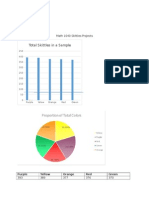
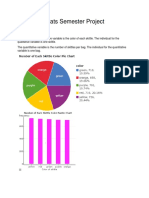
You might also like
- Skittles Project 1Document7 pagesSkittles Project 1api-299868669100% (2)
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240No ratings yet
- Skittles 2 FinalDocument12 pagesSkittles 2 Finalapi-242194552No ratings yet
- Final ProjectDocument9 pagesFinal Projectapi-262329757No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849No ratings yet
- Comprehensive Skittles Project Math 1040Document7 pagesComprehensive Skittles Project Math 1040api-316732019No ratings yet
- SkittleDocument6 pagesSkittleapi-378470372No ratings yet
- Term Project Part 8Document9 pagesTerm Project Part 8api-242224172No ratings yet
- Skittles ProjectDocument4 pagesSkittles Projectapi-495044582No ratings yet
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396No ratings yet
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685No ratings yet
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085No ratings yet
- Stats Project FinalDocument10 pagesStats Project Finalapi-316977780No ratings yet
- Skittles Project FinalDocument8 pagesSkittles Project Finalapi-548638974No ratings yet
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081No ratings yet
- Pie Chart For The ProjectDocument7 pagesPie Chart For The Projectapi-325968264No ratings yet
- Full Skittles ProjectDocument13 pagesFull Skittles Projectapi-537189505No ratings yet
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278No ratings yet
- Stats StuffDocument7 pagesStats Stuffapi-242298926No ratings yet
- Skittle Project FinalDocument6 pagesSkittle Project Finalapi-252859182No ratings yet
- Skittles Project Math 1040Document8 pagesSkittles Project Math 1040api-495044194No ratings yet
- Final ProjectDocument3 pagesFinal Projectapi-265661554No ratings yet
- Skittles ProjectDocument4 pagesSkittles Projectapi-287735026No ratings yet
- Math Skittles ProjectDocument4 pagesMath Skittles Projectapi-495044344No ratings yet
- Skittles Term Project 11 9 14Document5 pagesSkittles Term Project 11 9 14api-192489685No ratings yet
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765No ratings yet
- Statistics Project 17Document13 pagesStatistics Project 17api-271978152No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849No ratings yet
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872No ratings yet
- Madelyn SonntagDocument2 pagesMadelyn Sonntagapi-320330001No ratings yet
- Skittles Project 5-02Document8 pagesSkittles Project 5-02api-354040698No ratings yet
- Math 1040Document3 pagesMath 1040api-219553415No ratings yet
- Stats Semester ProjectDocument11 pagesStats Semester Projectapi-276989071No ratings yet
- Skittles ProjectDocument6 pagesSkittles Projectapi-495018964No ratings yet
- Final Stats ProjectDocument8 pagesFinal Stats Projectapi-238717717100% (2)
- The Rainbow ReportDocument11 pagesThe Rainbow Reportapi-316991888No ratings yet
- Skittles ReportDocument15 pagesSkittles Reportapi-271901299No ratings yet
- Math ProfileDocument9 pagesMath Profileapi-454376679No ratings yet
- Emily Gregorio Skittles Project FinalDocument3 pagesEmily Gregorio Skittles Project Finalapi-288933258No ratings yet
- Skittles ProjectDocument17 pagesSkittles Projectapi-359548770No ratings yet
- Skittles Project Group Final WordDocument6 pagesSkittles Project Group Final Wordapi-316239273No ratings yet
- Skittles FinalDocument12 pagesSkittles Finalapi-241861434No ratings yet
- Math 1040 Skittles Term ProjectDocument10 pagesMath 1040 Skittles Term Projectapi-310671451No ratings yet
- Eportfolio Skittle ProjectDocument9 pagesEportfolio Skittle Projectapi-581790180No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-271444168No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-441660843No ratings yet
- Skittles Project 2Document10 pagesSkittles Project 2api-316655135No ratings yet
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832No ratings yet
- SkittlesDocument7 pagesSkittlesapi-244615173No ratings yet
- Skittles ProjectDocument4 pagesSkittles Projectapi-299945887No ratings yet
- Skittles Term Project 1-6Document10 pagesSkittles Term Project 1-6api-284733808No ratings yet
- Skittles Project FinalDocument5 pagesSkittles Project Finalapi-271348941No ratings yet
- Statistics Final Project Summer Semester 2016Document17 pagesStatistics Final Project Summer Semester 2016api-295161880No ratings yet
- Kassem Hajj: Math 1040 Skittles Term ProjectDocument10 pagesKassem Hajj: Math 1040 Skittles Term Projectapi-240347922No ratings yet
- Math 1040Document5 pagesMath 1040api-534403229No ratings yet
- Part 2Document2 pagesPart 2api-315855737No ratings yet
- Skittles Project With ReflectionDocument7 pagesSkittles Project With Reflectionapi-234712126100% (1)
- Final Math ProjectDocument7 pagesFinal Math Projectapi-316775963No ratings yet
- The Psychomotor Profile of Pupils in Early Childhood EducationDocument11 pagesThe Psychomotor Profile of Pupils in Early Childhood EducationLEINHARTNo ratings yet
- Ramin Shamshiri Risk Analysis Exam2 PDFDocument8 pagesRamin Shamshiri Risk Analysis Exam2 PDFRedmond R. ShamshiriNo ratings yet
- Diplomatic Quarter New Marriott Hotel & Executive ApartmentsDocument1 pageDiplomatic Quarter New Marriott Hotel & Executive Apartmentsconsultnadeem70No ratings yet
- Satya Prakash Tucker Chief Secretary To GovernmentDocument1 pageSatya Prakash Tucker Chief Secretary To Governmentmass1984No ratings yet
- Art of Data ScienceDocument159 pagesArt of Data Sciencepratikshr192% (12)
- 3.1 Learning To Be A Better StudentDocument27 pages3.1 Learning To Be A Better StudentApufwplggl JomlbjhfNo ratings yet
- NCLEX 20QUESTIONS 20safety 20and 20infection 20controlDocument8 pagesNCLEX 20QUESTIONS 20safety 20and 20infection 20controlCassey MillanNo ratings yet
- Eco - Module 1 - Unit 3Document8 pagesEco - Module 1 - Unit 3Kartik PuranikNo ratings yet
- Barclays Global FX Quarterly Fed On Hold Eyes On GrowthDocument42 pagesBarclays Global FX Quarterly Fed On Hold Eyes On GrowthgneymanNo ratings yet
- A Week in My CountryDocument2 pagesA Week in My CountryAQhuewulland Youngprincess HokageNarutoNo ratings yet
- 7 Critical Reading StrategiesDocument1 page7 Critical Reading StrategiesWilliam Holt100% (2)
- Form Aplikasi CCAI GTP 2011Document5 pagesForm Aplikasi CCAI GTP 2011Tomo SiagianNo ratings yet
- MathTextbooks9 12Document64 pagesMathTextbooks9 12Andrew0% (1)
- RARC Letter To Tan Seri Razali Ismail July 26-2013Document4 pagesRARC Letter To Tan Seri Razali Ismail July 26-2013Rohingya VisionNo ratings yet
- Post-Stroke Rehabilitation: Kazan State Medical UniversityDocument11 pagesPost-Stroke Rehabilitation: Kazan State Medical UniversityAigulNo ratings yet
- Imam Muhammad Baqir (As) BioDocument5 pagesImam Muhammad Baqir (As) BioFatema AbbasNo ratings yet
- Holland Party GameFINAL1 PDFDocument6 pagesHolland Party GameFINAL1 PDFAnonymous pHooz5aH6VNo ratings yet
- Photosynthesis 9700 CieDocument8 pagesPhotosynthesis 9700 CietrinhcloverNo ratings yet
- World Bank Case StudyDocument60 pagesWorld Bank Case StudyYash DhanukaNo ratings yet
- Dollar Unit SamplingDocument7 pagesDollar Unit SamplingAndriatsirihasinaNo ratings yet
- Cheat SheetDocument2 pagesCheat SheetFrancis TanNo ratings yet
- Apr 00Document32 pagesApr 00nanda2006bNo ratings yet
- Chemistry Chapter SummariesDocument23 pagesChemistry Chapter SummariesHayley AndersonNo ratings yet
- Kierkegaard, S - Three Discourses On Imagined Occasions (Augsburg, 1941) PDFDocument129 pagesKierkegaard, S - Three Discourses On Imagined Occasions (Augsburg, 1941) PDFtsuphrawstyNo ratings yet
- Presentation of Times of India Newspaper SIPDocument38 pagesPresentation of Times of India Newspaper SIPPrakruti ThakkarNo ratings yet
- Superscope, Inc. v. Brookline Corp., Etc., Robert E. Lockwood, 715 F.2d 701, 1st Cir. (1983)Document3 pagesSuperscope, Inc. v. Brookline Corp., Etc., Robert E. Lockwood, 715 F.2d 701, 1st Cir. (1983)Scribd Government DocsNo ratings yet
- Isolasi Dan Karakterisasi Runutan Senyawa Metabolit Sekunder Fraksi Etil Asetat Dari Umbi Binahong Cord F L A Steen S)Document12 pagesIsolasi Dan Karakterisasi Runutan Senyawa Metabolit Sekunder Fraksi Etil Asetat Dari Umbi Binahong Cord F L A Steen S)Fajar ManikNo ratings yet
- Asher - Bacteria, Inc.Document48 pagesAsher - Bacteria, Inc.Iyemhetep100% (1)
- Adjective Clauses: Relative Pronouns & Relative ClausesDocument4 pagesAdjective Clauses: Relative Pronouns & Relative ClausesJaypee MelendezNo ratings yet
- EmTech TG Acad v5 112316Document87 pagesEmTech TG Acad v5 112316Arvin Barrientos Bernesto67% (3)