
You might also like
- Penerapan Data Mining Yang Telah Dikemas Menjadi Produk Perangkat Lunak.Document3 pagesPenerapan Data Mining Yang Telah Dikemas Menjadi Produk Perangkat Lunak.AdityoDwiRahmawanNo ratings yet
- Manual Book Website InformasiDocument14 pagesManual Book Website InformasiRidho NastainullahNo ratings yet
- INKSCAPE ACTIVITY 3Document3 pagesINKSCAPE ACTIVITY 3Roxandra VelouetteNo ratings yet
- Sistem Penjualan Buku Berbasis Web Ditoko JavamediaDocument40 pagesSistem Penjualan Buku Berbasis Web Ditoko JavamediaAril_Setiawan_915100% (1)
- Proposal Tugas Akhir Implementasi Dan Analisis Software Performance Testing Pada Toko Online Menggunakan Cloud Based Testing ToolsDocument24 pagesProposal Tugas Akhir Implementasi Dan Analisis Software Performance Testing Pada Toko Online Menggunakan Cloud Based Testing ToolsMuhammadNo ratings yet
- SINGKAT SOAL TCP/IP DAN JARINGAN KOMPUTERDocument7 pagesSINGKAT SOAL TCP/IP DAN JARINGAN KOMPUTERVegi Syam Merkury0% (1)
- SOAL UAS TA 2019-2020 GENAP Data ScienceDocument2 pagesSOAL UAS TA 2019-2020 GENAP Data ScienceRani Safitamah100% (1)
- Soal UTS RPL Ganjil 2017 Sore (Firdaus Sahlan)Document4 pagesSoal UTS RPL Ganjil 2017 Sore (Firdaus Sahlan)Putri Indah Lestari75% (4)
- Makalah Manjaro LinuxDocument27 pagesMakalah Manjaro LinuxSonyaLegis100% (1)
- SQLyog DatabaseDocument27 pagesSQLyog DatabaseRomzahNo ratings yet
- Basisdata 8Document2 pagesBasisdata 8nani nanaNo ratings yet
- Review Jurnal OlapDocument2 pagesReview Jurnal OlapLankzz Fiver'zNo ratings yet
- Big Data ReviewDocument18 pagesBig Data ReviewAl-Umam ScarletNo ratings yet
- Analisis Go-RideDocument9 pagesAnalisis Go-RideJohan ArifinNo ratings yet
- Act2 Reynaldi 55417047Document2 pagesAct2 Reynaldi 55417047rafly0% (1)
- Proposal Riset Teknologi InformasiDocument12 pagesProposal Riset Teknologi InformasiWahyu Harimas Anstura100% (1)
- Sistem Testing PengertianDocument19 pagesSistem Testing PengertianSendy ArdiantoNo ratings yet
- Analisis IMK Pada Website TokopediaDocument9 pagesAnalisis IMK Pada Website TokopediaRaudya JanuaritaNo ratings yet
- Makalah Ecommerce Tentang Keamanan EcommerceDocument20 pagesMakalah Ecommerce Tentang Keamanan EcommercePrincess Santianha Dilvierra Axella-azhurra75% (4)
- Laporan Tubes Alpro 2 - Aplikasi Toko BukuDocument14 pagesLaporan Tubes Alpro 2 - Aplikasi Toko BukuDani Ramadani100% (1)
- Saumibookreview: Strategi Periklanan E CommerceDocument12 pagesSaumibookreview: Strategi Periklanan E CommerceSaomi Rizqiyanto100% (2)
- Ragam Dialog IMK 5Document53 pagesRagam Dialog IMK 5Rahmat DaniNo ratings yet
- Tugas Review JurnalDocument2 pagesTugas Review JurnalAgam AzharaNo ratings yet
- Review Jurnal IT GovernanceDocument11 pagesReview Jurnal IT GovernanceYudi Farizan RahmanNo ratings yet
- Activiti Diagram Rental MobilDocument4 pagesActiviti Diagram Rental MobilAfdhal MuhammadNo ratings yet
- Tugas 3 Sistem Pakar - 0021Document3 pagesTugas 3 Sistem Pakar - 0021arya wishnu100% (4)
- Berikut 100 Ide Judul Skripsi Teknik Informatika Dan Sistem Informasi Semga BermanfaatDocument4 pagesBerikut 100 Ide Judul Skripsi Teknik Informatika Dan Sistem Informasi Semga BermanfaatAdith Aulia RahmanNo ratings yet
- Review Jurnal Tata Kelola Sistem InformasiDocument3 pagesReview Jurnal Tata Kelola Sistem InformasiZuhraNo ratings yet
- KKP ANALISA SISTEM PENJUALAN BARANGDocument33 pagesKKP ANALISA SISTEM PENJUALAN BARANGari nabawi91% (11)
- Contoh Requirement DocumentDocument4 pagesContoh Requirement DocumentDwyasa100% (1)
- Rekayasa Perangkat Lunak 1 System RequestDocument16 pagesRekayasa Perangkat Lunak 1 System RequestBagus S0% (1)
- 4 Soal Kasus RPL 2Document3 pages4 Soal Kasus RPL 2Elsa Naracristy33% (3)
- Soal Uas Basis Data 3Document2 pagesSoal Uas Basis Data 3Mohammad Rizqy PNo ratings yet
- METODE TOPSISDocument22 pagesMETODE TOPSISHanif Fadhilah100% (1)
- Perancangan Sistem Informasi Penjualan Batik Berbasis WebDocument17 pagesPerancangan Sistem Informasi Penjualan Batik Berbasis Webfpa_faiz1350% (2)
- (A11.2019.11756) Tabel Kelebihan Dan Kelemahan Manusia Dan KomputerDocument2 pages(A11.2019.11756) Tabel Kelebihan Dan Kelemahan Manusia Dan KomputerDesi RezaNo ratings yet
- RANCANG SISTEM INFORMASI RENTAL BUSDocument12 pagesRANCANG SISTEM INFORMASI RENTAL BUSRiki TobingNo ratings yet
- PROPOSALDocument11 pagesPROPOSALYuniar SamsianaNo ratings yet
- Komputer Dan MasyarakatDocument11 pagesKomputer Dan MasyarakatBalqis Syifa AzzahraNo ratings yet
- Teknik Learning Pada Artificial IntelligenceDocument37 pagesTeknik Learning Pada Artificial IntelligenceFebby Febriana100% (3)
- UAS_RLSDocument2 pagesUAS_RLSMhd Satria0% (1)
- Makalah Help Dan DokumentasiDocument15 pagesMakalah Help Dan Dokumentasiyayan ben ismailNo ratings yet
- Manual Book Mataku Imk Rudi Gigih Prabowo 56415293 3ia14Document20 pagesManual Book Mataku Imk Rudi Gigih Prabowo 56415293 3ia14RudiGigihPNo ratings yet
- Analisa Perancangan Sistem Informasi ApotekDocument18 pagesAnalisa Perancangan Sistem Informasi ApotekRizal MuttaqinNo ratings yet
- Tugas Review Jurnal SPKDocument14 pagesTugas Review Jurnal SPKyyk motovlogNo ratings yet
- ERD-MembuatDocument86 pagesERD-MembuatAngel Grace RiyadiNo ratings yet
- Naive BayesDocument9 pagesNaive BayesDyah PujiNo ratings yet
- Perkembangan Sistem Operasi Dari Tahun 2000 Hingga 2016Document42 pagesPerkembangan Sistem Operasi Dari Tahun 2000 Hingga 2016Ez' Zhofie KillEr-InshIde75% (4)
- Studi Kasus 1Document3 pagesStudi Kasus 1Anonymous FjE9LkUpCqNo ratings yet
- Contoh Studi Kasus Tugas Uas Audit Cobit 4.1 PDFDocument60 pagesContoh Studi Kasus Tugas Uas Audit Cobit 4.1 PDFfauzi ikhwanul ihsanNo ratings yet
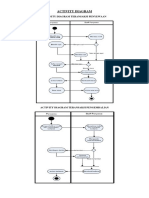
- UML] Pengertian dan Jenis-jenis Diagram UMLDocument10 pagesUML] Pengertian dan Jenis-jenis Diagram UMLHerdies AdimartaNo ratings yet
- Algoritma Greedy untuk Penukaran Uang RupiahDocument2 pagesAlgoritma Greedy untuk Penukaran Uang Rupiahvicky fahrulNo ratings yet
- Nessus Adalah Scanner Keamanan Jaringan Yang Harus Digunakan Oleh Administrator SystemDocument17 pagesNessus Adalah Scanner Keamanan Jaringan Yang Harus Digunakan Oleh Administrator SystemBayu Agung Pranata0% (1)
- Aplikasi Penyewaan Pemesanan Rental Mobil Berbasis Android Menggunakan JavaDocument5 pagesAplikasi Penyewaan Pemesanan Rental Mobil Berbasis Android Menggunakan JavaAndri Nesus0% (1)
- NAIFBAYESDocument24 pagesNAIFBAYESNando ApriNo ratings yet
- ANALISIS_IRISDocument15 pagesANALISIS_IRISPaulina Ade Cahyanti100% (1)
- TOKO MINUMANDocument9 pagesTOKO MINUMANBayu Permana PutraNo ratings yet
- Mean, Median, ModusDocument6 pagesMean, Median, ModusShihabul Milah IbrahimNo ratings yet
- BJT - Umum - tugas1-ESPA4213 Statistika EkonomiDocument5 pagesBJT - Umum - tugas1-ESPA4213 Statistika EkonomiDedy AstinaNo ratings yet
- Firman Kasih HuluDocument6 pagesFirman Kasih HuluBudi budiNo ratings yet

















































![UML] Pengertian dan Jenis-jenis Diagram UML](https://imgv2-2-f.scribdassets.com/img/document/269462288/149x198/d858ff671d/1545417025?v=1)








