaheed Monsur Ali Medical College HospitalBokul80% (5)
- Test - Ans SEAFOOD COOKERY 10Document7 pagesTest - Ans SEAFOOD COOKERY 10EVANGELINE VILLASICANo ratings yet
- Nurse Resume Masters Degree TemplateDocument2 pagesNurse Resume Masters Degree TemplatehenryodomNo ratings yet
- ICAEW Professional Level Business Planning - Taxation Question & Answer Bank March 2016 To March 2020Document382 pagesICAEW Professional Level Business Planning - Taxation Question & Answer Bank March 2016 To March 2020Optimal Management SolutionNo ratings yet
- Apartments in Trivandrum - Flats in Trivandrum - Heather HomesDocument6 pagesApartments in Trivandrum - Flats in Trivandrum - Heather Homescresto indiaNo ratings yet
- Child Development: Resilience & Risk, A Course SyllabusDocument17 pagesChild Development: Resilience & Risk, A Course SyllabusJane GilgunNo ratings yet
- Laboratory Notebook: Aquatic Ecology and ResourcesDocument7 pagesLaboratory Notebook: Aquatic Ecology and ResourcesAireen Diamsim MaltoNo ratings yet
- Myth and Folklo-WPS OfficeDocument211 pagesMyth and Folklo-WPS OfficeAryan A100% (1)
- Crude Palm Oil MSDS Provides Safety InformationDocument3 pagesCrude Palm Oil MSDS Provides Safety InformationCarlos MontanoNo ratings yet
- ASTM Liquid-in-Glass Thermometers: Standard Specification ForDocument64 pagesASTM Liquid-in-Glass Thermometers: Standard Specification ForAnonh AdikoNo ratings yet
- Nutritional Assessment Form of ChildrenDocument6 pagesNutritional Assessment Form of ChildrenBisakha Dey100% (2)
- Sisal FiberDocument20 pagesSisal FiberFahad juttNo ratings yet
- Narcos 1x01 - DescensoDocument53 pagesNarcos 1x01 - DescensoBirdy NumnumsNo ratings yet
- Life Skills Unit PlanDocument15 pagesLife Skills Unit PlanLindy McBratneyNo ratings yet
- TRILOGY Product BrochureDocument8 pagesTRILOGY Product BrochureMarina JankovicNo ratings yet
- ARSA 2010 International Conference Proceeding - Volume IIDocument540 pagesARSA 2010 International Conference Proceeding - Volume IICholnapa AnukulNo ratings yet
- Vote of Thanx For Grandparents Day at SchoolDocument1 pageVote of Thanx For Grandparents Day at SchoolkoolsurdieNo ratings yet
- Lab Manual - General Chemistry (Spring 2019)Document83 pagesLab Manual - General Chemistry (Spring 2019)jinri sandeulNo ratings yet
- Salary Slip: Special AllowancesDocument2 pagesSalary Slip: Special AllowancesVikas KumarNo ratings yet